
邱锡鹏团队 | 重磅推出 VehicleWorld,Agent函数调用迎来新范式,智能座舱交互难题告破
复旦团队发布智能车辆座舱交互系统VehicleWorld,创新性提出基于状态的函数调用(SFC)方法,有效解决传统函数调用效率低、错误恢复有限的问题。该系统包含30个模块、250个API和680个属性,支持实时状态监控和精确评估。实验表明,SFC方法在准确率上比传统方法提升10%以上,显著减少交互轮次和令牌消耗。该研究为智能座舱系统开发提供了首个综合性评估框架,相关代码已开源。
近日,复旦邱锡鹏团队发布VehicleWorld,今天小编带大家详细解读下这篇力作!
1. 【前言】
智能车辆座舱对API代理构成独特挑战,需协调远超典型任务环境复杂度的紧密耦合子系统。传统函数调用(FC) 方法因无状态运行,需多次探索性调用建立环境感知,存在效率低、错误恢复有限的问题。为此,复旦邱锡鹏团队推出首个汽车领域综合环境VehicleWorld,含30个模块、250个API和680个属性,其可执行实现能提供实时状态信息,支持精确评估车辆代理行为。研究发现直接状态预测优于函数调用,并提出基于状态的函数调用(SFC) 方法,通过维持明确系统状态感知、实现直接状态转换达成目标。
2. 【论文基本信息】

论文基本信息
- 论文标题:VehicleWorld: A Highly Integrated Multi-Device Environment for Intelligent Vehicle Interaction
- 论文作者:复旦邱锡鹏团队
- 作者机构: Fudan University
- 论文链接:https://arxiv.org/pdf/2509.06736
- 项目链接:https://github.com/OpenMOSS/VehicleWorld
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/7ppWq2e4evf8c726FGgbKQ
https://mp.weixin.qq.com/s/7ppWq2e4evf8c726FGgbKQ
3.【背景及相关工作】
3.1 研究背景
-
智能车辆座舱集成了娱乐、导航、车辆诊断、环境控制等众多紧密耦合的子系统,对API代理构成独特挑战,要求代理在协调各系统的同时,保证驾驶员能专注于驾驶。
