
在 Elasticsearch 中改进 Agentic AI 工具的实验
摘要:Elasticsearch团队通过实验优化AIagent工作流中的索引选择机制,发现仅依靠索引名称准确率仅77%。通过测试结合索引描述、字段名和语义搜索等方法,最终采用混合搜索筛选候选索引再交由LLM决策的方案,将准确率提升至90%以上。该研究证实了数据驱动决策的价值,并揭示了可搜索索引元数据的重要性,为构建更智能的Agent工具奠定了基础。
作者:来自 Elastic Sean Story

了解我们如何通过结合线性检索器、混合搜索和 semantic_text,通过迭代实验改进 Elasticsearch 中的 AI agent 工作流,以实现可扩展的 RAG 优化。
通过我们的点播网络研讨会提升你的技能:使用 Elasticsearch 的 Agentic RAG,以及 Elasticsearch MCP Server 入门。
你也可以立即利用 Elastic 的生成式 AI 功能,开始免费的云试用,或在本地运行 Elasticsearch。
像当下的所有人一样,Elastic 也在全力投入 Chat、Agent 和 RAG。在搜索部门,我们最近一直在开发 Agent Builder 和 Tool Registry,目的是让在 Elasticsearch 中“聊天”你的数据变得非常简单。
想了解这一努力的 “大图景”,请阅读《使用 Elasticsearch 构建 AI Agentic 工作流》博客;想要更实用的入门指南,可以查看《你的第一个 Elastic Agent:从单次查询到 AI 驱动的聊天》。
不过,在这篇博客中,我们将聚焦于当你开始聊天时最先发生的一些事情,并带你了解我们最近所做的一些改进。
这里发生了什么?
当你与 Elasticsearch 数据聊天时,我们默认的 AI Agent 会按照以下标准流程运行:
-
检查提示。
-
确定哪个索引最有可能包含该提示的答案。
-
根据提示为该索引生成查询。
-
使用该查询搜索该索引。
-
综合结果。
-
这些结果能回答提示吗?如果能,就响应;如果不能,就重复,但尝试不同的方法。
这看起来并不新奇 —— 这就是检索增强生成(RAG)。正如你所预期的那样,响应的质量在很大程度上取决于初始搜索结果的相关性。
因此,在我们改进响应质量的过程中,我们特别关注了第 3 步生成的查询和第 4 步运行的查询。然后我们注意到一个有趣的模式。
通常,当我们的第一次响应 “很差” 时,并不是因为我们执行了错误的查询,而是因为我们选择了错误的索引来查询。问题往往不在第 3 和第 4 步 —— 而在第 2 步。
我们当时在做什么?
我们最初的实现很简单。我们构建了一个名为 index_explorer 的工具,它会执行一次 _cat/indices 来列出我们可用的所有索引,然后让 LLM 识别这些索引中哪个最符合用户的消息、问题或提示。你可以在这里看到这个最初的实现。
You are an AI assistant for the Elasticsearch company.
