
LangGraph终极实战!让AI像人类一样思考:记忆+暂停+断点恢复全攻略,2025开发者必藏
在上一节我们已经完成了一个可正常运行的 LangGraph 智能体框架,能够根据需求调用外部工具,并按既定流程完成任务。
前言
在上一节我们已经完成了一个可正常运行的 LangGraph 智能体框架,能够根据需求调用外部工具,并按既定流程完成任务。
然而,在实际的智能体应用中,仅仅保证功能运行正确远远不够。如果我们希望智能体真正能够融入长期对话、持续工作,并且在与用户交互时更加流畅自然,就必须重点解决两个核心能力:
- **对话状态的持久化保存:**让智能体具备“记忆力”,能够将过去的对话轨迹和中间步骤保存下来,即便中途进程中断或跨会话调用,也可以从断点继续运行。这种能力不仅对长任务执行至关重要,也是多轮对话保持上下文一致性的前提。
- **模型响应的流式输出:**让智能体在生成回答时能够“边想边说”,实时将生成的内容流式发送给用户,而不是等到一次性生成完毕才输出。这样既能提升用户体验,也有利于在长文本生成或中间步骤中更早发现并纠正问题。
本节课,我们将围绕 LangGraph 的断点恢复机制(Checkpointing) 和 状态流式展示(Streaming) 展开。你将学习如何将对话状态持久化到 SQLite 数据库,借助 thread_id 实现对话上下文恢复,并通过 graph.stream() 追踪每一步的执行状态,甚至实现人工介入(Human-in-the-loop)来控制智能体的行为。
这些能力不仅能让你的智能体更稳、更聪明,还能为后续实现更复杂的任务编排和人机协同打下坚实基础。
代码实战
环境及代码准备
那我们这节课是在上一节课代码的基础上进行进一步的改进,因此也请准备好我们上节课的代码内容以及环境,进行下面课程的学习。
假如还没有安装的,可以在安装anconda后输入以下指令进行安装:
conda create -n langgraph python=3.12 -y
conda activate langgraph
pip install langgraph langchain langchain-openai langchain-community openai pygraphviz langgraph-checkpoint-sqlite
上节课完整的代码内容如下所示,强烈推荐还没有看过上期文章的朋友先看完上期文章的内容再进行本节课的学习:
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated, Type
import operator
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, PrivateAttr
from langchain_core.tools import BaseTool
import requests
# ----------------------------- Tool 定义 -----------------------------
classBoChaSearchInput(BaseModel):
query: str = Field(..., description="搜索的查询内容")
classBoChaSearchResults(BaseTool):
name: str = "bocha_web_search"
description: str = "使用博查API进行网络搜索,可用来查找实时信息或新闻"
args_schema: Type[BaseModel] = BoChaSearchInput
_api_key: str = PrivateAttr()
_count: int = PrivateAttr()
_summary: bool = PrivateAttr()
_freshness: str = PrivateAttr()
def__init__(self, api_key: str, count: int = 5, summary: bool = True, freshness: str = "noLimit", **kwargs):
super().__init__(**kwargs)
self._api_key = api_key
self._count = count
self._summary = summary
self._freshness = freshness
def_run(self, query: str) -> str:
url = "https://api.bochaai.com/v1/web-search"
headers = {
"Authorization": f"Bearer {self._api_key}",
"Content-Type": "application/json"
}
payload = {
"query": query,
"summary": self._summary,
"freshness": self._freshness,
"count": self._count
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=10)
response.raise_for_status()
data = response.json()
results = data.get("data", {}).get("webPages", {}).get("value", [])
ifnot results:
returnf"\u672a\u627e\u5230\u76f8\u5173\u5185\u5bb9\u3002\n[DEBUG] \u8fd4\u56de\u6570\u636e\uff1a{data}"
output = ""
for i, item in enumerate(results[:self._count]):
title = item.get("name", "\u65e0\u6807\u9898")
snippet = item.get("snippet", "\u65e0\u6458\u8981")
url = item.get("url", "")
output += f"{i+1}. {title}\n{snippet}\n\u94fe\u63a5: {url}\n\n"
return output.strip()
except Exception as e:
