
人工智能算法详解:BERT(Bidirectional Encoder Representation from Transformers/来自 Transformer 的双向编码器表示)详解
BERT模型是NLP领域的里程碑,由Google AI在2018年提出。它采用双向Transformer架构,通过MLM和NSP预训练任务实现上下文理解,在11项NLP任务中刷新SOTA。与单向GPT不同,BERT更适合语义理解任务(如分类、问答)。后续变体如轻量化的AlBERT、优化的RoBERTa和中文适配的MacBERT进一步提升了性能。BERT的"预训练+微调"模式极大
文章目录
在NLP领域的发展历程中,2018年Google AI研究院提出的BERT模型横空出世,不仅在机器阅读理解测试SQuAD1.1的部分评价指标上(如Exact Match)超越了人类的平均表现,更在11种不同NLP任务中刷新SOTA(State-of-the-Art)成绩,将GLUE基准推高至80.5%,彻底改变了预训练语言模型的发展格局。今天,我们就从BERT的核心原理出发,逐步拆解其架构、应用场景、与GPT的差异,并深入探讨其变体模型的创新点,最后落地到Hugging Face实践,带大家全面掌握这一经典模型。
一、BERT是什么?核心价值与应用场景
BERT的全称是Bidirectional Encoder Representation from Transformers(基于Transformer的双向编码器表示),本质是一种“预训练+微调”模式的语言模型:通过大规模无标注文本完成预训练,再针对具体任务进行少量参数调整,即可快速适配各类NLP场景。
1.1. 核心价值