based on a natural language query from the user, your task is to select up to ${limit} most relevant indices from a list of indices.
*The natural language query is:* ${nlQuery}
*List of indices:*
${indices.map((index) => `- ${index.index}`).join('\n')}
Based on those information, please return most relevant indices with your reasoning.
Remember, you should select at maximum ${limit} indices.这个方法效果如何?我们并不确定!我们确实有一些明显的例子表明它效果不好,但我们真正的第一个挑战是量化当前的状况。
建立基线
从数据开始
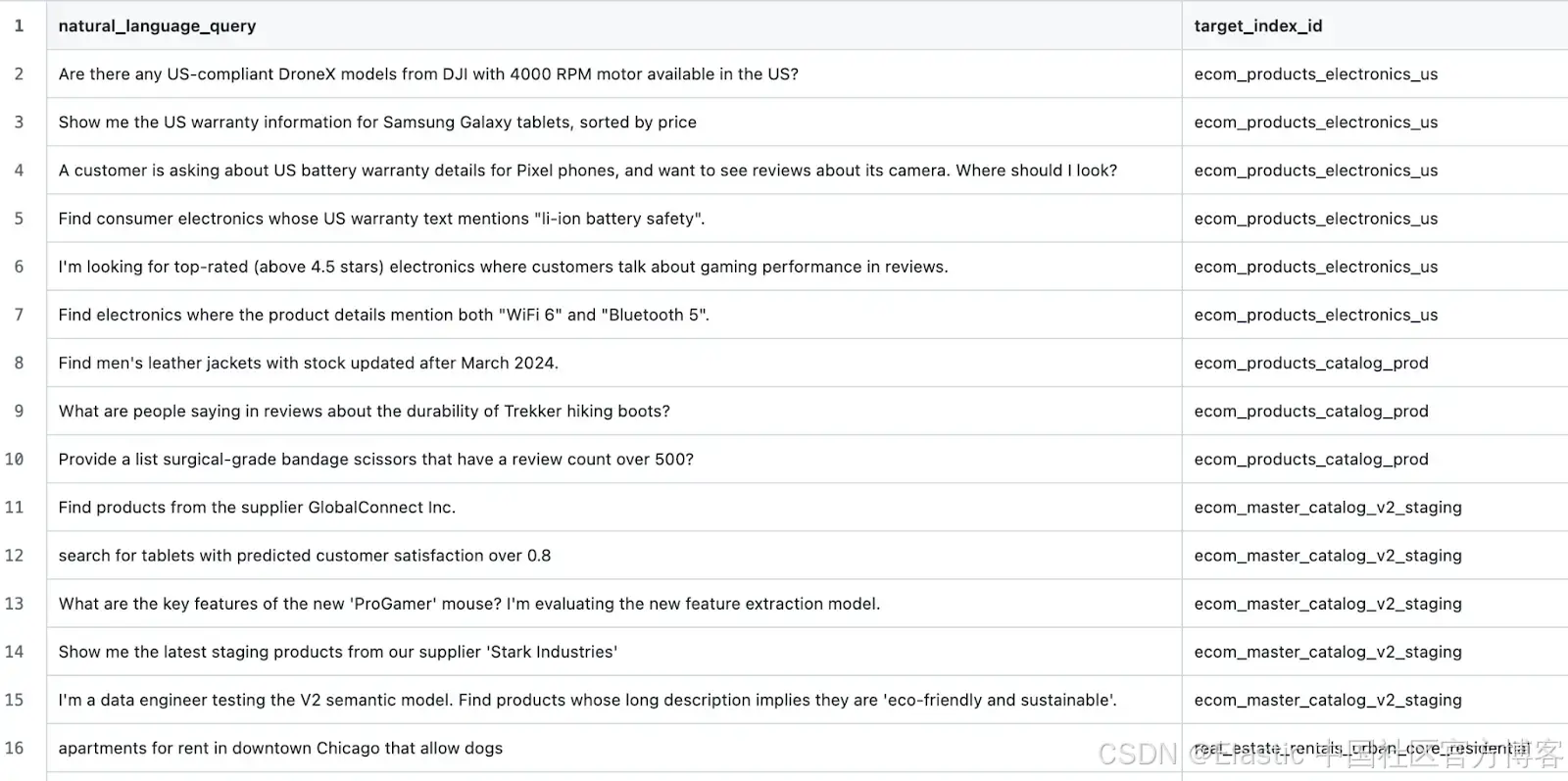
我们需要的是一个黄金数据集,用来衡量一个工具在面对用户提示和一组已有索引时,选择正确索引的有效性。而我们手头并没有这样的数据集。所以我们生成了一个。
致谢: 我们知道这不是 “最佳实践”。但有时候,前进比争论细节更重要。进步,简单胜于完美。
我们使用这个提示为几个不同的领域生成了种子索引。然后,对于每个生成的领域,我们又使用这个提示生成了更多索引(目的是通过困难的负样本和难以分类的示例来增加 LLM 的混淆)。接着,我们手动编辑了每个生成的索引及其描述。最后,我们使用这个提示生成了测试查询。这样,我们就得到了如下的示例数据:

以及如下的测试用例:
构建测试框架
接下来的过程非常简单。编写一个工具脚本,可以:
-
在目标 Elasticsearch 集群上建立一个干净的环境。
-
创建目标数据集中定义的所有索引。
-
对于每个测试场景,执行 index_explorer 工具(很方便,我们有一个 Execute Tool API)。
-
将结果索引与预期索引进行比较,并记录结果。
-
在完成所有测试场景后,汇总结果。
调查结果……
最初的结果并不令人意外 —— 表现平平。
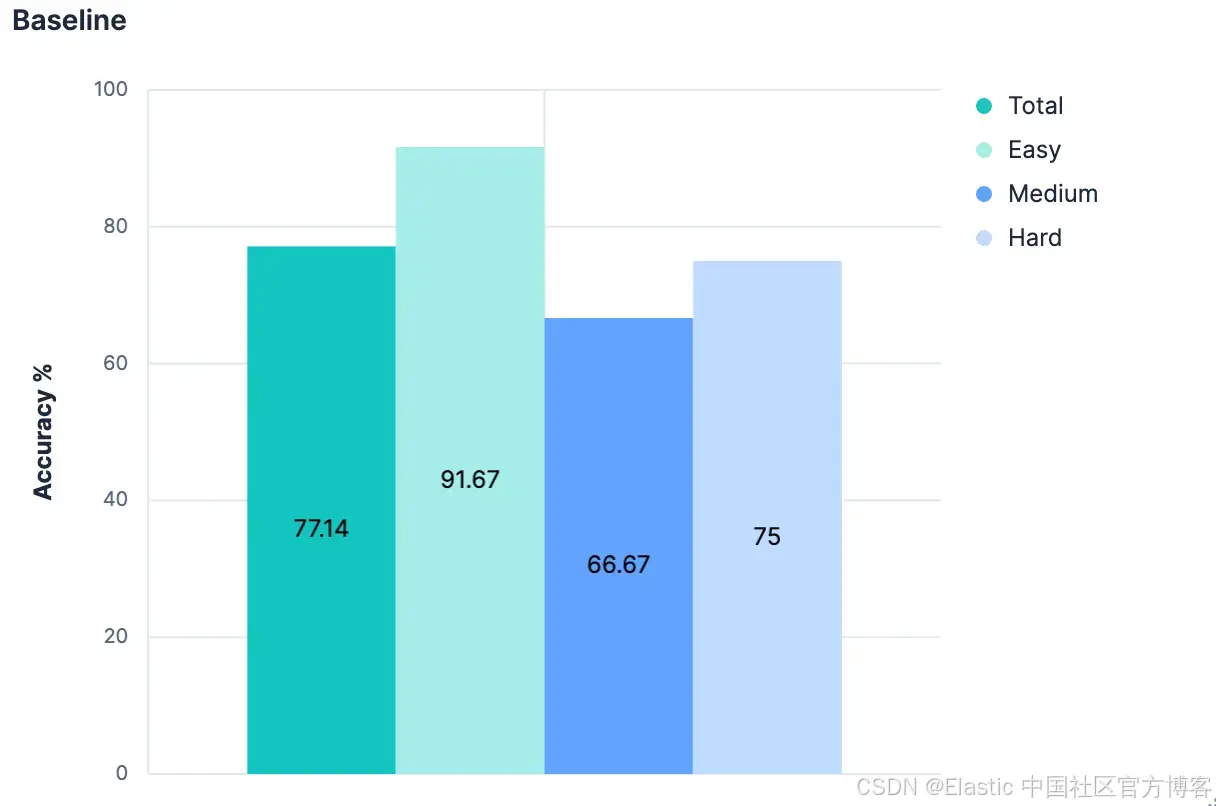
总体上,在识别正确索引方面准确率为 77.14%。而这还是在 “最佳情况” 下进行的测试,所有索引都有良好且语义清晰的名称。任何做过 PUT test2/_doc/foo {...} 的人都知道,索引名称并不总是有意义的。
所以,我们有了一个基线,并显示出有很大的改进空间。现在是做一些科学实验的时候了!🧪
实验
假设 1:Mappings 会有帮助
这里的目标是识别一个包含与原始提示相关数据的索引。而最能描述索引所含数据的部分是索引的 mappings。即使不抓取索引内容的样本,仅知道索引有一个 double 类型的 price 字段,就意味着数据代表某种待售物品。text 类型的 author 字段意味着某些非结构化语言数据。两者结合可能暗示数据是书籍/故事/诗歌。仅通过索引的属性,我们就能推导出很多语义线索。