returnf"\u641c\u7d22\u5931\u8d25: {e}"
# ----------------------------- 智能体状态定义 -----------------------------
classAgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
# ----------------------------- Agent 实现 -----------------------------
classAgent:
def__init__(self, model, tools, system=""):
self.system = system
graph = StateGraph(AgentState)
graph.add_node("llm", self.call_openai)
graph.add_node("action", self.take_action)
graph.add_conditional_edges("llm", self.exists_action, {True: "action", False: END})
graph.add_edge("action", "llm")
graph.set_entry_point("llm")
self.graph = graph.compile()
self.tools = {t.name: t for t in tools}
self.model = model.bind_tools(tools)
defexists_action(self, state: AgentState):
result = state['messages'][-1]
return len(result.tool_calls) > 0
defcall_openai(self, state: AgentState):
messages = state['messages']
if self.system:
messages = [SystemMessage(content=self.system)] + messages
message = self.model.invoke(messages)
return {'messages': [message]}
deftake_action(self, state: AgentState):
tool_calls = state['messages'][-1].tool_calls
results = []
for t in tool_calls:
print(f"Calling: {t}")
ifnot t['name'] in self.tools:
print("\n ....bad tool name....")
result = "bad tool name, retry"
else:
result = self.tools[t['name']].invoke(t['args'])
results.append(ToolMessage(tool_call_id=t['id'], name=t['name'], content=str(result)))
print("Back to the model!")
return {'messages': results}
# ----------------------------- 模型和启动 -----------------------------
prompt = """\
你是一名聪明的科研助理。可以使用搜索引擎查找信息。
你可以多次调用搜索(可以一次性调用,也可以分步骤调用)。
只有当你确切知道要找什么时,才去检索信息。
如果在提出后续问题之前需要先检索信息,你也可以这样做!
"""
aliyun_api_key = '你的api_key'
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=aliyun_api_key,
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
tool = BoChaSearchResults(api_key="你的api_key", count=4)
abot = Agent(model, [tool], system=prompt)
# 绘制当前的 Graph
# ascii_diagram = abot.graph.get_graph().draw_ascii()
# print(ascii_diagram)
# ----------------------------- 测试使用 -----------------------------
messages = [HumanMessage(content="What is the weather in sf?")]
result = abot.graph.invoke({"messages": messages})
print(result['messages'][-1].content)
断点恢复机制:LangGraph 的 Checkpoint 系统
在构建基于 LangGraph 的智能体流程时,我们常常会遇到两个关键问题:如何保存流程执行中的中间状态?以及如何让智能体在不同运行阶段之间“记住”之前发生的事情?
LangGraph 提供了非常优雅的解决方案:断点恢复机制(Checkpoint)与流程记忆结构(AgentState)。通过将状态信息保存到 SQLite 数据库中,我们不仅能够在流程中断后继续执行,还能构建起一种“线程级”的长期记忆机制,帮助智能体在多轮交互中保持上下文一致性。
本节我们将系统介绍如何使用 SqliteSaver 持久化保存流程状态,并借助 thread_id 恢复对话上下文,构建具备记忆能力的智能体。
创建数据库
那为了能够让我们之前创建好的Agent框架加入断点恢复的机制,首先第一步我们就需要去配置好SqliteSaver 的工具到我们的框架之中。我们可以从LangGraph中导入该部分内容,代码如下所示:
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:")
