
数据派THU | 原创|大模型高效语义表征训练:BatchTripletLoss的优化策略和实现
本文介绍了在sentence_transformers库中使用三元组损失(TripletLoss)的方法及其在NLP文本嵌入任务中的应用。三元组损失通过(锚点、正样本、负样本)组合学习语义关系,使相似文本在嵌入空间靠近。文章详细解析了四种三元组损失实现方式:BatchAll、BatchHard、BatchSemiHard和BatchHardSoftMargin,并对比了各自的优缺点。最后通过代码示
本文来源公众号“数据派THU”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/rHzMeDw-X7R0QY-HGH15WA
本文将介绍如何在 sentence_transformers 库中使用三元组损失,以及如何通过在线三元组挖掘来优化训练过程。
在自然语言处理(NLP)领域,尤其是在文本嵌入和语义相似性任务中,三元组损失(Triplet Loss)是一种非常重要的技术。它被广泛应用于学习文本的良好嵌入(或“编码”),使得语义相似的文本在嵌入空间中彼此靠近,而语义不同的文本则彼此远离。
如果你对嵌入模型还不是很理解,建议先通过一些优秀的学习资源(例如在数据派公众号搜索“embedding模型”)来了解其基本原理。
在实际应用中,三元组损失的实现往往面临一些挑战,尤其是在涉及到大规模数据集和复杂模型时。sentence_transformers 是一个基于 PyTorch 的开源库,专门用于训练和生成高质量的文本嵌入。它提供了强大的工具来实现三元组损失,并支持在线三元组挖掘,从而显著提高了模型的训练效率和性能。
在本文中,我将介绍如何在sentence_transformers 库中使用三元组损失,以及如何通过在线三元组挖掘来优化训练过程。具体来说,我将:
解释三元组损失的基本概念及其在文本嵌入中的应用。
提供一个完整的代码示例,展示如何在 sentence_transformers 中实现三元组损失训练的过程。
三元组的概念
在机器学习和深度学习中,尤其是在度量学习(Metric Learning)和嵌入学习(Embedding Learning)中,三元组(Triplet)是一种特殊的样本组合,用于训练模型以学习数据的嵌入空间。一个三元组的具体形式是(锚点(Anchor)、正样本(Positive)、负样本(Negative)),由三个部分组成:
-
锚点(Anchor):这是三元组中的基准样本,用于与其他两个样本进行比较。
-
正样本(Positive):与锚点属于同一类别的样本。
-
负样本(Negative):与锚点属于不同类别的样本。
三元组损失函数(Triplet Loss)
三元组损失函数是度量学习中常用的损失函数之一。它的目标是确保正样本与锚点的距离小于负样本与锚点的距离,加上一个预定义的间隔(margin)。数学表达式如下: L=max(0,d(a,p)−d(a,n)+margin) 其中:
-
a 是锚点的嵌入向量。
-
p 是正样本的嵌入向量。
-
n 是负样本的嵌入向量。
-
d(a,p) 是锚点与正样本之间的距离。
-
d(a,n) 是锚点与负样本之间的距离。
-
margin 是一个预定义的间隔值,用于确保正样本和负样本之间的距离有足够的差距。
为什么选择三元组损失?
