
在 AMD 云平台上微调 Gemma 4 做「AI 梦境日志」,我替你把 ROCm 这些坑踩完了(附完整流程)
话题标签:#AMDev #Datawhale #ROCm #LoRA #Gemma4 #大模型微调

为什么我要写这篇?
过去一周,我在 AMD ROCm 云平台上,用 Jupyter 跑通了一个完整项目:
基于 Gemma 4 E4B-it,LoRA 微调出一个 「AI 梦境日志」 生成器——输入一句中文开头,模型续写一段超现实、梦境般的文字,还带 Gradio Web 界面。
训练能跑完,但中间 Kernel 自动重启、transformers 版本报错、save_pretrained 触发 OOM……每一个坑都足够劝退新手。
正好 Datawhale AI KOC 计划 · ROCm 方向 正在招募「最早把开放算力用起来、又愿意分享的人」。我把完整实录写下来,你照着做能少踩 80% 的坑。
一、Datawhale AI KOC 计划是什么?
AI 正在以极快速度改变工作方式。从「听说过 AI」到「真正用好 AI」,中间差的不只是工具,更是 真实的应用经验。
AI KOC(Key Opinion Consumer)就是这群人:既懂 AI 技能、愿意分享、能带动更多人真正用起来。
Datawhale 作为 AI 开源学习社区,联合 AMD 发起 AI KOC 支持计划 · ROCm 方向:
ROCm = AMD 自主研发 · 开源共建的 GPU 计算软件栈
这一轮专注 开放 GPU 算力生态。AMD 提供 算力、周边及生态资源;Datawhale 提供 流量、社区与成长机会。
💡 一句话:找到并成就那些最早把 ROCm 用起来、又愿意分享的人——成为这条新路线上最早的「点灯人」。

你能获得什么?
| 来自 | 权益 |
|---|---|
|
Datawhale |
流量扶持、社区曝光、学习资源 |
|
AMD |
算力支持、周边、生态资源 |
二、ROCm 是什么?和 CUDA 有什么区别?(一句话版)
很多人第一次上 AMD 云会懵:代码里写的是 torch.cuda,GPU 显示的却是 AMD Radeon?
