- @LLM_jingjinzhilu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过这套流程,我们把Zotero、Obsidian 和 Codex串联起来,实现了从论文检索、下载、导入 Zotero、分类打标签,到批量精读、生成 Obsidian 笔记,再到基于个人论文库提问和总结的完全自动流程。其中,Zotero 负责管理文献,Obsidian 负责沉淀笔记,Codex 负责自动处理和调用内容。这样,论文不再只是“存起来”,而是真正变成可以持续检索、整理和复用的科研知识库。
整体看下来,5.5 其实已经很厉害了。工业场景、模型结构、实验图表都能做得比较完整,信息也基本到位,放在技术汇报里已经相当能打。但 5.6 带来的提升,确实有点震撼。它不只是把提示词里的内容画出来,而是会主动理解你真正想表达什么。尤其是模型结构图和工业场景图,差距已经不只是“更好看”,而是从能用,直接跨到了接近成品的感觉。当然,自动补全的网络连接和实验数据仍然需要人工核验,但这种理解科研、组织科研
整体看下来,5.5 其实已经很厉害了。工业场景、模型结构、实验图表都能做得比较完整,信息也基本到位,放在技术汇报里已经相当能打。但 5.6 带来的提升,确实有点震撼。它不只是把提示词里的内容画出来,而是会主动理解你真正想表达什么。尤其是模型结构图和工业场景图,差距已经不只是“更好看”,而是从能用,直接跨到了接近成品的感觉。当然,自动补全的网络连接和实验数据仍然需要人工核验,但这种理解科研、组织科研
整体看下来,5.5 其实已经很厉害了。工业场景、模型结构、实验图表都能做得比较完整,信息也基本到位,放在技术汇报里已经相当能打。但 5.6 带来的提升,确实有点震撼。它不只是把提示词里的内容画出来,而是会主动理解你真正想表达什么。尤其是模型结构图和工业场景图,差距已经不只是“更好看”,而是从能用,直接跨到了接近成品的感觉。当然,自动补全的网络连接和实验数据仍然需要人工核验,但这种理解科研、组织科研
通过这套流程,我们把Zotero、Obsidian 和 Codex串联起来,实现了从论文检索、下载、导入 Zotero、分类打标签,到批量精读、生成 Obsidian 笔记,再到基于个人论文库提问和总结的完全自动流程。其中,Zotero 负责管理文献,Obsidian 负责沉淀笔记,Codex 负责自动处理和调用内容。这样,论文不再只是“存起来”,而是真正变成可以持续检索、整理和复用的科研知识库。
通过这套流程,我们把Zotero、Obsidian 和 Codex串联起来,实现了从论文检索、下载、导入 Zotero、分类打标签,到批量精读、生成 Obsidian 笔记,再到基于个人论文库提问和总结的完全自动流程。其中,Zotero 负责管理文献,Obsidian 负责沉淀笔记,Codex 负责自动处理和调用内容。这样,论文不再只是“存起来”,而是真正变成可以持续检索、整理和复用的科研知识库。
通过这套流程,我们把Zotero、Obsidian 和 Codex串联起来,实现了从论文检索、下载、导入 Zotero、分类打标签,到批量精读、生成 Obsidian 笔记,再到基于个人论文库提问和总结的完全自动流程。其中,Zotero 负责管理文献,Obsidian 负责沉淀笔记,Codex 负责自动处理和调用内容。这样,论文不再只是“存起来”,而是真正变成可以持续检索、整理和复用的科研知识库。
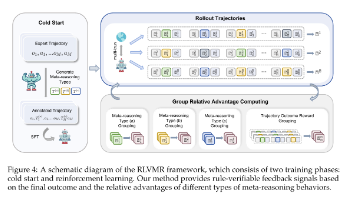
RLVMR 提出了一类全新的奖励设计方式,不再依赖稀疏或延迟的环境反馈,而是将智能体的推理过程转化为“可验证”的奖励信号。这样一来,模型的学习过程不仅更稳定,而且具备明确的解释性,避免了传统 RL 中“只看结果”的局限。本文提出了 RLVMR(Reinforcement Learning with Verifiable Meta-Reasoning Rewards) 框架,通过将可验证的元推理信号
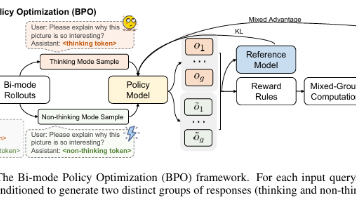
本研究提出R-4B,一种具备自动思考能力的多模态大语言模型,可根据问题复杂度自适应选择"思考"或"直接回答"模式。创新性地采用双模态退火训练策略使模型掌握两种能力,并通过双模态策略优化算法解决"思维萎缩"问题。实验表明,R-4B在25个基准测试中达到SOTA性能,同时显著降低简单任务的计算开销,在效率与性能间取得平衡。该研究为开发智能高效
本文提出CURATE算法,解决强化学习在稀疏奖励环境中的探索难题。该算法通过动态调整任务难度匹配智能体能力,将课程生成转化为环境参数空间的策略搜索。实验表明,CURATE在样本效率上超越多种先进基线,尤其在最优路径不明确的多维课程空间中表现突出,展现了自动发现高效学习路径的能力。研究为复杂场景下的自动课程学习提供了新思路,未来可扩展至更高维空间和连续控制领域。