- 真正的双向语义理解:不同于传统单向语言模型(如早期GPT),BERT通过双向Transformer捕捉上下文信息,能更精准地理解词语在语境中的真实含义(例如“苹果”在“吃苹果”和“苹果手机”中的差异)。
- 极强的泛化能力:预训练阶段学习到的通用语言知识,可快速迁移到分类、问答、命名实体识别等多种任务,无需为每个任务从零训练模型。
- 性能突破:首次在SQuAD等任务中超越人类,为后续预训练模型(如RoBERTa、AlBERT)奠定基础。
1.2. 典型应用场景
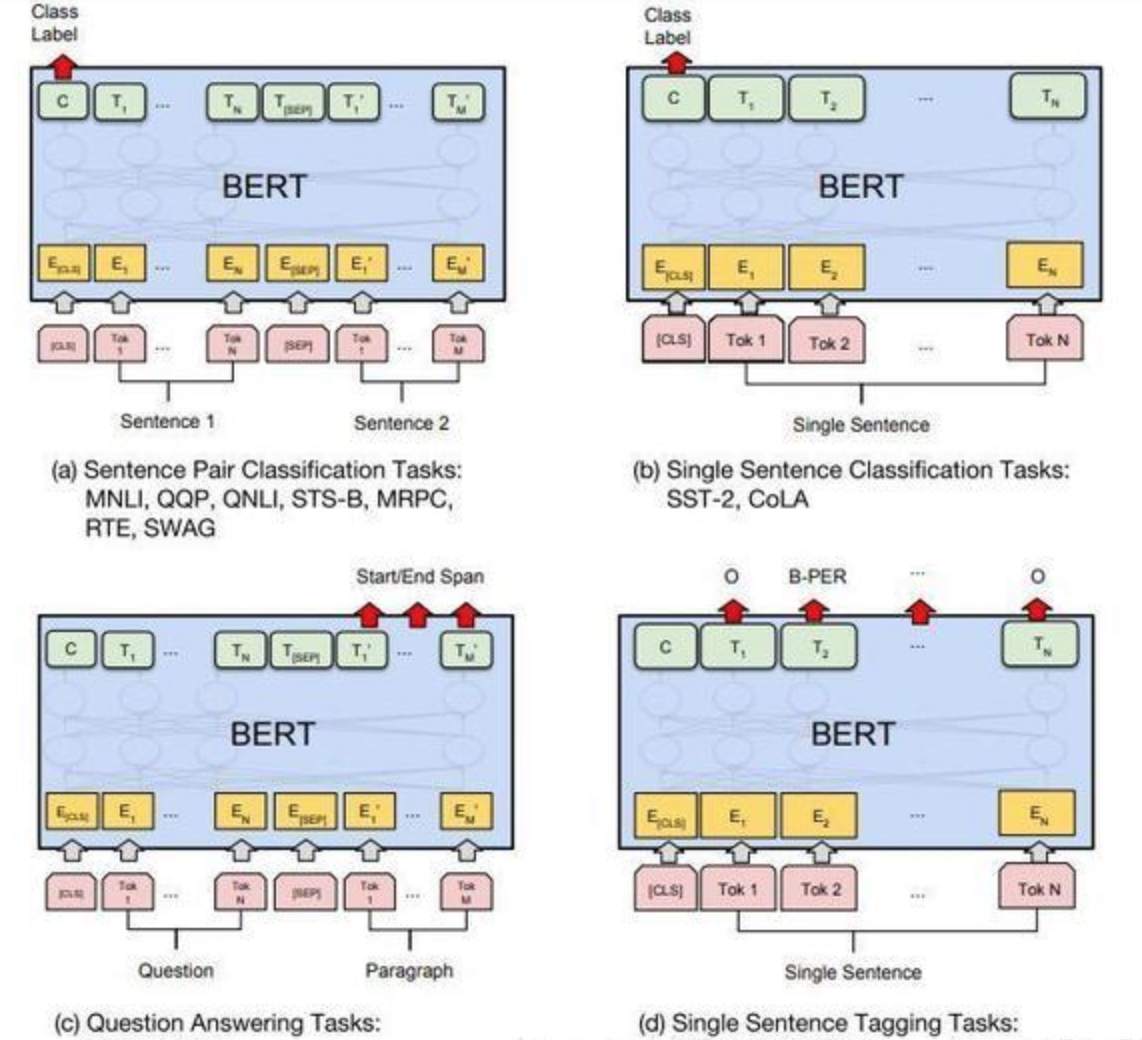
根据文档中BERT的微调任务架构,其核心应用可分为四大类:
| 任务类型 | 具体场景 | 任务目标 | 代表数据集 |
|---|---|---|---|
| 句子对分类 | 自然语言推理(NLI)、问答匹配(QQP) | 判断两个句子的关系(如“蕴含”“矛盾”“无关”) | MNLI、QQP、RTE |
| 单句分类 | 情感分析(如“好评/差评”)、语法正确性判断 | 给单个句子分配类别标签 | SST-2(情感分析)、CoLA(语法判断) |
| 问答任务 | 机器阅读理解(MRC) | 根据问题从段落中提取答案区间 | SQuAD1.1/2.0 |
| 单句标记 | 命名实体识别(NER)、词性标注 | 给句子中每个token分配标签(如“人名”“地名”) | CoNLL-2003(NER) |
二、BERT的架构与核心原理
BERT的架构可分为三大模块,从下到上依次为Embedding层、双向Transformer层、预微调层,各模块分工明确且紧密协作。
2.1 架构拆解
2.1.1 底层:Embedding模块——将文本转化为向量
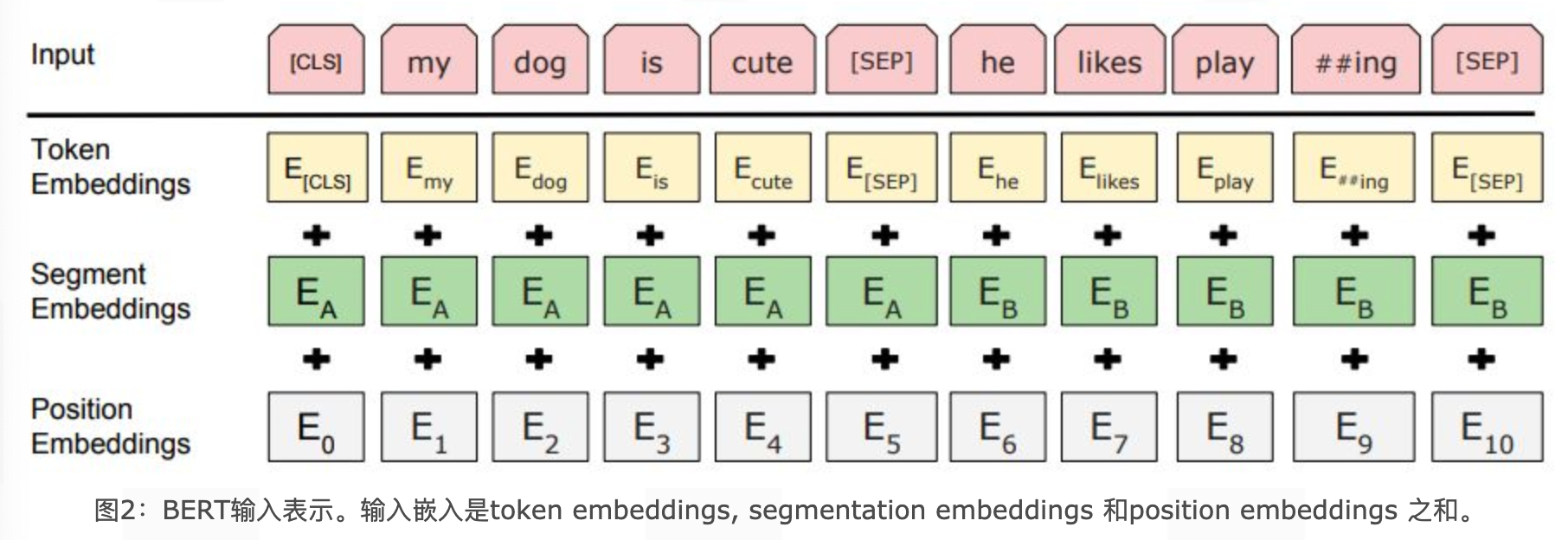