因此,在本地分支中,我调整了我们的 .index_explorer 工具,将索引的完整 mappings(以及名称)发送给 LLM 来做出决策。
结果(来自 Kibana 日志):
[2025-09-05T11:01:21.552-05:00][ERROR][plugins.onechat] Error: Error calling connector: event: error
data: {"error":{"code":"request_entity_too_large","message":"Received a content too large status code for request from inference entity id [.rainbow-sprinkles-elastic] status [413]","type":"error"}}
at createInferenceProviderError (errors.ts:90:10)
at convertUpstreamError (convert_upstream_error.ts:39:38)
at handle_connector_response.ts:26:33
at Observable.init [as _subscribe] (/Users/seanstory/Desktop/Dev/kibana/node_modules/rxjs/src/internal/observable/throwError.ts:123:68)...工具的最初作者已经预料到这一点。虽然索引的 mapping 是信息的宝库,但它也是一个相当冗长的 JSON 块。在现实场景中,当你需要比较大量索引(我们的评估数据集定义了 20 个索引)时,这些 JSON 块会累积起来。因此,我们希望给 LLM 提供比仅索引名称更多的上下文,但又不要像每个索引的完整 mapping 那样庞大。
假设 2:将 mapping “扁平化”(字段列表)作为折衷
我们最初假设索引创建者会使用语义有意义的索引名称。如果我们将这个假设扩展到字段名称呢?我们之前的实验失败,是因为 mapping JSON 包含了大量冗余的元数据和样板内容。
"description_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
},
"copy_to": [
"description_semantic"
]
},例如,上面的块有 236 个字符,而它仅定义了 Elasticsearch mapping 中的一个字段。而字符串 “description_text” 只有 16 个字符。字符数几乎增加了 15 倍,但在描述该字段所代表的数据含义上,并没有实质性的语义提升。如果我们获取所有索引的 mappings,但在发送给 LLM 之前,将它们“扁平化”为仅包含字段名称的列表,会怎样呢?
