
【必看收藏】Spring AI Alibaba数据观测方案:基于OpenTelemetry与Langfuse的系统监控详解
【摘要】本文探讨了AI Agent系统的现代化监控方案,针对传统ELK日志系统在AI场景下的不足(如复杂数据处理困难、时序关联性差、分布式追踪缺失),提出基于OpenTelemetry与Langfuse的观测体系。重点介绍了如何通过OpenTelemetry采集AI关键指标(TTFT、TPOT、Token使用量等),并集成Langfuse平台实现可视化分析与调试。方案包含Spring AI接入La
本文介绍了Spring AI Alibaba的数据观测方案,对比传统ELK日志系统在AI Agent中的局限性,提出基于OpenTelemetry与Langfuse的现代化监控解决方案。详细展示了如何通过OpenTelemetry收集AI系统的性能指标(如TTFT、TPOT、Token使用量等),并使用Langfuse平台进行可视化分析和调试。提供了完整的Spring AI接入Langfuse步骤和代码示例,帮助开发者构建高效的AI应用监控系统。
传统ELK日志搜集平台
传统的ELK(Elasticsearch + Logstash + Kibana)日志采集架构在企业级应用广泛,流程为:
应用程序 → 日志输出 → 采集 → Logstash解析 → Elasticsearch存储 → Kibana可视化
这套架构在处理传统Web应用时表现良好,但面对AI Agent系统时暴露出以下核心问题:
复杂数据处理
AI系统产生的复杂指标数据(Token使用量、推理时延、成本计算)需要通过频繁的日志打印和计算才能获取。
时序数据关联性差
AI推理过程包含多个时间节点:请求接收、首token返回、推理完成等。传统日志系统缺乏时序关联查询能力,难以实现实时性能分析。
分布式追踪能力缺失
用户请求可能跨越多个Agent节点、多次模型调用、多种外部工具。ELK缺乏原生的分布式追踪能力,无法自动构建完整调用链路,排查问题时需手动关联多个日志源。
一个生产级的Agent系统数据观测成为必要条件
AI Agent系统的数据观测需求
模型推理性能指标
- • TTFT (Time to First Token):从请求发送到接收第一个token的延迟,直接影响用户感知的响应速度
- • TPOT (Time per Output Token):生成每个输出token的平均时间,反映模型推理的吞吐能力
- • Total Duration:完整请求的端到端耗时,包含网络传输、模型推理、后处理等环节
资源消耗与成本指标
- • Token Usage:输入token数、输出token数、总消耗token数的精确统计
- • Cost Calculation:基于不同模型定价策略的实时成本计算
Agent协作指标
- • Workflow Execution:节点执行路径和状态
- • Tool Calling:外部工具(搜索引擎、知识库、编程环境)的调用性能
- • Context Passing:Agent间上下文传递的数据
OpenTelemetry:观测性探针
1. OpenTelemetry
OpenTelemetry 是一个开源的可观测性框架,旨在提供一套统一的标准、API 和工具,帮助开发者收集、处理和导出分布式系统的遥测数据(包括追踪、指标和日志),从而实现对系统的可观测性。
三大核心能力
- • 分布式追踪(Traces):提供请求在分布式系统中的完整执行路径,帮助识别性能瓶颈和调用关系
- • 指标监控(Metrics):收集系统性能指标和业务度量数据,支持实时监控和告警
- • 结构化日志(Logs):提供结构化事件记录,包含上下文关联信息,便于问题根因分析
langfuse
Langfuse 是一个开源的可观测性和分析平台,专为由大型语言模型(LLM)驱动的应用而设计。
开源地址
https://github.com/langfuse/langfuse
主要功能:
监测
- • 跟踪:捕捉产品的完整上下文,包括外部 API 或工具调用、上下文、提示等。
- • 实时指标:监控关键性能指标,如响应时间、错误率和吞吐量。
- • 反馈:收集用户反馈,以改进应用程序的性能和用户体验。
分析
- • 评估:通过设置 llm-as-a-judge 评估或人工标注工作流程,比较不同模型、提示和配置的性能。
- • 测试:试验不同版本(A/B)的应用程序,通过测试和提示管理确定最有效的解决方案
- • 用户行为:了解用户与人工智能应用程序的交互方式。
调试
- • 详细的调试日志:访问所有应用程序活动的综合日志,以排除故障。
- • 错误跟踪:检测和跟踪应用程序中的错误和异常。
SpringAI 接入 langfuse
1 依赖配置