BERT的输入嵌入并非单一向量,而是三种嵌入的加和,确保文本的“词信息”“句子边界”“位置信息”被完整捕捉:
- Token Embeddings(词嵌入):将每个token(中文为单字,英文为子词)转化为固定维度向量,首个token固定为
[CLS],用于后续分类任务(如句子情感判断),句子结束用[SEP]标记。 - Segment Embeddings(句子分段嵌入):用于区分输入中的两个句子(如问答任务中的“问题”和“段落”),用两种不同向量(如
EA和EB)标记,解决“句子对关系判断”场景的需求。 - Position Embeddings(位置嵌入):不同于传统Transformer的“三角函数固定位置编码”,BERT的位置嵌入是可学习的,通过训练让模型自动捕捉文本的语序信息(如“我打他”和“他打我”的差异)。
2.1.2 中层:双向Transformer模块——语义提取核心
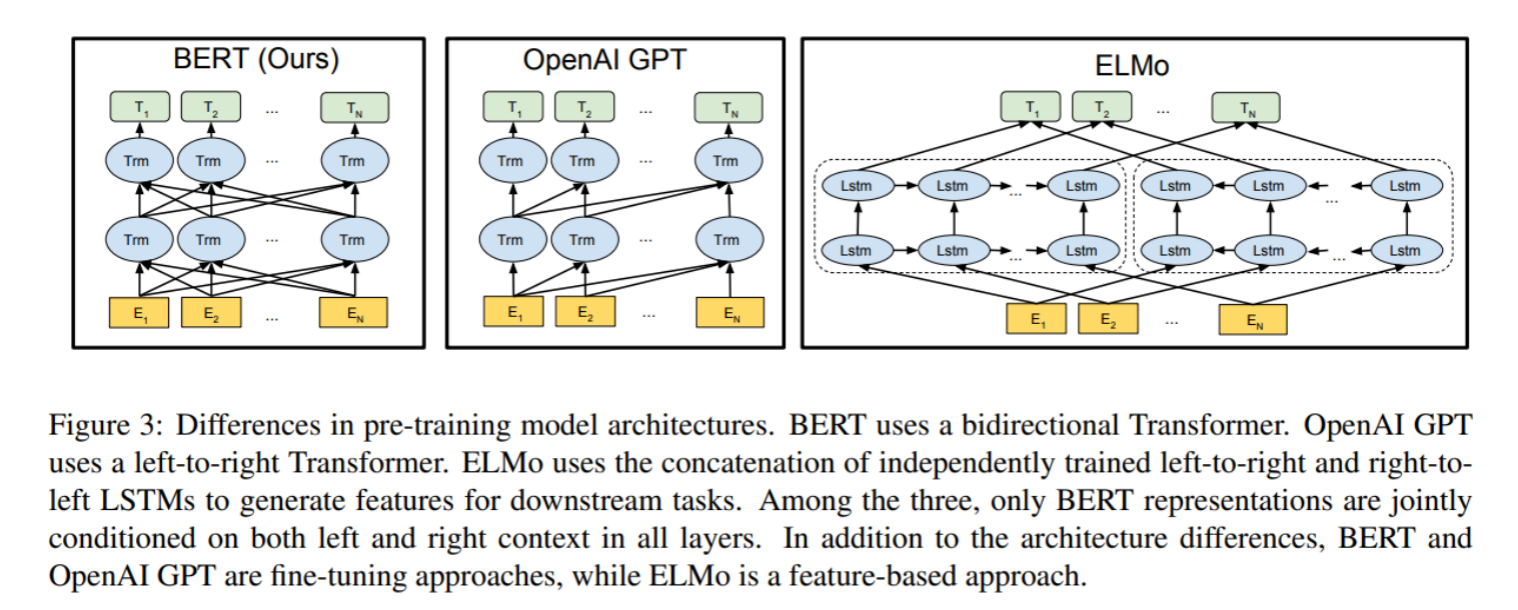
BERT仅使用Transformer的Encoder部分(舍弃Decoder),原因是Encoder的“多头注意力机制”能同时关注左右两侧的上下文,实现真正的双向语义理解。
每个Transformer Encoder块包含两个子层:
- 多头自注意力(Multi-Head Self-Attention):并行计算多个“注意力头”,捕捉不同维度的语义关联(如“手机”与“充电”的搭配、“苹果”与“水果”的类别关联)。
- 前馈神经网络(Feed-Forward Network):对注意力层的输出进行非线性变换,增强模型的表达能力。
2.1.3 上层:预微调模块——适配具体任务
预训练完成后,BERT根据任务类型调整顶层结构,无需修改底层Transformer参数(仅微调少量全连接层):