-
尽管智能座舱代理对现代车辆系统很重要,但该领域缺乏全面的评估框架,无法对其在不同实现中的性能进行系统评估。
-
传统函数调用(FC)方法无状态运行,需通过多次探索性调用建立环境感知,API调用失败时难以恢复,且只能通过有限的API返回信息判断执行结果,可能得出错误结论。

3.2 相关工作
-
工具实用代理:集成工具使用能力可增强代理在复杂环境中的适应性和有效性,但针对智能车辆座舱的专门研究有限,现代车辆座舱已演变为人机交互系统,需要专门研究其设计、用户意图和评估方法。
-
模拟世界:世界模型能增强代理决策能力,可分为基于模型的世界和基于代码的世界。现有相关方法对汽车座舱环境存在局限,如模块间缺乏必要的系统耦合、无法明确表示实时应用状态等。VehicleWorld则提供了具有明确定义的API和直接状态可观测性的可执行智能座舱环境。
-
函数调用:函数调用已成为将大型语言模型转化为有效工具使用代理的关键机制,现有研究多侧重于优化函数调用过程本身,而本文通过基于状态的框架重新概念化工具使用,引入状态透明环境,使代理能直接访问和操作系统状态。
4.【论文主体】
4.1 VehicleWorld
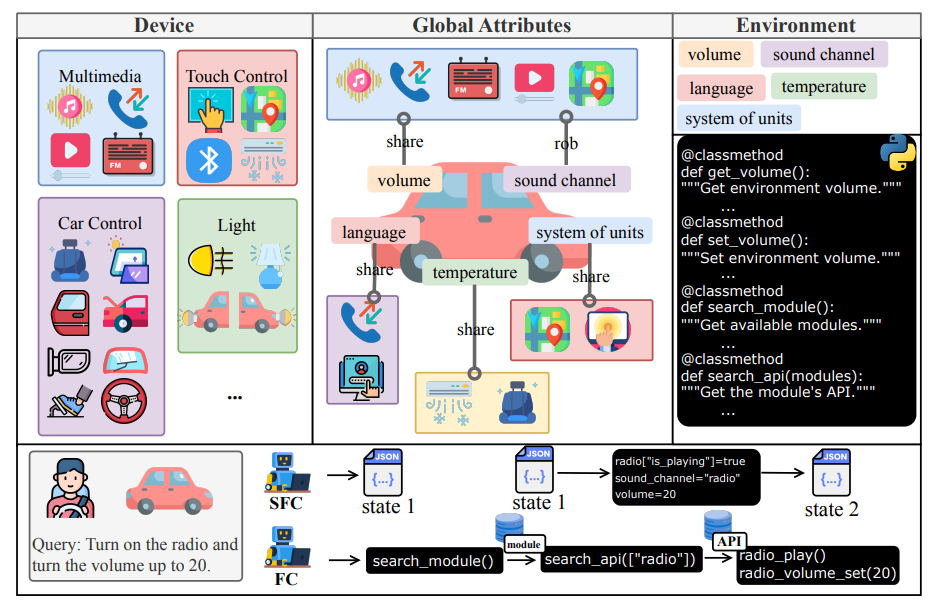
Overview of VehicleWorld
-
设备:选取30种常见设备,涵盖四大领域,抽象为30个模块类,含250个API和680个属性,实现search_module和search_api两个实用API。
-
全局属性:采用单例模式实现全局Environment类,管理系统级属性,设备类通过该接口交互以维持一致性。
-
世界状态:各设备类基于实际模式实现init()方法,生成302种初始化场景,状态信息序列化为JSON文档便于评估。

4.2 State-based Function Call
-
函数调用定义:FC范式中,代理通过生成API调用序列完成任务,函数调用为,需先获取设备及API列表。
-
基于状态的函数调用定义:SFC范式中,代理直接预测目标状态并生成转换代码,状态转换公式为,采用两阶段方法选择设备并生成代码。
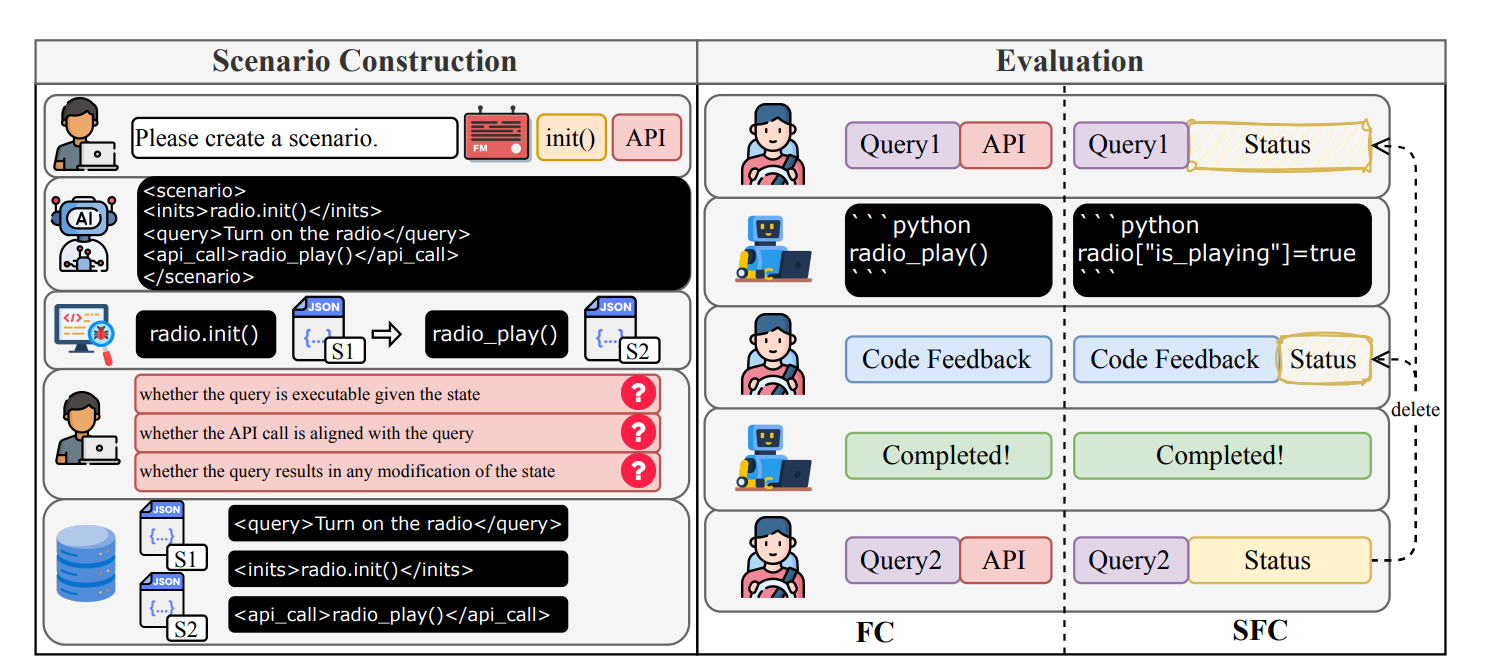
4.3 Vehicle Benchmark
-