首先在pom.xml中添加必要的依赖:
<!-- OpenTelemetry Spring Boot自动配置 --><dependency> <groupId>io.opentelemetry.instrumentation</groupId> <artifactId>opentelemetry-spring-boot-starter</artifactId> <version>2.9.0</version></dependency><!-- Micrometer到OpenTelemetry的桥接 --><dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-tracing-bridge-otel</artifactId></dependency><!-- OTLP协议导出器 --><dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-exporter-otlp</artifactId></dependency><!-- Spring Boot Actuator监控 --><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId></dependency><!-- Spring AI Alibaba图观测扩展 --><dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-graph-observation</artifactId> <version>1.0.0.3</version></dependency>
2 观测性配置文件
创建application.yml配置文件:
# OpenTelemetry观测配置management: endpoints: web: exposure: include: "*" # 暴露所有监控端点 endpoint: health: enabled: true show-details: always # 显示详细健康检查信息 tracing: sampling: probability: 1.0 # 100%采样率 observations: annotations: enabled: true # 启用基于注解的观测# OpenTelemetry核心配置otel: service: name: spring-ai-alibaba-deepresearch-langfuse # 服务标识 resource: attributes: deployment.environment: development # 环境标识 # 链路追踪配置 traces: exporter: otlp # 使用OTLP协议导出 sampler: always_on # 总是采样(开发环境) # 指标监控配置 metrics: exporter: otlp # 指标导出 # 日志配置(Langfuse暂不支持) logs: exporter: none # 禁用日志导出 # OTLP导出器配置 exporter: otlp: # Langfuse服务端点 endpoint: "http://localhost:3000/api/public/otel" # 本地部署 headers: # Base64编码的认证凭据 Authorization: "Basic ${YOUR_BASE64_ENCODED_CREDENTIALS}" protocol: http/protobuf # 使用protobuf协议,提升传输效率
Langfuse 启动
git clone https://github.com/langfuse/langfuse.gitcd langfuse# Run the langfuse docker composedocker compose up
配置密钥
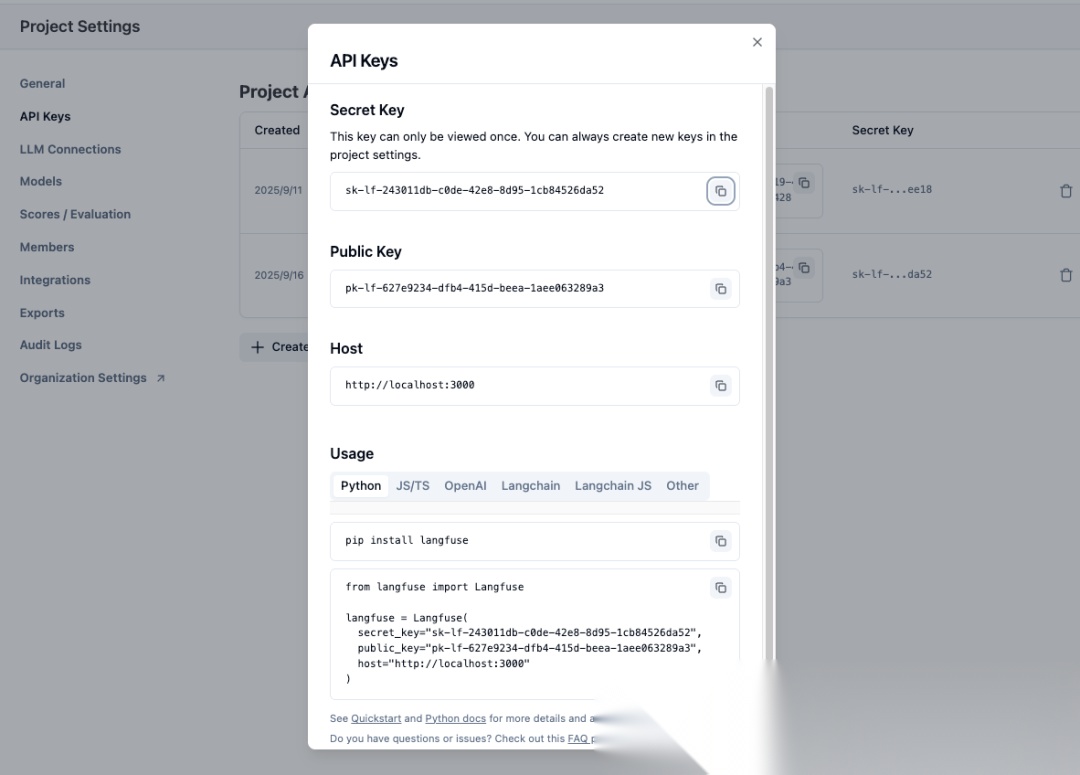
生成Token
# Linux/macOSecho -n "public_key:secret_key" | base64# Windows PowerShell [System.Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes("public_key:secret_key"))
yaml配置
exporter: otlp: endpoint: headers: # Base64编码的认证凭据 Authorization: "Basic ${YOUR_BASE64_ENCODED_CREDENTIALS}"
config配置