- 分类任务(如情感分析):取
[CLS]的最终隐藏状态,接全连接层+Softmax输出类别概率。 - 问答任务(如SQuAD):输出两个概率向量,分别预测答案的“起始位置”和“结束位置”。
- 命名实体识别(NER):取每个token的隐藏状态,接全连接层预测标签(如B-PER、I-LOC)。
2.2 预训练任务:BERT的“内功修炼”
BERT的强大性能源于两大精心设计的预训练任务,确保模型学习到通用语言规律:
2.2.1 Masked LM(带掩码的语言模型)——解决双向理解问题
传统单向语言模型(如GPT-1)只能从左到右或从右到左学习,无法同时利用两侧上下文。BERT通过“随机掩码”强制模型学习双向语义:
- 随机选择15%的token参与任务;
- 对选中的token按以下规则处理:
- 80%概率替换为
[MASK](如“我的狗很可爱”→“我的狗很[MASK]”); - 10%概率替换为随机token(如“我的狗很苹果”);
- 10%概率保持原token不变(如“我的狗很可爱”)。
- 80%概率替换为
- 模型需预测被处理的token的原始值,迫使模型通过上下文而非“死记硬背”学习语义。
2.2.2 Next Sentence Prediction(下一句话预测)——理解句子间关系
针对需要判断句子关系的任务(如NLI、QA),BERT引入NSP任务:
- 输入句子对(A, B),其中50%的B是A的真实下一句(正样本,标记为IsNext),50%的B是随机抽取的句子(负样本,标记为NotNext);
- 模型通过
[CLS]的隐藏状态预测B是否为A的下一句,最终在测试集上准确率可达97%-98%。
三、BERT与GPT的核心差异:为何方向不同?