| CUDA | ROCm | |
|---|---|---|
|
厂商 |
NVIDIA |
AMD |
|
定位 |
闭源 GPU 计算生态 |
开源 GPU 计算软件栈 |
|
PyTorch 调用 |
|
同样用 |
|
生态 |
最成熟 |
快速崛起,越来越多模型可跑 |
⚠️ 重点:在 ROCm 环境下看到
torch.cuda.is_available() == True是正常的,不代表你在用 NVIDIA。
我这次用的设备信息:
device name: AMD Radeon Graphics
torch: 2.9.1+git (ROCm 预装)
transformers: 5.12.1
三、项目介绍:AI 梦境日志
3.1 做什么?
不是做情绪分类、不是做问答,而是:
输入:「深夜的地铁里,坐我对面的人没有脸。」
输出:模型续写一段超现实、梦境感的中文文本。
3.2 技术栈
| 组件 | 选择 | 原因 |
|---|---|---|
|
基座模型 |
魔搭下载,无需 HF Token |
|
|
微调方式 |
LoRA( |
单卡可训 |
|
数据 |
450 条硬编码超现实种子文本 |
无需联网下数据集 |
|
推理 |
高温采样 + 三档梦境强度 |
light / medium / deep |
|
部署 |
Gradio Web 界面 |
一键体验 |
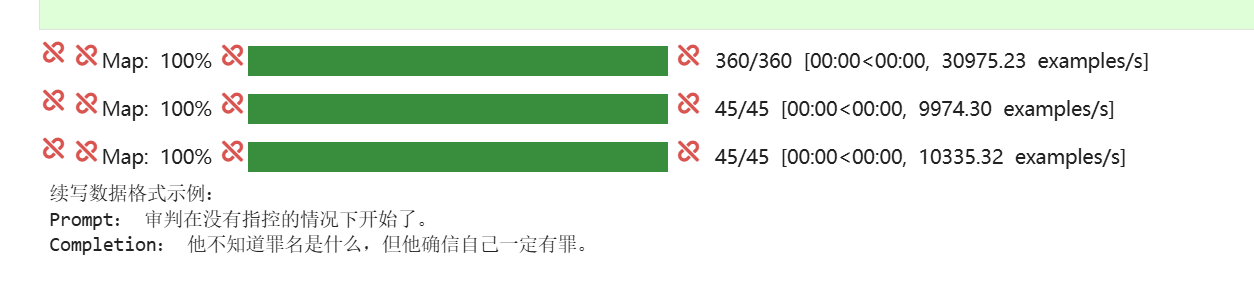
3.3 训练规模(真实数据)
数据集:train 360 / val 45 / test 45
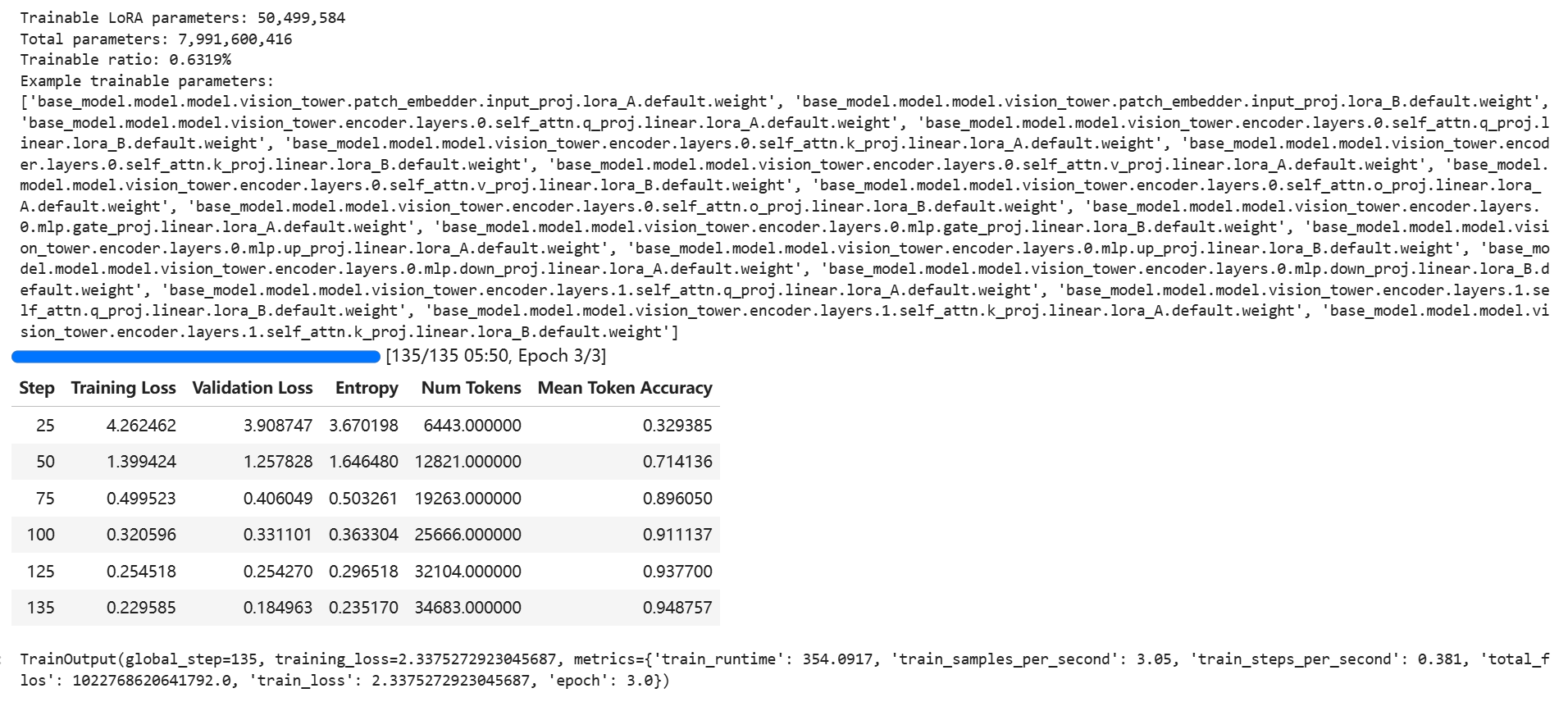
LoRA 可训练参数:50,499,584(约 0.63% 总参数)
训练:3 epoch,135 steps,约 6 分钟
training_loss:2.34
输出目录:./dream_model/
四、AMD 云平台跑通全流程(注册 → 开机 → 第一个模型)
Step 1:环境依赖(别乱装!)