在许多机器学习任务中,我们常常依赖于传统的监督学习方法,例如使用 Softmax 交叉熵损失来训练分类模型。这种方法在固定类别数量的场景下表现良好,但在一些动态场景中却显得力不从心。例如,在一些任务中,我们可能需要处理可变数量的类别,或者需要判断两个未知样本之间的相似性。以文本处理为例,我们常常需要判断两段文本是否表达了相似的语义,这种需求在传统的分类框架下难以有效实现。
三元组损失提供了一种新的思路。它通过学习嵌入空间中的语义关系,使得同一类别的样本在嵌入空间中相互靠近,而不同类别的样本则相互远离。这种方法的核心优势在于其灵活性和适应性,它能够动态地处理不同类别数量的样本,非常适合于需要判断样本相似性的任务,如文本相似性分析、多语言文本对齐等。通过这种方式,三元组损失为处理复杂的语义关系提供了一种高效的解决方案。
三元组损失的几种形式
在sentence_transformers中,三元组损失函数有下面四种常见的实现方式:BatchAllTripletLoss、BatchHardTripletLoss、BatchSemiHardTripletLoss 和 BatchHardSoftMarginTripletLoss
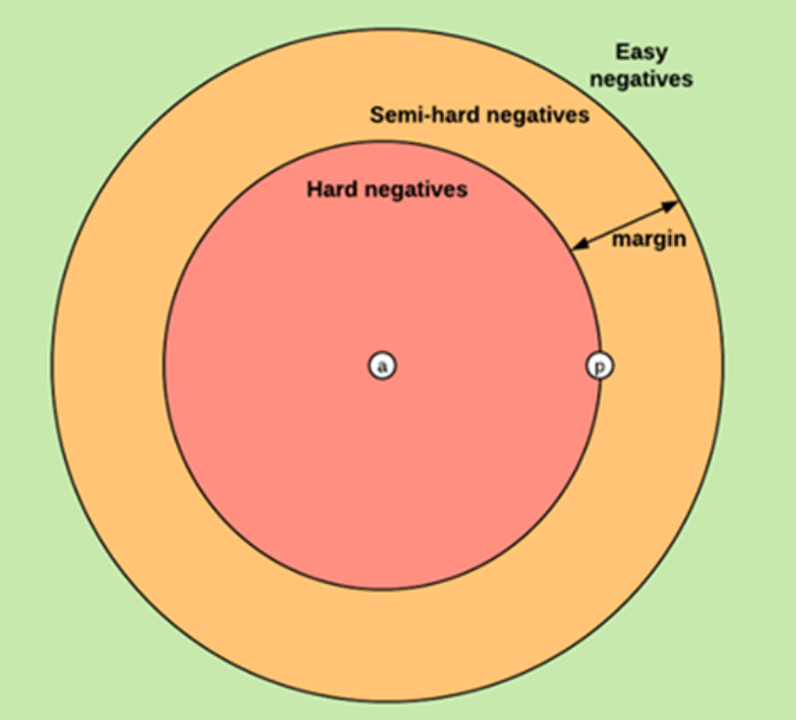
图:三种不同的负样本(摘自https://omoindrot.github.io/triplet-loss)
1. BatchAllTripletLoss
BatchAllTripletLoss 是一种简单的三元组损失实现方式,它会从每个批次中生成所有可能的三元组,并计算每个三元组的损失。
工作原理:
-
生成所有三元组:对于每个批次中的每个样本,将其作为锚点,生成所有可能的正样本和负样本组合。
-
计算损失:对每个生成的三元组计算损失 L=max(0,d(a,p)−d(a,n)+margin)。
-
汇总损失:将所有三元组的损失汇总,作为当前批次的总损失。
优点:
-
简单直观:实现简单,容易理解。
-
充分利用数据:每个批次中的所有样本都被充分利用,生成尽可能多的三元组。
缺点:
-
计算量大:生成的三元组数量非常多,尤其是当批次大小较大时,计算量会显著增加。
-
效率低:很多生成的三元组可能对模型训练帮助不大(例如,那些正样本和负样本距离已经很明显的三元组)。
2. BatchHardTripletLoss
BatchHardTripletLoss 是一种更高效的三元组损失实现方式,它专注于选择“最难”的三元组进行训练。
工作原理:
-
选择最难的正样本:对于每个锚点,选择与其距离最远的正样本(即最难的正样本)。
-
选择最难的负样本:对于每个锚点,选择与其距离最近的负样本(即最难的负样本)。
-
计算损失:只对这些“最难”的三元组计算损失 L=max(0,d(a,p)−d(a,n)+margin)。
-
汇总损失:将所有“最难”三元组的损失汇总,作为当前批次的总损失。
优点:
-
高效:只选择最难的三元组,减少了计算量。
-
针对性强:专注于那些对模型训练最有帮助的三元组,能够更有效地提升模型的判别能力。
缺点:
-
可能过拟合:只选择最难的三元组可能会导致模型对这些特定样本过度拟合,从而陷入局部最优,影响泛化能力。
3. BatchSemiHardTripletLoss
-
BatchSemiHardTripletLoss 是一种折中的方法,它选择“半难”的三元组进行训练,旨在平衡计算效率和训练效果。正样本距离(d(a,p))小于负样本距离(d(a,n)),但差距未超过预设的 margin,: d(a,p)<d(a,n)<d(a,p)+margin
_transformers中的工作原理:
(1)距离矩阵计算
-
计算批次内所有样本的成对距离矩阵 Matrix[i][j],其中:
-
若 label[i] != label[j] 或 i == j,则 Matrix[i][j] = 0(无效三元组)
-
Matrix[i][j] = dist(sample[i], sample[j])(如欧式距离或余弦距离)
(2)正样本距离(d(a,p))
对每个锚点sample[i],其正样本距离为所有与 label[i] 相同的样本距离:
d(a,p)=Matrix[i][j] where label[i]==label[j]
(3)负样本距离(d(a,n))
筛选负样本的逻辑如下:
若不存在满足d(a,p) < d(a,n) 的负样本: 选择最大负样本距离(最易负样本),避免损失为0;
否则:选择最小负样本距离(最近但未超过 d(a,p) + margin 的负样本),即半难样本。
-
计算损失:对这些“半难”的三元组计算损失 L=max(0,d(a,p)−d(a,n)+margin)。
-
汇总损失:将所有“半难”三元组的损失汇总,作为当前批次的总损失。
优点:
-