设置:基于真实案例构建场景,用HTML标签组织,经自动执行和专家验证后存入数据库。
-
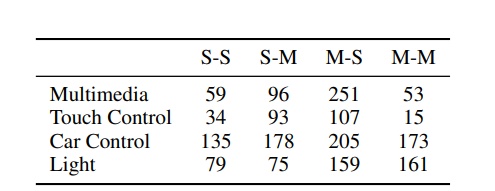
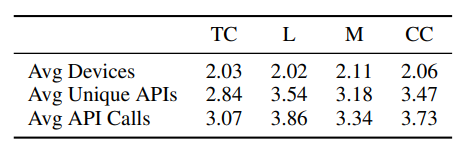
基准数据集:含1291个任务,分四类,平均每个任务涉及超2个设备、4个独特API,复杂场景涉及5个设备和13个API。
-
指标:包括F1 positive(识别需改属性的有效性)、F1 negative(保护不变属性的能力)、Accuracy(正确修改属性的比例)。
5.【实验结果】
5.1 实验设置
-
方法:在函数调用(FC)和基于状态的函数调用(SFC)两种范式下,采用三种基于提示的决策策略:ReAct、ReAct + Reflection、ReAct without Examples。
-
模型:分析了一系列开源和商业模型,包括GPT-4o、Claude-3.7-Sonnet、DeepSeek-v3-250324、Llama-3.1-8B以及Qwen2.5系列等。
5.2 结果对比
-
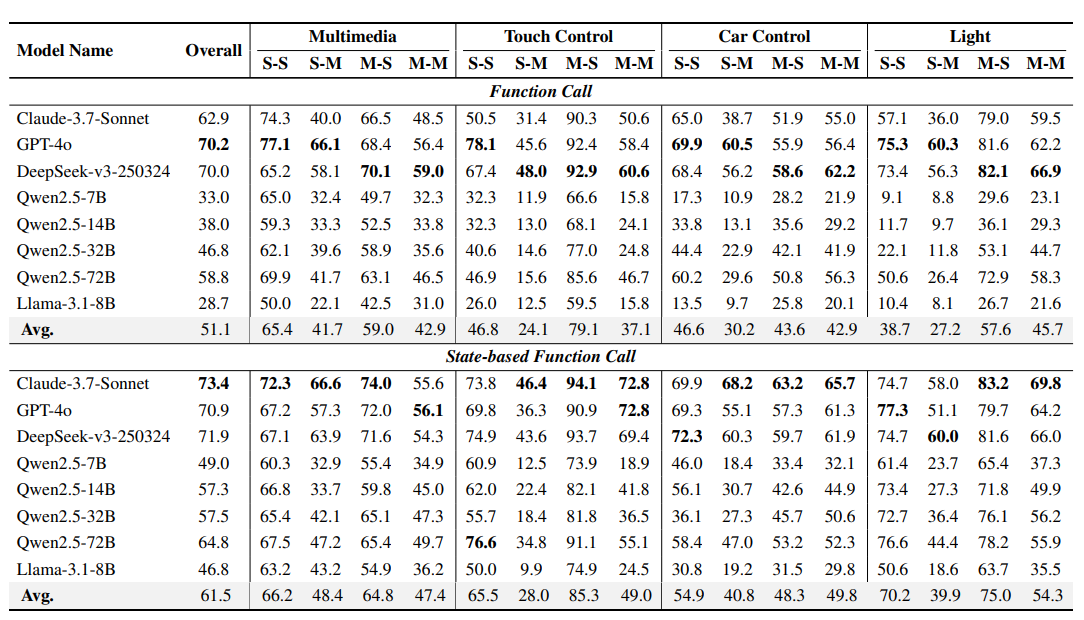
总体表现:在ReAct策略下,所有模型在SFC范式下的表现均优于FC,平均准确率从FC的51.1%提升至SFC的61.5%。
-
模型差异:GPT-4o在FC范式中表现最佳(70.2%),Claude-3.7-Sonnet在SFC范式中表现最佳(73.4%)。
-
领域差异:在触控和汽车控制任务中,SFC的改进最为显著。
-
效率提升:SFC显著减少了交互轮次和生成令牌数量,提高了执行效率。
5.3 结果分析
-
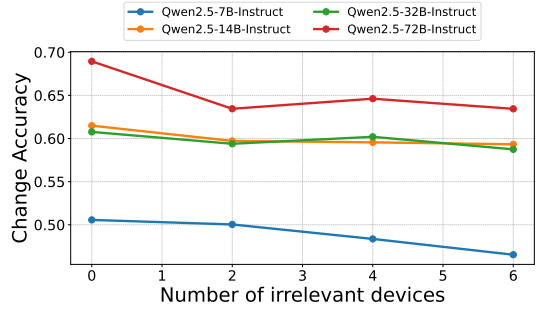
世界复杂性影响:随着世界复杂性增加(通过添加无关设备状态模拟),所有模型性能均下降,较大模型表现出更强的鲁棒性。
-
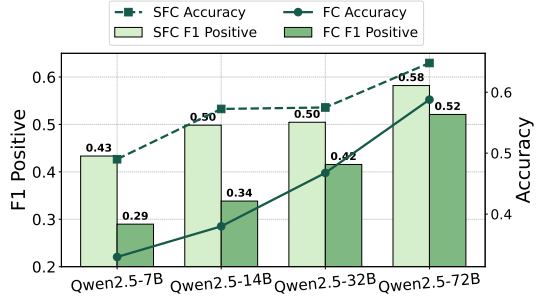
缩放效应:随着Qwen2.5模型参数规模从7B增加到72B,两种方法性能均提升,FC相对增益更大,但SFC在所有模型规模上均优于FC。
-
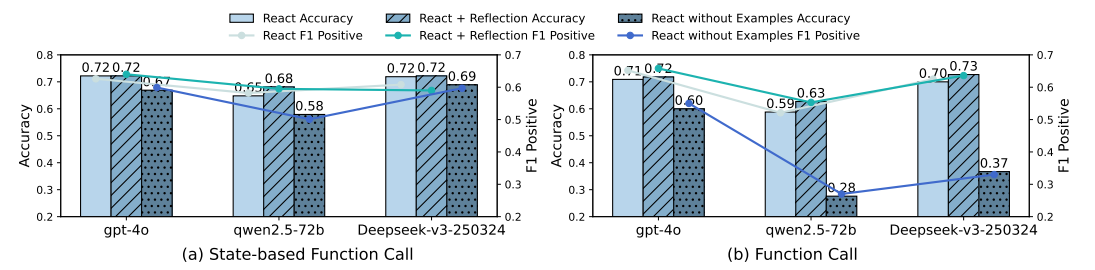
反思和示例的影响:移除上下文示例对FC性能影响更大,SFC对无演示更稳健;添加反思在两种范式中均能持续改进结果。