这里我们重点关注的就是括号里面的内容(":memory:") 。这是 SQLite 的一个特殊关键字,其作用是创建一个 临时的内存数据库,不会保存到磁盘中,Python 程序一退出,数据就全部消失。这个对于测试的环境下比较好用,因为运行完就删除,不占内存。但是对于实际的生产环境下,我们尽可能还是将数据库保存在本地,这样就能真正产生了长期保存过程资料的能力。
具体实现的方式如下:
from langgraph.checkpoint.sqlite import SqliteSaver
import os
# 设置保存路径:保存在当前目录下的 checkpoints.db 文件
db_path = os.path.abspath("checkpoints.db")
db_uri = f"sqlite:///{db_path}"
# 初始化一个真正写入磁盘的 SqliteSaver
memory = SqliteSaver.from_conn_string(db_uri)
我们首先设置好数据库的路径,目前这段代码设置的路径是终端路径下的checkpoints.db 文件,假如我们有特殊的需要也可以进行修改,比如设置为绝对路径D:\langchain\LangGraph\checkpoints.db 也是可以的。然后呢就可以写成sqlite里支持的路径写法并传入到memroy中。
但是这个方法在实际运行中会出现以下报错:
Traceback (most recent call last):
File "D:\langchain\LangGraph\lesson3.py", line 143, in <module>
result = abot.graph.invoke(
^^^^^^^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\__init__.py", line 2844, in invoke
for chunk in self.stream(
^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\__init__.py", line 2467, in stream
with SyncPregelLoop(
^^^^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\loop.py", line 930, in __init__
self.checkpointer_get_next_version = checkpointer.get_next_version
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: '_GeneratorContextManager' object has no attribute 'get_next_version'
主要问题是from_conn_string 是一个 @contextmanager(比如早期的实现),它返回的不是 SqliteSaver 实例,而是一个 _GeneratorContextManager。这个对象没有 .get_next_version() 方法,于是 LangGraph 在运行时就会报你遇到的这个错:
AttributeError: '_GeneratorContextManager' object has no attribute 'get_next_version'
因此呢我们可以尝试不要直接用 .from_conn_string(),而是手动构造 SqliteSaver:
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
db_path = os.path.abspath("checkpoints.db")
conn = sqlite3.connect(db_path, check_same_thread=False)
memory = SqliteSaver(conn)
这样我们的 memory 对象就具备 LangGraph 所需的所有方法,不会再出现 .get_next_version 报错了。
其实这也反映出为什么我们在学习某些框架的过程中也要了解具体其实现的方法及流程,一个框架可能会简化我们很多的学习步骤,但同样的其也会让我们忽略掉很多重要的内容。因此除了学习框架以外,我们还需要补充很多的知识和内容,比如学习RAG的时候不单纯是学习LangChain,而是真正的了解一下原生的Chorma或者FAISS这些库的内容,当我们遇到问题的时候真的是会很有帮助的。
载入到Agent框架中
当我们配置好了一个数据库后,我们就需要真正的将其载入到Agent框架当中。载入的方式其实也非常简单,首先我们需要在Agent类的构造函数(def **init**)里添加一个参数checkpointer,然后把checkpointer载入到self.graph = graph.compile()这个之中变成self.graph = graph.compile(checkpointer=checkpointer)。修改后的构造函数如下所示:
classAgent:
def__init__(self, model, tools, checkpointer, system=""):
self.system = system
graph = StateGraph(AgentState)
graph.add_node("llm", self.call_openai)
graph.add_node("action", self.take_action)
graph.add_conditional_edges("llm", self.exists_action, {True: "action", False: END})
graph.add_edge("action", "llm")
graph.set_entry_point("llm")
self.graph = graph.compile(checkpointer=checkpointer)
self.tools = {t.name: t for t in tools}
self.model = model.bind_tools(tools)
然后我们在创建一个Agent实例的时候,我们需要传入其他参数的同时也将刚刚创建好的sqlite实例传入,也就是我们的变量memory 。
abot = Agent(model, [tool], system=prompt, checkpointer=memory)
这样我们就完成了所有的配置啦,接下来就可以进行实际的调用了!