BERT和GPT(Generative Pre-trained Transformer)是预训练模型的两大分支,二者差异的核心源于对Transformer模块的选择和语言模型的方向设计,直接决定了它们的适用场景。
3.1 核心差异对比
| 对比维度 | BERT | GPT(以GPT-1为例) |
|---|---|---|
| Transformer模块 | 仅使用Encoder | 仅使用Decoder |
| 语言模型方向 | 双向(同时关注左右上下文) | 单向(从左到右,屏蔽未来信息) |
| 核心能力 | 语义理解(如分类、问答、NER) | 文本生成(如续写、摘要、对话) |
| 预训练任务 | MLM + NSP | 单向语言模型(预测下一个token) |
| 微调方式 | 任务适配顶层结构 | 生成式任务直接续写,分类任务需加分类层 |
3.2 差异的本质原因
- 模块选择决定“能力侧重”:
- Transformer Encoder无“掩码机制”,能同时处理全量上下文,适合“理解任务”(如判断句子情感、提取答案);
- Transformer Decoder有“因果掩码”(屏蔽未来token),只能从左到右生成,适合“生成任务”(如续写文章、生成对话)。
- 语言模型方向决定“信息利用范围”:
- BERT的双向模型能完整捕捉词语在语境中的含义,例如“银行”在“去银行存钱”和“河边有银行”中的差异;
- GPT的单向模型更关注“语序逻辑”,例如生成“今天天气很好,我打算去公园____”时,需根据前文逻辑预测“散步”而非“吃饭”。
四、BERT变体模型:优化与创新
BERT虽强大,但存在“参数量大、训练慢、中文适配不足”等问题。后续研究者围绕“轻量化、性能提升、场景适配”进行改进,诞生了多个经典变体。
4.1 主要变体及核心改进
4.1.1 AlBERT:轻量化BERT,兼顾速度与精度
- 核心目标:减少参数量,降低训练和推理成本。
- 关键改进:
- 词嵌入参数因式分解:将“词嵌入维度=隐藏层维度”拆分为“词嵌入→中间层→隐藏层”,参数量从2300万降至48万;
- 隐藏层参数共享:所有Transformer Encoder块共享一套参数,参数量降至BERT的1/12(base版)或1/24(large版);
- 替换NSP为SOP:用“句子顺序预测”(判断[A,B]是否为正确语序)替代NSP,增强语义关系理解;
- 去除Dropout:大规模训练下无过拟合,且提升下游任务性能。
- 优势:albert-tiny仅1.8M参数,推理速度比BERT快10倍,LCQMC语义相似度任务准确率达85.4%(仅比BERT低1.5%)。
4.1.2 RoBERTa:优化训练细节,突破性能上限
- 核心目标:通过调整训练策略,进一步提升BERT性能。
- 关键改进:
- 增大训练数据:从16GB(BERT)增至160GB,新增CC-News、OpenWebText等数据集;
- 动态Masking:每次输入时随机生成Mask(而非预处理固定Mask),增强模型泛化能力;
- 去除NSP任务:实验证明NSP对大型模型有负面影响,取消后性能提升;
- 字节级BPE编码:以字节为单位构建词表(词表大小5万),解决生僻词UNK问题。
4.1.3 MacBERT:中文场景优化的BERT
- 核心目标:适配中文NLP任务,解决BERT中文“字级掩码”的不足。
- 关键改进:
- 全词+N-gram掩码:中文以“词”为单位掩码(如“苹果手机”掩码为“[MASK][MASK]”),而非单字,增强词级语义理解;
- 近义词替换掩码:用Word2Vec找近义词替代
[MASK](如“可爱”→“乖巧”),避免“训练有[MASK]、微调无[MASK]”的偏差; - 替换NSP为SOP:沿用AlBERT的SOP任务,提升中文句子关系判断能力。
4.1.4 SpanBERT:优化跨度理解,适配问答任务
- 核心目标:增强对“文本跨度”(如短语、实体)的理解,提升抽取式问答性能。
- 关键改进:
- Span Masking:按“几何分布选长度+均匀分布选起始位置”掩码连续token(平均长度3.8),而非随机单token;
- 新增SBO任务:用跨度边界token的向量+位置向量预测跨度内原始token,增强边界与内部的语义关联;
- 去除NSP:用连续长句训练,避免句子对引入的噪声。
4.2 变体模型参数与特色汇总表
| 模型 | 参数量(代表版本) | 核心优化方向 | 特色优势 | 适用场景 |
|---|---|---|---|---|
| BERT | Base:110M,Large:340M | 基础双向预训练 | 通用语义理解,适配多任务 | 全场景NLP任务(无资源限制) |
| AlBERT | Tiny:1.8M,Base:12M | 轻量化 | 速度快、资源占用低 | 移动端、实时推理场景 |
| RoBERTa | Base:125M,Large:355M | 性能提升 | 训练策略优化,SOTA刷新 | 对精度要求高的任务(如MRC) |
| MacBERT | Base:110M | 中文适配 | 全词掩码+近义词替换,中文友好 | 中文NER、情感分析、MRC |
| SpanBERT | Base:110M | 跨度理解 | SBO任务增强,跨度语义捕捉强 | 抽取式问答、实体抽取 |
五、用Hugging Face Transformers调用BERT
Hugging Face的transformers库是目前调用预训练语言模型的主流工具,其对BERT及各类变体模型提供了高度封装,支持快速完成“模型调用、本地部署、自定义适配”等操作。以下围绕“调用预设BERT、使用他人分享的BERT、本地下载与调用、关键注意事项”四大核心需求展开演示。