-
基于状态与基于规则的评估:基于状态的评估在所有模型规模上错误率均更低,更注重任务完成而非严格遵循预设动作序列。
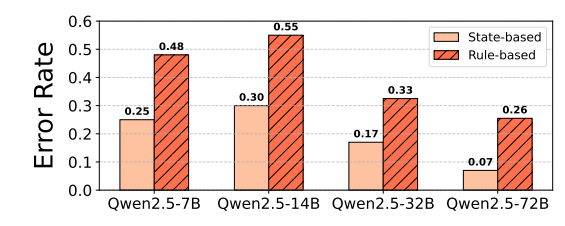
-
推理的影响:在SFC范式中,引入推理会导致所有模型性能下降;在FC范式中,GPT-4o和Claude-3.7-Sonnet性能下降,Qwen2.5-72B性能提升。
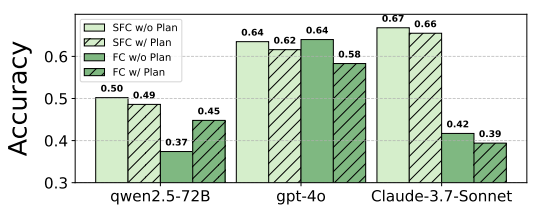
-
FC与SFC的集成:SFC在设备选择准确性上显著优于FC,FC在复杂设备状态下因API封装更高效,FC+SFC混合方法实现了最高的端到端准确率。
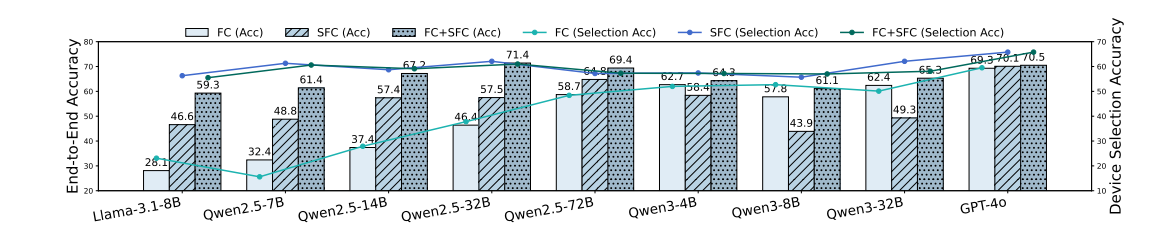
6.【快速上手指南】
6.1 前置条件
conda create -n VehicleWorld python=3.10
conda activate VehicleWorld
pip install -r requirements.txt
6.2 数据构建
cd vehicleworld/database
python task_construct.py
生成的任务将存储至 vehicleworld/database/tasks 目录。
6.3 评估方法
该框架支持多线程执行,并每100个任务自动保存进度。
6.3.1 函数调用(FC)
cd vehicleworld/evaluation
python fc_evaluation.py \
--api_base "https://api.openai.com/v1" \
--api_key "your-api-key" \
--model "gpt-4o" \
--max_workers 8 \
--sample_size 1500 \
--reflect_num 3 \
--prefix "fc_test" \
--sample
6.3.2 基于状态的函数调用(SFC)
cd vehicleworld/evaluation
python sfc_evaluation.py \
--api_base "https://api.openai.com/v1" \
--api_key "your-api-key" \
--model "gpt-4o" \