实际调用
当我们创建好了以后,理论上说,我们可以直接使用之前的代码进行对话了:
messages = [HumanMessage(content="What is the weather in sf?")]
result = abot.graph.invoke({"messages": messages})
print(result['messages'][-1].content)
但是一运行我们会发现其弹出了一条报错:
Traceback (most recent call last):
File "D:\langchain\LangGraph\lesson3.py", line 143, in <module>
result = abot.graph.invoke({"messages": messages})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\__init__.py", line 2844, in invoke
for chunk in self.stream(
^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\__init__.py", line 2428, in stream
) = self._defaults(
^^^^^^^^^^^^^^^
File "C:\Users\76391\anaconda3\envs\langgraph\Lib\site-packages\langgraph\pregel\__init__.py", line 2322, in _defaults
raise ValueError(
ValueError: Checkpointer requires one or more of the following 'configurable' keys: thread_id, checkpoint_ns, checkpoint_id
这个报错意思是:
你在使用 Checkpointer 时,必须指定至少一个可配置标识符(configurable key)来标记这次运行。最常用的是:
thread_id:流程线程的唯一 ID(推荐!)checkpoint_id:单次调用 IDcheckpoint_ns:命名空间
假如不添加thread_id的话, LangGraph 不知道该把保存的状态归档到哪里。因此我们需要把这行代码:
result = abot.graph.invoke({"messages": messages})
修改为:
result = abot.graph.invoke(
{"messages": messages},
config={"configurable": {"thread_id": "user-001"}}
)
当然这里的thread_id名称”user-001”是可以根据我们喜欢的名称进行修改的,比如我就可以修改为”Lesson3”这样。
result = abot.graph.invoke(
{"messages": messages},
config={"configurable": {"thread_id": "Lesson3"}}
)
这样我们再次运行代码的时候就能看到正常的输出信息了。而且我们还能够在文件夹中看到checkpoints.db文件已经生成了。
当我们使用了数据库后,其实就意味着模型拥有了长期的记忆力。这个时候我们只需要修改问题询问别的城市,即便我们没有说是查询天气的信息,其一样回去查询广州的天气。
# 第一次询问
# messages = [HumanMessage(content="What is the weather in sf?")]
# 第二次询问
messages = [HumanMessage(content="What about Guangzhou?")]
可以看到,我们问的问题里面是没有说到任何和weather相关的内容,但是其还是调用了bocha_web_search工具去搜索广州当前的weather情况,因此可以看到过去的聊天记录确实根据我们的thread_id存放在.db文件当中了。
假如我们这个时候修改一下thread_id然后传入这个问题进去,我们会发现模型并不会调用工具搜索广州的天气,而是询问我们到底要干嘛,了解广州的什么,因此我们可以看到设置sqlite实际上是帮助我们的Agent搭建了长期的记忆,可以一直保留下来聊天记录的信息。当我们需要重新开一个窗口的时候,我们就可以通过更换thread_id来重置记忆
该部分完整的代码如下所示:
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
import os
db_path = os.path.abspath("checkpoints.db")
conn = sqlite3.connect(db_path, check_same_thread=False)
memory = SqliteSaver(conn)from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated, Type
import operator
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, PrivateAttr
from langchain_core.tools import BaseTool
import requests
# ----------------------------- Tool 定义 -----------------------------
classBoChaSearchInput(BaseModel):
query: str = Field(..., description="搜索的查询内容")
classBoChaSearchResults(BaseTool):
name: str = "bocha_web_search"
description: str = "使用博查API进行网络搜索,可用来查找实时信息或新闻"
args_schema: Type[BaseModel] = BoChaSearchInput
_api_key: str = PrivateAttr()
_count: int = PrivateAttr()
_summary: bool = PrivateAttr()
_freshness: str = PrivateAttr()
def__init__(self, api_key: str, count: int = 5, summary: bool = True, freshness: str = "noLimit", **kwargs):
super().__init__(**kwargs)
self._api_key = api_key
self._count = count
self._summary = summary
self._freshness = freshness
def_run(self, query: str) -> str:
url = "https://api.bochaai.com/v1/web-search"
headers = {
"Authorization": f"Bearer {self._api_key}",
"Content-Type": "application/json"
}
payload = {
"query": query,
"summary": self._summary,
"freshness": self._freshness,
"count": self._count
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=10)
response.raise_for_status()
data = response.json()