我们尝试了一下。
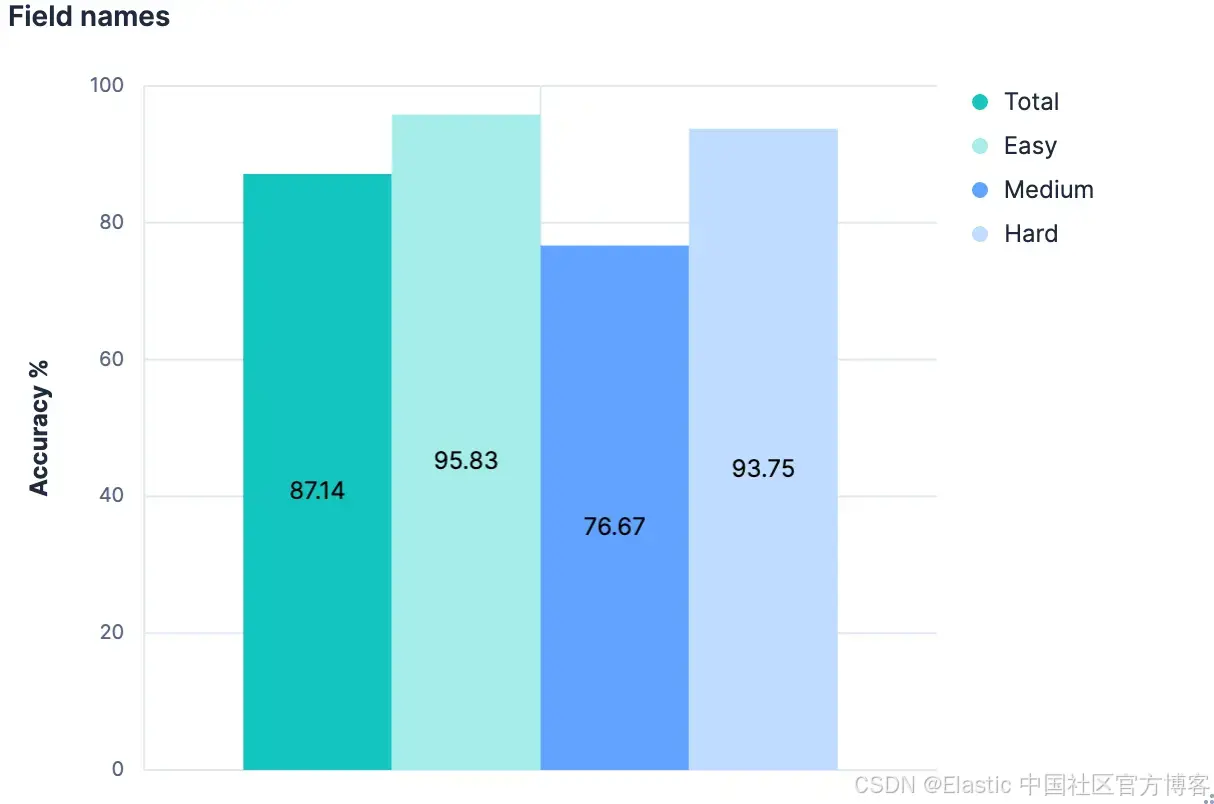
太棒了!各方面都有改进。但我们还能做得更好吗?
假设 3:mapping 的 _meta 中的描述
如果仅字段名称而没有额外上下文就能带来如此大的提升,那么增加实质性上下文可能会更好!虽然并非每个索引都有附加描述是常规做法,但可以在 mapping 的 _meta 对象中添加任何类型的索引级元数据。我们回到生成的索引,为数据集中的每个索引添加了描述。只要描述不过长,它们应该比完整 mapping 使用更少的 token,同时显著提供关于索引包含数据的洞察。我们的实验验证了这一假设。
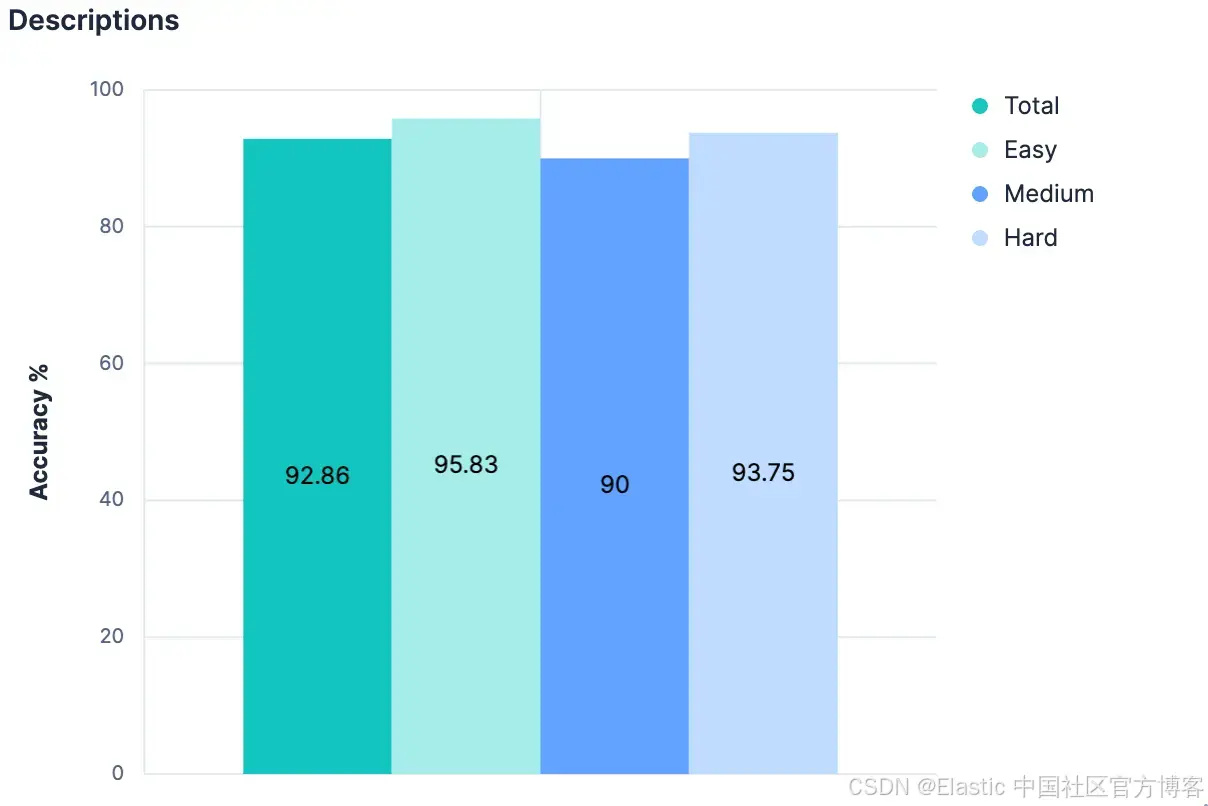
取得了适度的改进,现在整体准确率已超过 90%。
假设 4:整体大于部分之和
字段名称提高了我们的结果。描述也提高了我们的结果。那么,同时使用描述和字段名称,结果应该会更好,对吗?
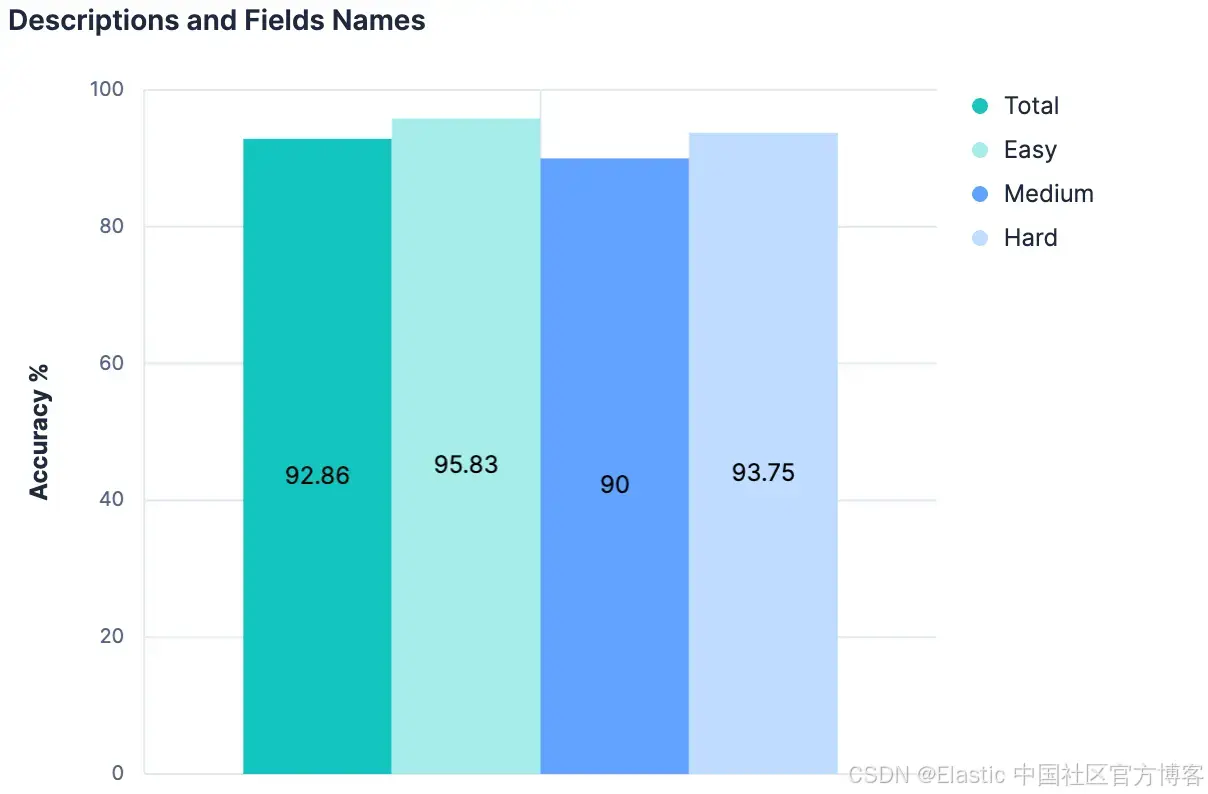
数据给出的答案是 “不”(与上一次实验相比没有变化)。这里的主要理论是,由于描述最初就是从索引字段/mapping 生成的,当将它们组合时,这两部分上下文之间没有足够不同的信息来增加任何 “新” 的内容。此外,我们为 20 个测试索引发送的负载已经相当大。到目前为止的思路不可扩展。事实上,有充分理由相信,到目前为止的任何实验,在有数百或数千个索引可供选择的 Elasticsearch 集群上都不会有效。随着索引总数增加而线性增加发送给 LLM 的消息大小的任何方法,可能都不是通用策略。