平衡性:既避免了选择所有三元组的高计算量,又避免了只选择最难三元组可能导致的过拟合问题。
-
效果较好:通过选择“半难”的三元组,能够更全面地训练模型,提升其泛化能力。
缺点:
-
实现复杂:相比 BatchAllTripletLoss,实现起来稍微复杂一些。
-
选择标准:需要合理定义“半难”的标准,否则可能影响训练效果。
4. BatchHardSoftMarginTripletLoss
BatchHardSoftMarginTripletLoss 是一种结合了硬负样本和软间隔的三元组损失实现方式。它在 BatchHardTripletLoss 的基础上引入了软间隔(soft margin),以提高模型的鲁棒性和泛化能力。
工作原理:
-
选择最难的正样本:对于每个锚点,选择与其距离最远的正样本(即最难的正样本)。
-
选择最难的负样本:对于每个锚点,选择与其距离最近的负样本(即最难的负样本)。
-
计算损失:对这些“最难”的三元组计算损失,但引入软间隔。具体公式为: L=log(1+exp(d(a,p)−d(a,n))) 这种损失函数形式更加平滑,避免了硬间隔可能导致的梯度消失问题。
-
汇总损失:将所有“最难”三元组的损失汇总,作为当前批次的总损失。
优点:
-
鲁棒性:软间隔的引入使得模型对异常值和噪声更加鲁棒。
-
泛化能力:通过软间隔,模型能够更好地泛化到未见过的数据。
缺点:
-
实现复杂:相比 BatchHardTripletLoss,实现起来稍微复杂一些。
-
计算量:虽然选择的三元组数量较少,但软间隔的计算可能增加一定的计算量。
提供一个具体示例
以下是一个sentence_transformers 官方文档中 BatchHardSoftMarginTripletLoss 的完整示例,我将为您解读如何在sentence_transformers 中实现三元组损失训练。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, lossesfrom datasets import Datasetmodel = SentenceTransformer("microsoft/mpnet-base")# E.g. 0: sports, 1: economy, 2: politicstrain_dataset = Dataset.from_dict({"sentence": ["He played a great game.","The stock is up 20%","They won 2-1.","The last goal was amazing.","They all voted against the bill.",],"label": [0, 1, 0, 0, 2],})loss = losses.BatchSemiHardTripletLoss(model)trainer = SentenceTransformerTrainer(model=model,train_dataset=train_dataset,loss=loss,)trainer.train()
1.初始化模型
model= SentenceTransformer("microsoft/mpnet-base")这里使用了 microsoft/mpnet-base 预训练模型。你可以根据需要选择其他模型。
2.准备训练数据
train_dataset = Dataset.from_dict({"sentence": ["He played a great game.","The stock is up 20%","They won 2-1.","The last goal was amazing.","They all voted against the bill.",],"label": [0, 1, 0, 0, 2],})
每个句子对应一个标签,表示其类别。
3. 定义损失函数
loss= losses.BatchSemiHardTripletLoss(model,margin=0.3)这里使用了 BatchSemiHardTripletLoss,并且设置margin为0.3。
4. 训练模型
trainer = SentenceTransformerTrainer(model=model,train_dataset=train_dataset,loss=loss,)trainer.train()
调用 trainer.train() 后,会自动完成数据加载、前向传播、损失计算和参数更新,并支持GPU加速和日志记录。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
更多推荐

 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)