results = data.get("data", {}).get("webPages", {}).get("value", [])
ifnot results:
returnf"\u672a\u627e\u5230\u76f8\u5173\u5185\u5bb9\u3002\n[DEBUG] \u8fd4\u56de\u6570\u636e\uff1a{data}"
output = ""
for i, item in enumerate(results[:self._count]):
title = item.get("name", "\u65e0\u6807\u9898")
snippet = item.get("snippet", "\u65e0\u6458\u8981")
url = item.get("url", "")
output += f"{i+1}. {title}\n{snippet}\n\u94fe\u63a5: {url}\n\n"
return output.strip()
except Exception as e:
returnf"\u641c\u7d22\u5931\u8d25: {e}"
# ----------------------------- 智能体状态定义 -----------------------------
classAgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
# ----------------------------- Agent 实现 -----------------------------
classAgent:
def__init__(self, model, tools, checkpointer, system=""):
self.system = system
graph = StateGraph(AgentState)
graph.add_node("llm", self.call_openai)
graph.add_node("action", self.take_action)
graph.add_conditional_edges("llm", self.exists_action, {True: "action", False: END})
graph.add_edge("action", "llm")
graph.set_entry_point("llm")
self.graph = graph.compile(checkpointer=checkpointer)
self.tools = {t.name: t for t in tools}
self.model = model.bind_tools(tools)
defexists_action(self, state: AgentState):
result = state['messages'][-1]
return len(result.tool_calls) > 0
defcall_openai(self, state: AgentState):
messages = state['messages']
if self.system:
messages = [SystemMessage(content=self.system)] + messages
message = self.model.invoke(messages)
return {'messages': [message]}
deftake_action(self, state: AgentState):
tool_calls = state['messages'][-1].tool_calls
results = []
for t in tool_calls:
print(f"Calling: {t}")
ifnot t['name'] in self.tools:
print("\n ....bad tool name....")
result = "bad tool name, retry"
else:
result = self.tools[t['name']].invoke(t['args'])
results.append(ToolMessage(tool_call_id=t['id'], name=t['name'], content=str(result)))
print("Back to the model!")
return {'messages': results}
# ----------------------------- 模型和启动 -----------------------------
prompt = """
你是一名聪明的科研助理。可以使用搜索引擎查找信息。
你可以多次调用搜索(可以一次性调用,也可以分步骤调用)。
只有当你确切知道要找什么时,才去检索信息。
如果在提出后续问题之前需要先检索信息,你也可以这样做!
"""
aliyun_api_key = '你的api_key'
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=aliyun_api_key,
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
tool = BoChaSearchResults(api_key="你的api_key", count=4)
abot = Agent(model, [tool], system=prompt, checkpointer=memory)
# 绘制当前的 Graph
# ascii_diagram = abot.graph.get_graph().draw_ascii()
# print(ascii_diagram)
# ----------------------------- 测试使用 -----------------------------
# 第一次询问
# messages = [HumanMessage(content="What is the weather in sf?")]
# 第二次询问
messages = [HumanMessage(content="What about Guangzhou?")]
result = abot.graph.invoke(
{"messages": messages},
config={"configurable": {"thread_id": "3"}}
)
print(result['messages'][-1].content)
LangGraph 的状态流
在上一部分,我们看到了使用数据库的方式将我们所有的对话信息存储成为了可能,那为了能够更加精确的控制AI Agent的运行,我们需要了解每一个节点是如何被依次执行、状态是如何在节点之间流动的。这也是我们深入掌握智能体行为逻辑的关键。而 graph.stream() 方法正是 LangGraph 提供的核心接口之一,用于“逐步追踪流程执行状态”。它不仅是调试复杂流程时的重要工具,也是实现状态可解释性和行为可控性的基础。
graph.stream() 方法使用
其实使用graph.stream()这个方法非常简单,我们其实只需要做一件事情,就是把原本的调用方法:
messages = [HumanMessage(content="What about Guangzhou?")]
result = abot.graph.invoke(
{"messages": messages},
config={"configurable": {"thread_id": "3"}}
)
print(result['messages'][-1].content)
替换成:
messages = [HumanMessage(content="What is the weather in sf?")]