我们真正需要的是一种方法,帮助我们从大量候选项中筛选出最相关的选项……
这里实际上是一个搜索问题。
假设 5:通过语义搜索进行选择
如果索引名称有语义意义,那么它可以存储为向量并进行语义搜索。
如果索引字段名称有语义意义,那么它们也可以存储为向量,并进行语义搜索。
如果索引有语义化的描述,它同样可以存储为向量,并进行语义搜索。
目前,Elasticsearch 索引并没有让这些信息可搜索(也许我们应该!),但用一些简单的手段可以绕过这个限制。使用 Elastic 的 connector 框架,我构建了一个连接器,它会为集群中的每个索引输出一个文档。输出文档大致如下:
doc = {
"_id": index_name,
"index_name": index_name,
"meta_description”: description,
"field_descriptions" = field_descriptions,
"mapping": json.dumps(mapping),
"source_cluster": self.es_client.configured_host,
}我将这些文档发送到一个新索引中,并在其中手动定义了 mapping,如下:
{
"mappings": {
"properties": {
"semantic_content": {
"type": "semantic_text"
},
"index_name": {
"type": "text",
"copy_to": "semantic_content"
},
"mapping": {
"type": "keyword",
"copy_to": "semantic_content"
},
"source_cluster": {
"type": "keyword"
},
"meta_description": {
"type": "text",
"copy_to": "semantic_content"
},
"field_descriptions": {
"type": "text",
"copy_to": "semantic_content"
}
}
}
}GET indexed-indices/_search
{
"query": {
"semantic": {
"field": "semantic_content",
"query": "$query"
}
}
}修改后的 index_explorer 工具现在速度更快,因为它不需要向 LLM 发送请求,而是可以为给定查询请求单个 embedding 并执行高效的向量搜索操作。以最高命中的结果作为我们选择的索引,我们得到的结果是:
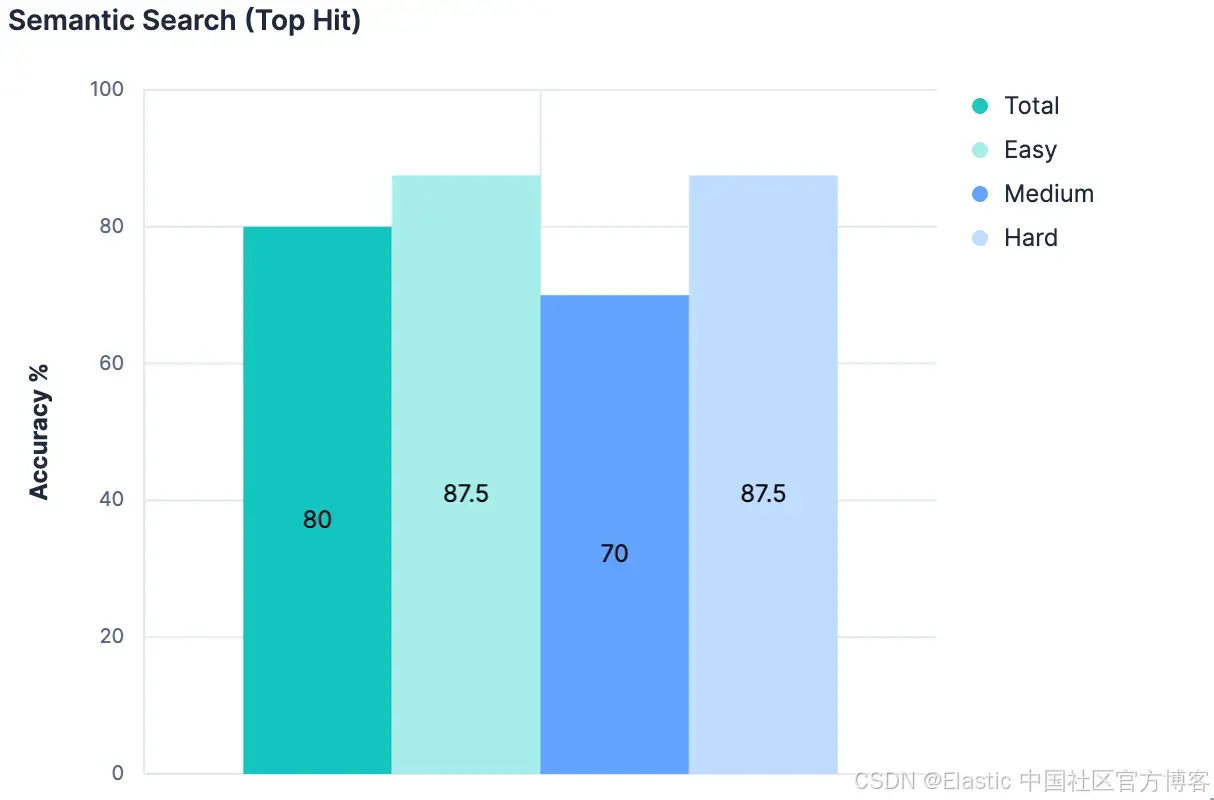