@Componentpublic class ChatModelCompletionContentObservationFilter implements ObservationFilter { @Override public Observation.Context map(Observation.Context context) { if (!(context instanceof ChatModelObservationContext chatModelObservationContext)) { return context; } var prompts = processPrompts(chatModelObservationContext); var completions = processCompletion(chatModelObservationContext); chatModelObservationContext.addHighCardinalityKeyValue(new KeyValue() { @Override public String getKey() { return "gen_ai.prompt"; } @Override public String getValue() { return ObservabilityHelper.concatenateStrings(prompts); } }); chatModelObservationContext.addHighCardinalityKeyValue(new KeyValue() { @Override public String getKey() { return "gen_ai.completion"; } @Override public String getValue() { return ObservabilityHelper.concatenateStrings(completions); } }); return chatModelObservationContext; } private List<String> processPrompts(ChatModelObservationContext chatModelObservationContext) { return CollectionUtils.isEmpty((chatModelObservationContext.getRequest()).getInstructions()) ? List.of() : (chatModelObservationContext.getRequest()).getInstructions().stream().map(Content::getText).toList(); } private List<String> processCompletion(ChatModelObservationContext context) { if (context.getResponse() != null && (context.getResponse()).getResults() != null && !CollectionUtils.isEmpty((context.getResponse()).getResults())) { return !StringUtils.hasText((context.getResponse()).getResult().getOutput().getText()) ? List.of() : (context.getResponse()).getResults().stream().filter((generation) -> generation.getOutput() != null && StringUtils.hasText(generation.getOutput().getText())).map((generation) -> generation.getOutput().getText()).toList(); } else { return List.of(); } }}
该方法实现了ObservationFilter接口,通过过滤器模式捕获AI模型的输入提示词和输出内容,并将其作为OpenTelemetry标准的高基数标签(gen_ai.prompt、gen_ai.completion)添加到观测上下文中。
请求接口后去平台查看观测数据
可以看到完整的请求LLM prompt和输出
可以看到完整的请求LLM prompt和输出
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐


 8
8 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)