5.1 环境准备
首先需安装依赖库,确保transformers(模型核心)、torch(深度学习框架)、huggingface_hub( hugging face 仓库交互,可选)已正确安装:
# 基础依赖(必装)
pip install transformers torch
# 若需从hugging face Hub下载模型/交互,需额外安装
pip install huggingface_hub
5.2 调用预设类型的BERT
transformers库内置了BERT针对不同任务的“预设模型类”,每个类对应一种典型NLP任务场景,无需手动修改模型结构即可直接调用。核心预设类型及适用场景如下:
5.2.1 预设模型类与任务对应表
| 预设模型类 | 适用任务类型 | 核心作用 |
|---|---|---|
BertModel |
通用特征提取 | 输出BERT各层的隐藏状态,用于自定义下游任务(如特征拼接、多模态融合) |
BertForSequenceClassification |
单句/句子对分类 | 适用于情感分析、文本分类、自然语言推理(NLI)等任务(输出类别概率) |
BertForQuestionAnswering |
抽取式问答 | 适用于机器阅读理解(如SQuAD),输出答案的“起始位置”和“结束位置”概率 |
BertForTokenClassification |
token级标记任务 | 适用于命名实体识别(NER)、词性标注(POS)等任务(输出每个token的标签) |
BertForMaskedLM |
掩码语言模型预测 | 复现BERT的预训练MLM任务,用于文本补全、词汇纠错等场景 |
5.2.2 调用示例:以通用特征提取(BertModel)为例
from transformers import BertTokenizer, BertModel
import torch
# 1. 选择预设BERT模型(以官方基础版为例,英文无大小写区分)
model_name = "bert-base-uncased" # 官方预设的基础模型,110M参数
# 2. 加载Tokenizer(负责文本→token→ID的转换,需与模型匹配)
tokenizer = BertTokenizer.from_pretrained(model_name)
# 3. 加载预设模型(输出隐藏状态,无任务头)
model = BertModel.from_pretrained(model_name)
# 4. 文本预处理(将文本转为模型可接受的输入格式)
text = "BERT is a powerful NLP model."
inputs = tokenizer(
text,
return_tensors="pt", # 返回PyTorch张量(若用TensorFlow,设为"tf")
padding=True, # 自动补全到批次内最长文本长度
truncation=True, # 超过模型最大长度(512)时截断
max_length=512 # 强制设置最大长度(BERT默认最大512)
)
# 5. 模型推理(获取隐藏状态)
model.eval() # 切换为评估模式(禁用Dropout等训练特有的层)
with torch.no_grad(): # 禁用梯度计算,加快推理速度
outputs = model(**inputs) # **inputs自动解包输入(input_ids、attention_mask等)
# 6. 提取关键输出(BERT的隐藏状态)
last_hidden_state = outputs.last_hidden_state # 最后一层隐藏状态,形状,例如:对于本例中的输入,形状是 [1, 8, 768](批次1,token数8,维度768)
cls_embedding = last_hidden_state[:, 0, :] # 提取[CLS] token的嵌入(用于分类任务的特征)
print(f"最后一层隐藏状态形状: {last_hidden_state.shape}")
print(f"[CLS] token嵌入形状: {cls_embedding.shape}")
5.3 调用他人分享的BERT模型
Hugging Face Hub(https://huggingface.co/)是全球最大的预训练模型分享平台,用户可直接调用他人上传的BERT变体(如中文BERT、领域专用BERT),无需自行训练。
5.3.1 调用步骤(以中文BERT为例)
- 查找目标模型:在Hugging Face Hub搜索关键词(如“bert chinese”),选择高下载量、高评分的模型(如
hfl/chinese-bert-wwm-ext,中文全词掩码增强版)。 - 直接加载调用:使用
from_pretrained()指定模型的“Hub路径”(如hfl/chinese-bert-wwm-ext),无需手动下载。
5.3.2 示例:调用中文BERT进行句子分类
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 1. 选择他人分享的中文BERT模型(Hugging Face Hub路径)
model_name = "hfl/chinese-bert-wwm-ext" # 哈工大讯飞实验室的中文全词掩码BERT
# 2. 加载Tokenizer(中文模型的Tokenizer支持汉字→ID转换)
tokenizer = BertTokenizer.from_pretrained(model_name)