这种方法具有可扩展性,也很高效。但这种方法几乎只比我们的基线稍好。这并不意外;这里的搜索方法非常简单。没有细微之处。没有意识到索引的名称和描述应该比索引包含的任意字段名称更重要。没有机制优先考虑精确的词汇匹配而非同义匹配。然而,要构建高度细致的查询,需要对手头的数据做出很多假设。到目前为止,我们已经对索引和字段名称具有语义意义做出了一些大假设,但我们需要进一步假设它们有多少含义以及它们之间如何关联。如果不这样做,我们可能无法可靠地将最佳匹配识别为首选结果,但更可能只能说最佳匹配在前 N 个结果中。我们需要一种方法,能够在其存在的上下文中处理语义信息,与可能以语义上不同方式表示自身的另一个实体进行比较,并在它们之间做出判断。就像 LLM 一样。
假设 6:候选集缩减
还有一些实验我将略过,但关键突破是放弃仅依靠语义搜索选择最佳匹配的想法,而是将语义搜索作为筛选器,剔除 LLM 考虑中的无关索引。我们结合了 Linear Retrievers、带 RRF 的 Hybrid Search 和 semantic_text 进行搜索,将结果限制为前 5 个匹配的索引。
然后,对于每个匹配,我们将索引的名称、描述和字段名称添加到发送给 LLM 的消息中。结果非常出色:
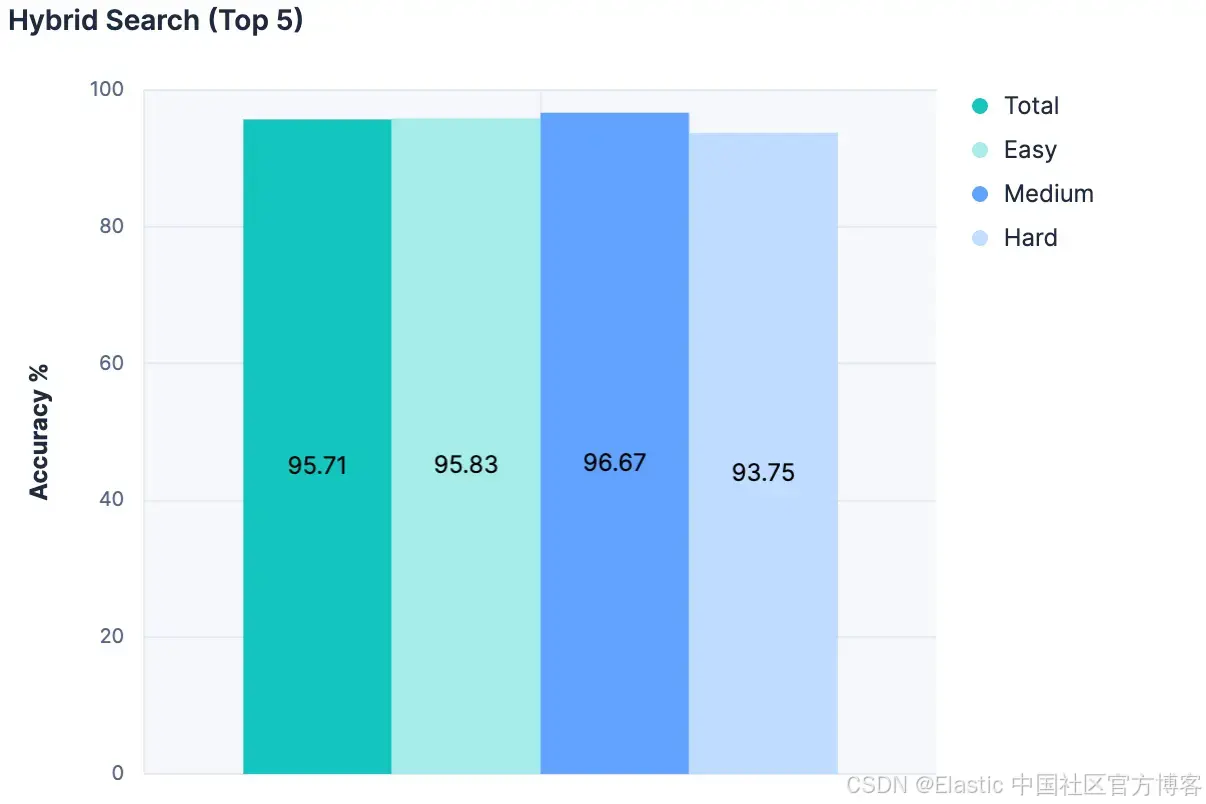
迄今为止的所有实验中准确率最高!而且由于这种方法不会随着索引总数成比例地增加消息大小,因此这种方法更具可扩展性。
结果
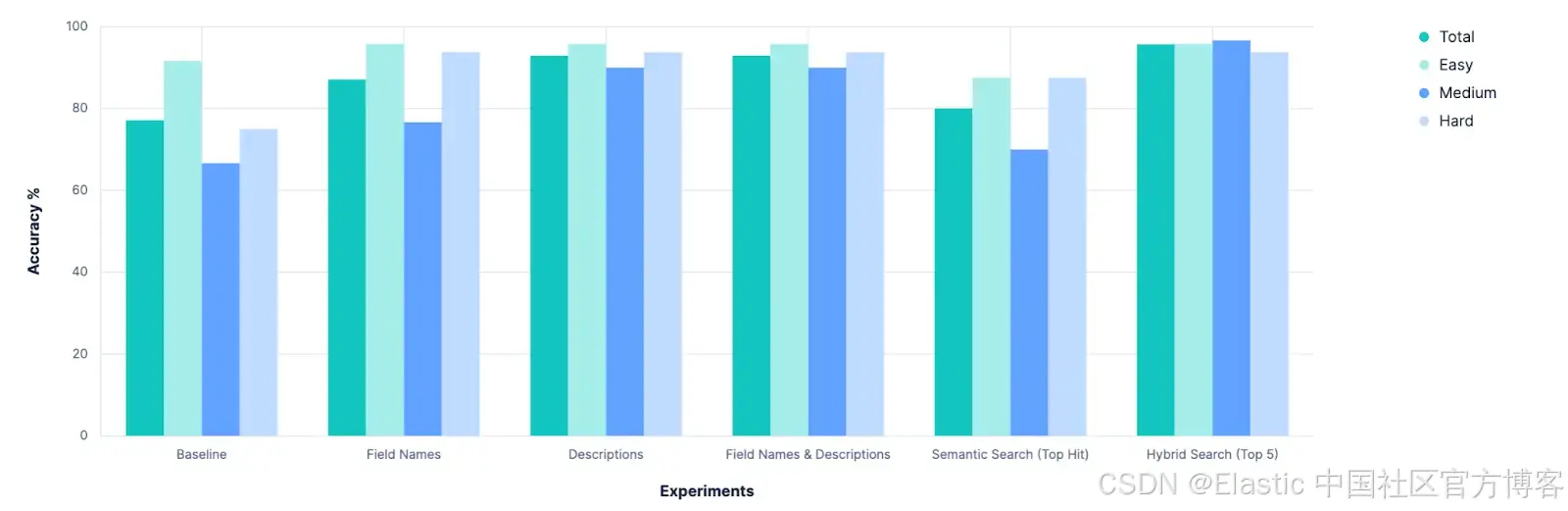
第一个明显的结果是,我们的基线是可以改进的。事后看来这似乎很明显,但在实验开始之前,曾有过严肃讨论,是否应完全放弃 index_explorer 工具,而依赖用户的显式配置来限制搜索空间。虽然这仍然是可行且有效的选项,但这项研究表明,当无法获得用户输入时,自动选择索引仍有可行路径。
下一个明显的结果是,仅仅增加更多描述字符的效果会递减。在这项研究之前,我们曾讨论是否应该投资扩展 Elasticsearch 存储字段级元数据的能力。目前,这些 meta 值限制为 50 个字符,并假设需要增加这个值才能从字段中推导语义理解。但事实显然不是这样,LLM 仅凭字段名称就表现良好。我们可能以后会进一步研究,但目前这已不紧迫。
相反,这清楚地表明了拥有 “可搜索” 索引元数据的重要性。在这些实验中,我们使用了一个索引的索引(index-of-indices)方法。但这是我们可以考虑直接构建到 Elasticsearch 中的功能,建立管理 API,或至少制定相关约定。我们会权衡选项并在内部讨论,敬请关注。
最后,这项工作确认了我们花时间进行实验并做出数据驱动决策的价值。实际上,它帮助我们重新确认,Agent Builder 产品需要一些健全的产品内评估功能。如果我们需要为一个选择索引的工具构建完整的测试框架,我们的客户绝对需要方法来在进行迭代调整时对其自定义工具进行定性评估。
我很期待看到我们将构建的内容,也希望你同样感到兴奋!
原文:https://www.elastic.co/search-labs/blog/ai-agent-builder-experiments-performance
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)