ROCm 云平台通常 预装好 PyTorch。第一件事:不要装 torchvision / vllm,容易破坏现有 torch。
# 正确做法:只装必要包
pip install "transformers>=5.5.0" "huggingface_hub>=1.5.0" \
modelscope accelerate datasets trl peft gradio \
-i https://mirrors.cloud.tencent.com/pypi/simple/
Gemma 4 硬要求:
transformers >= 5.5.0,低于此版本会直接报错。
Step 2:魔搭下载模型(国内友好)
from modelscope import snapshot_download
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"
LOCAL_MODEL_DIR = snapshot_download(MODELSCOPE_MODEL_ID, cache_dir="./models")
首次需在魔搭网页 接受 Gemma 许可协议。
Step 3:加载模型
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained(LOCAL_MODEL_DIR, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=torch.bfloat16,
device_map="auto",
)
Step 4:LoRA 微调
核心配置:
DREAM_DROPOUT = 0.3 # 高 dropout,增强「梦境随机性」
DREAM_TEMPERATURE = 1.2 # 推理高温采样
per_device_train_batch_size = 2
gradient_accumulation_steps = 4
num_train_epochs = 3
save_steps = 25 # 训练过程自动存 checkpoint
Step 5:Gradio 一键体验
# 输入梦境开头 → 选择强度 → 生成续写
demo.launch(server_name="0.0.0.0", share=False)
五、踩坑实录(这篇价值最高的部分)
坑 1:torchvision::nms 导致 transformers 导入失败
现象:
RuntimeError: operator torchvision::nms does not exist
原因:纯文本任务不需要 torchvision,但环境里残留了与 ROCm 版 torch 版本不匹配的 torchvision。
解决:
uv pip uninstall torchvision # 注意:旧版 uv 不要加 -y
pip uninstall -y torchvision
之后 不要再装 torchvision。
坑 2:Gemma 4 必须 transformers 5.5+
现象:
AttributeError: 'list' object has no attribute 'keys'
原因:Gemma 4 是多模态架构,旧版 transformers 无法解析 config。
解决:
pip install "transformers>=5.5.0" "huggingface_hub>=1.5.0"
升级后若已 import 过旧包,需清缓存或 Restart Kernel,再重新 import。
坑 3:训练完保存模型,Kernel 自动重启(最搞心态)
现象:§14 执行 save_pretrained 或跑 §15 评估时,Jupyter 静默重启,trainer 变量全丢。
原因:训练结束后 trainer 仍占用 optimizer 状态(往往是模型权重的 2~3 倍显存),再序列化或批量 generate() 直接 OOM,系统杀进程。
我的解决方案(已在 Notebook 里改好):
-
§13 训练结束立刻:
- 从
checkpoint-*拷贝 adapter(文件复制,不重新序列化) - 保存 tokenizer
del trainer释放显存
- 从
-
§14 改为可选:只做磁盘检查,零 GPU 操作
-
§15 评估降载:
EVAL_LIMIT = 5 # 先评 5 条,稳定后再改 30
EVAL_MAX_TOKENS = 128 # 缩短生成长度
- Kernel 已重启? 不必重训:
§1 → §2 → §7 → §8 → §9 → §15
从 ./dream_model/checkpoint-* 自动加载 LoRA。
💡 教训:在 ROCm 单卡上,「训练成功 ≠ 流程结束」,显存管理要和训练一样认真。
坑 4:uv pip uninstall -y 报错
旧版 uv 不支持 -y 参数,去掉即可:
uv pip uninstall torchvision
六、生成效果展示

七、完整 Notebook 结构一览
| 章节 | 内容 |
|---|---|
|
§1 |
安装依赖(ROCm 专用注意事项) |
|
§2.5 |
热修复 transformers / huggingface_hub |
|
§4 |
魔搭下载 Gemma 4 |
|
§5–§6 |
梦境数据集 + prompt-completion 构造 |
|
§7 |
加载 tokenizer + 基座模型 |
|
§8–§9 |
|
|
§11–§13 |
LoRA 配置 + SFTTrainer 训练 |
|
§14 |
保存状态检查 |
|
§15 |
微调后评估 |
|
§20 |
Gradio 梦境生成器 |
未来会上线Github,可以期待一下~
Github:yibohere
八、总结
| 问题 | 我的答案 |
|---|---|
|
AMD 云能微调 Gemma 4 吗? |
能,LoRA 单卡约 6 分钟 |
|
ROCm 和 CUDA 代码差别大吗? |
PyTorch 层几乎一样,环境依赖是最大坑 |
|
最值得分享的 ROCm 经验? |
别乱装包 + 训练后立刻释放显存 |
|
怎么加入 KOC? |
写文章 → 提交链接 → 等审核 |
开放算力生态正在起来。CUDA 不是唯一选择,ROCm 已经能跑真实项目了。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)