thread = {"configurable": {"thread_id": "2"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
这样我们就能够将所有的过程性的信息都打印出来,包括两次的AIMessage和一次的ToolMessage,并且这些信息也是依次打印出来的:
[AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d142822160cc463ea23890', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 238, 'total_tokens': 263, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-8ae5c7bc-6077-9faa-8e8f-4b5941a44db3', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--0584d6a9-188c-465f-ad2a-d8b3c7c760fb-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d142822160cc463ea23890', 'type': 'tool_call'}], usage_metadata={'input_tokens': 238, 'output_tokens': 25, 'total_tokens': 263, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
Calling: {'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d142822160cc463ea23890', 'type': 'tool_call'}
Back to the model!
[ToolMessage(content='1. San Francisco, California, United States current weather conditions and forecast\n47°F / 8°C Feels like 44.10°F / 7°C Wind: West at 6 mph / 9 km/h Humidity: 86% Pressure: 30 inches /\n链接: https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959\n\n2. Weather for San Francisco, California, USA\nNow 16 °C Passing clouds. Feels Like: 16 °C Forecast: 15 / 9 °C Wind: 11 km/h ↑ from Southwest Locat\n链接: https://www.timeanddate.com/weather/usa/san-francisco\n\n3. San Francisco Weather\nRadar/Satellite images courtesy of NOAA/NWS and Weather Underground . Summary / Temperature Wind Rai\n链接: http://zwilnik.net/wx/wxindex.php\n\n4. San Francisco (United States of America) weather - Met Office\nRELEASE CANDIDATE This is a test website - some features and links may not work, and data may be inc\n链接: https://wwwpre.metoffice.gov.uk/weather/forecast/9q8yym8kr', name='bocha_web_search', tool_call_id='call_d142822160cc463ea23890')]
[AIMessage(content='当前旧金山的天气情况如下:\n\n- **温度**: 47°F (8°C),体感温度 44.10°F (7°C)\n- **风速**: 西风 6 mph (9 km/h)\n- **湿度**: 86%\n- **气压**: 30 英寸\n\n另一个来源显示:\n- **当前温度**: 16°C\n- **天气**: 多云\n- **体感温度**: 16°C\n- **风速**: 11 km/h(西南风)\n\n更多天气信息可以参考:[天气预报链接](https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959)', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 154, 'prompt_tokens': 540, 'total_tokens': 694, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-504d9ef0-7f97-910b-8d01-4cd8a4903f39', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--ceebc51c-4916-49a7-aae7-cd64e5e959f7-0', usage_metadata={'input_tokens': 540, 'output_tokens': 154, 'total_tokens': 694, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
我们可以看到第一次的AIMessage其实就是输出一个执行工具的函数,然后第二部分的ToolMessage就是返回执行后的结果,最后的AIMessage就是根据执行的结果来返回我们所需要的信息。这样就构成了我们一次简单的查询。
实现人工介入(Human in loops)
那既然我们通过graph.stream()实现了将每一步的信息都打印出来,那我们有没有可能在某些行为后实现人为的介入呢?其实也是可以的,只不过我们需要修改一下构造函数里的以下内容:
self.graph = graph.compile(checkpointer=checkpointer)
修改为:
self.graph = graph.compile(
checkpointer=checkpointer,
interrupt_before=["action"]
)
这里的interrupt_before=["action"]其实就代表每次在真正执行函数的时候都要停下来,直到同意了才能够继续去执行。这里我建议大家在Juypter Notebook上执行会比较方便一些,因为在.py文件里运行的话都是从头再来这样,但是这里我也是按着.py文件执行的方式来给大家进行演示。
接下来呢我们可以以同样的问题运行一下这部分代码,但是注意我们这里可以给一个新的thread_id以开启新的聊天,以避免受到之前聊天记录的影响。
messages = [HumanMessage(content="Whats the weather in SF?")]