# 3. 加载他人训练好的句子分类模型(假设任务为“情感分析”,2分类:正面/负面)
# 注:若模型未自带分类头,需手动指定num_labels(类别数)
model = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=2 # 手动指定分类任务的类别数
)
# 4. 中文文本推理
text = "这部电影非常精彩,我很喜欢!"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
model.eval()
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_label = torch.argmax(logits, dim=1).item() # 预测类别
# 输出结果
labels = ["负面", "正面"]
print(f"文本: {text}")
print(f"预测情感: {labels[predicted_label]}")
5.4. 将BERT下载到本地并调用
若需在无网络环境下使用,或避免重复下载,可将模型和Tokenizer下载到本地,后续直接从本地路径加载。
5.4.1 本地下载步骤
from transformers import BertTokenizer, BertModel
# 1. 选择要下载的模型(如官方基础版BERT)
model_name = "bert-base-uncased"
# 2. 指定本地保存路径(自定义,如"./local_bert")
local_save_path = "./local_bert"
# 3. 下载Tokenizer并保存到本地
tokenizer = BertTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained(local_save_path) # 保存tokenizer配置(vocab.txt等)
# 4. 下载模型并保存到本地
model = BertModel.from_pretrained(model_name)
model.save_pretrained(local_save_path) # 保存模型权重(pytorch_model.bin)和配置(config.json)
print(f"模型已保存到本地路径: {local_save_path}")
5.4.2 加载本地BERT
from transformers import BertTokenizer, BertModel
# 直接从本地路径加载,无需联网
local_path = "./local_bert"
tokenizer = BertTokenizer.from_pretrained(local_path)
model = BertModel.from_pretrained(local_path)
# 后续推理步骤与“调用预设模型”一致
text = "Load BERT from local path."
inputs = tokenizer(text, return_tensors="pt")
model.eval()
with torch.no_grad():
outputs = model(**inputs)
print("本地模型加载成功,推理完成!")
5.5 调用过程中的关键注意事项
5.5.1 模型与Tokenizer的匹配性
- 必须使用同一来源的模型和Tokenizer:例如“bert-base-uncased”模型需搭配“bert-base-uncased”的Tokenizer,若混用(如用中文Tokenizer加载英文模型),会导致token→ID映射错误,模型无法正常工作。
- 中文模型的特殊注意:中文BERT的Tokenizer以“单字”为token单位(如“苹果”→“苹”“果”),无需额外分词;若使用“全词掩码BERT”(如
hfl/chinese-bert-wwm-ext),Tokenizer会自动处理词边界信息。
5.5.2 输入长度限制
- BERT的默认最大输入长度为512个token,超过会导致模型报错,需通过
truncation=True或max_length=512强制截断。 - 长文本处理:若需处理超过512token的文本,可参考BERT的长文本截断策略(如“头+尾”拼接,保留前128+后382个token),但需手动实现文本分割逻辑。
5.5.3 模型权重与框架适配
transformers支持PyTorch和TensorFlow两种框架,加载时需指定框架:- PyTorch:
return_tensors="pt",模型权重文件为pytorch_model.bin; - TensorFlow:
return_tensors="tf",模型权重文件为tf_model.h5(需下载TensorFlow版本的模型)。
- PyTorch:
- 若下载的是PyTorch模型,无法直接用TensorFlow加载,需通过
transformers的模型转换工具(如convert_bert_original_tf_checkpoint_to_pytorch)转换格式。
5.5.4 评估模式切换
- 调用模型进行推理时,必须通过
model.eval()切换为“评估模式”,否则模型中的Dropout层、BatchNorm层会处于训练状态,导致推理结果不稳定。 - 若需微调模型(而非仅推理),则需切换为训练模式:
model.train()。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)