--max_workers 8 \
--sample_size 1500 \
--reflect_num 0 \
--prefix "sfc_test" \
--sample
6.3.3 FC+SFC混合方法
cd vehicleworld/evaluation
python fc_sfc_evaluation.py \
--api_base "https://api.openai.com/v1" \
--api_key "your-api-key" \
--model "gpt-4o" \
--max_workers 8 \
--sample_size 1500 \
--reflect_num 1 \
--prefix "hybrid_test" \
--sample
6.4 配置参数
| 参数 | 类型 | 默认值 | 是否必需 | 描述 |
|---|---|---|---|---|
| --api_base | str | - | ✅ | API端点URL |
| --api_key | str | - | ✅ | 认证密钥 |
| --model | str | - | ✅ | 模型标识符 |
| --max_workers | int | 4 | ❌ | 并行线程数 |
| --sample_size | int | 50 | ❌ | 评估样本量 |
| --reflect_num | int | 0 | ❌ | 反思迭代次数 |
| --sample | flag | False | ❌ | 启用采样模式 |
| --plan | flag | False | ❌ | 启用规划模式 |
| --prefix | str | "" | ❌ | 输出文件前缀 |
6.5 结果存储
评估结果将保存至 vehicleworld/evaluation/outputs/ 目录。
6.6 开源模型部署
所有开源模型均通过vLLM部署,且为保证评估公平性,统一采用0.7的采样温度。
特殊配置:
-
Qwen2.5:通过YaRN技术将上下文长度扩展至128k
-
Qwen3:通过YaRN扩展上下文长度,且禁用思考模式
该设置确保所有模型类型的评估过程一致且高效。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)