
手把手教你用LLaMA-Factory微调Qwen3大模型
是时候准备实习和面试了。
不同以往的是,当前职场已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:

喜欢本文记得收藏、关注、点赞。更多实战和面试交流,加入我们
思路: 在服务器上安装LLaMA-Factory环境,然后微调Qwen3-4B大模型
一、环境准备
1)3090显卡的即可(如果本地有GPU机器,请用自己的),选择了PyTorch
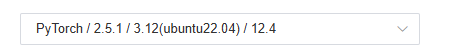
2)安装Anaconda(AutoDL上已默认安装miniconda3)
Anacoda官网:https://www.anaconda.com/
根据你自己的系统下载对应版本
安装完成后,打开终端(Linux/macOS)或Anaconda Prompt(Windows),输入以下命令创建一个新环境:
(AutoDL上需要做以下操作)
conda create -n llama_factory python=3.10 conda activate llama_factory
3)安装Git(AutoDL已安装)
-
Linux:在终端输入:
sudo apt-get install git -
Windows:下载并安装Git for Windows
-
macOS:在终端输入:
brew install git(需先安装Homebrew)
4)安装cuda(AutoDL已安装)
参考: https://help.aliyun.com/zh/egs/user-guide/install-a-gpu-driver-on-a-gpu-accelerated-compute-optimized-linux-instance
二、下载LLaMA-Factory
需要从GitHub下载,使用git命令下载:
git clone https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factory
三、安装依赖
在LLaMA-Factory目录下安装所需的Python包
pip install -e .[metrics]
如果使用GPU,确保安装支持CUDA的PyTorch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
说明: 根据您的CUDA版本调整cu118,如11.7用cu117,如果你使用的是AutoDL,CUDA版本应该是128
四、下载Qwen3-4b大模型
在modelscope社区下载,安装魔搭(modelscope)模块
pip install modelscope
下载模型
mkdir -p /models/modelscope download --model Qwen/Qwen3-4B --local_dir /models/Qwen3-4B
五、准备数据集(alpaca格式)
"my_dataset": { "file_name": "alpaca_zh_demo.json" }
说明:alpaca_zh_demo.json是llama factory内置的一个测试数据集
六、微调前的测试
微调之前可以先加载初始模型做推理测试
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /models/Qwen3-4B \ --template qwen
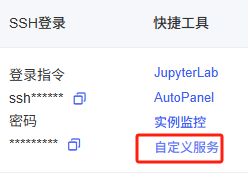
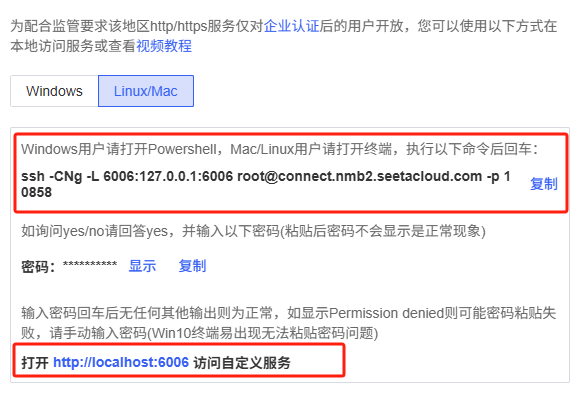
它会监听7860端口,如果使用AutoDL,还需要配置自定义服务:
1)首先要实名认证
2)自定义服务
控制台 --> 容器实例 --> 快捷工具
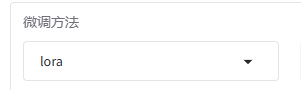
七、启动微调
微调之前,先把之前的llamafactory-cli命令结束掉,然后执行下面命令,将webui打开,监听7860端口:
llamafactory-cli webui
浏览器访问 http://ip:7860, AutoDL需要做自定义服务





八、模型推理与测试
微调后的模型可以用WebUI测试:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /models/Qwen3-4B \ --adapter_name_or_path saves/Qwen3-4B-Instruct/lora/my_finetune \ --template qwen
浏览器访问: http://localhost:7860
如果web方式访问不方便,也可以终端形式:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \ --model_name_or_path /models/Qwen3-4B \ --adapter_name_or_path saves/Qwen3-4B-Instruct/lora/my_finetune \ --template qwen
九、导出模型
如果需要分享模型,导出为Hugging Face格式:
llamafactory-cli export \ --model_name_or_path /models/Qwen3-4B \ --adapter_name_or_path saves/Qwen3-4B-Instruct/lora/my_finetune \ --template qwen \ --finetuning_type lora \ --export_dir /models/Qwen3-4B-Aminglinux

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)