thread = {"configurable": {"thread_id": "11"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
这个时候我们发现此事终端回复的内容并不再是两个AIMessage和一个ToolMessage了,而是有一个HumanMessage和一个AIMessage的信息。这就意味着Agent收到了指示,在执行Action之前停了下来:
(langgraph) PS D:\langchain\LangGraph> python D:\langchain\LangGraph\lesson3.py
{'messages': [HumanMessage(content='Whats the weather in SF?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d2cd50da1a864cefbe13e3', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 241, 'total_tokens': 266, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-e1a02e77-8bd2-9a90-95a4-aa4acb0d0849', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--b9cddaca-3aee-4842-a07e-887e28964a8d-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 241, 'output_tokens': 25, 'total_tokens': 266, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
{'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d2cd50da1a864cefbe13e3', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 241, 'total_tokens': 266, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-e1a02e77-8bd2-9a90-95a4-aa4acb0d0849', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--b9cddaca-3aee-4842-a07e-887e28964a8d-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 241, 'output_tokens': 25, 'total_tokens': 266, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
()
我们可以注释掉刚刚调用的这段代码,然后输入新的代码来看看当前的聊天记录里包含了哪些信息。这个时候我们需要用到的就是graph.get_state(thread) 的方法,去提取当前的聊天记录信息:
messages = [HumanMessage(content="Whats the weather in SF?")]
thread = {"configurable": {"thread_id": "11"}}
# for event in abot.graph.stream({"messages": messages}, thread):
# for v in event.values():
# print(v)
print(abot.graph.get_state(thread))
这个时候就可以显示出来当前的聊天记录,其实也就是上面打印出来部分的信息:
(langgraph) PS D:\langchain\LangGraph> python D:\langchain\LangGraph\lesson3.py
StateSnapshot(values={'messages': [HumanMessage(content='Whats the weather in SF?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d2cd50da1a864cefbe13e3', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 241, 'total_tokens': 266, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-e1a02e77-8bd2-9a90-95a4-aa4acb0d0849', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--b9cddaca-3aee-4842-a07e-887e28964a8d-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 241, 'output_tokens': 25, 'total_tokens': 266, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}, next=('action',), config={'configurable': {'thread_id': '11', 'checkpoint_ns': '', 'checkpoint_id': '1f06c4e4-3a6f-66d2-8001-fbfc342bbe78'}}, metadata={'source': 'loop', 'step': 1, 'parents': {}}, created_at='2025-07-29T07:33:04.674990+00:00', parent_config={'configurable': {'thread_id': '11', 'checkpoint_ns': '', 'checkpoint_id': '1f06c4e4-2962-6cd0-8000-9dca23f21cd2'}}, tasks=(PregelTask(id='77709f64-cec6-ae14-a8a3-19712f3cb42d', name='action', path=('__pregel_pull', 'action'), error=None, interrupts=(), state=None, result=None),), interrupts=())
可以看到现在是停在了AIMessage这一步,我们可以使用.next的方法看看其下一步是要干什么:
messages = [HumanMessage(content="Whats the weather in SF?")]
thread = {"configurable": {"thread_id": "11"}}
# for event in abot.graph.stream({"messages": messages}, thread):
# for v in event.values():
# print(v)
# print(abot.graph.get_state(thread))
print(abot.graph.get_state(thread).next)
这时候系统回复的是要去执行action任务:
('action',)
那对于执行action任务而言,我们其实是不需要再输入问题进去的,只需要传入同样的thread_id让其执行即可,因此这个时候我们的调用应该是下面的命令(没有信息传入进去的时候使用的是None):
messages = [HumanMessage(content="Whats the weather in SF?")]
thread = {"configurable": {"thread_id": "11"}}
# for event in abot.graph.stream({"messages": messages}, thread):
# for v in event.values():
# print(v)
# print(abot.graph.get_state(thread))
# print(abot.graph.get_state(thread).next)
for event in abot.graph.stream(None, thread):
for v in event.values():
print(v)
那这个时候就开始执行任务并继续下去了,可以看到其调用了工具,然后根据工具的内容给出最后的回复后就结束了:
(langgraph) PS D:\langchain\LangGraph> python D:\langchain\LangGraph\lesson3.py
Calling: {'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}
Back to the model!
{'messages': [ToolMessage(content='1. San Francisco, California, United States current weather conditions and forecast\n47°F / 8°C Feels like 44.10°F / 7°C Wind: West at 6 mph / 9 km/h Humidity: 86% Pressure: 30 inches /\n链接: https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959\n\n2. Weather for San Francisco, California, USA\nNow 16 °C Passing clouds. Feels Like: 16 °C Forecast: 15 / 9 °C Wind: 11 km/h ↑ from Southwest Locat\n链接: https://www.timeanddate.com/weather/usa/san-francisco\n\n3. San Francisco Weather\nRadar/Satellite images courtesy of NOAA/NWS and Weather Underground . Summary / Temperature Wind Rai\n链接: http://zwilnik.net/wx/wxindex.php\n\n4. San Francisco (United States of America) weather - Met Office\nRELEASE CANDIDATE This is a test website - some features and links may not work, and data may be inc\n链接: https://wwwpre.metoffice.gov.uk/weather/forecast/9q8yym8kr', name='bocha_web_search', tool_call_id='call_d2cd50da1a864cefbe13e3')]}
{'messages': [HumanMessage(content='Whats the weather in SF?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d2cd50da1a864cefbe13e3', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 241, 'total_tokens': 266, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-e1a02e77-8bd2-9a90-95a4-aa4acb0d0849', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--b9cddaca-3aee-4842-a07e-887e28964a8d-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 241, 'output_tokens': 25, 'total_tokens': 266, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), ToolMessage(content='1. San Francisco, California, United States current weather conditions and forecast\n47°F / 8°C Feels like 44.10°F / 7°C Wind: West at 6 mph / 9 km/h Humidity: 86% Pressure: 30 inches /\n链接: https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959\n\n2. Weather for San Francisco, California, USA\nNow 16 °C Passing clouds. Feels Like: 16 °C Forecast: 15 / 9 °C Wind: 11 km/h ↑ from Southwest Locat\n链接: https://www.timeanddate.com/weather/usa/san-francisco\n\n3. San Francisco Weather\nRadar/Satellite images courtesy of NOAA/NWS and Weather Underground . Summary / Temperature Wind Rai\n链接: http://zwilnik.net/wx/wxindex.php\n\n4. San Francisco (United States of America) weather - Met Office\nRELEASE CANDIDATE This is a test website - some features and links may not work, and data may be inc\n链接: https://wwwpre.metoffice.gov.uk/weather/forecast/9q8yym8kr', name='bocha_web_search', tool_call_id='call_d2cd50da1a864cefbe13e3'), AIMessage(content='当前旧金山的天气情况如下:\n\n1. **天气来源 1**:\n - 温度: 47°F / 8°C\n - 体感温度: 44.10°F / 7°C\n - 风速: 西风 6 mph / 9 km/h\n - 湿度: 86%\n - 气压: 30 英寸\n - 链接: [Weather in San Francisco](https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959)\n\n2. **天气来源 2**:\n - 温度: 现在 16°C\n - 天气状况: 多云\n - 体感温度: 16°C\n - 风速: 11 km/h,西南方向\n - 链接: [Weather for San Francisco](https://www.timeanddate.com/weather/usa/san-francisco)\n\n您可以参考上述链接获取更多详细信息。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 235, 'prompt_tokens': 543, 'total_tokens': 778, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-9f1521be-c651-9d84-a969-fa116c914230', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--1da80204-375b-4621-912c-6e5d9515230c-0', usage_metadata={'input_tokens': 543, 'output_tokens': 235, 'total_tokens': 778, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
{'messages': [AIMessage(content='当前旧金山的天气情况如下:\n\n1. **天气来源 1**:\n - 温度: 47°F / 8°C\n - 体感温度: 44.10°F / 7°C\n - 风速: 西风 6 mph / 9 km/h\n - 湿度: 86%\n - 气压: 30 英寸\n - 链接: [Weather in San Francisco](https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959)\n\n2. **天气来源 2**:\n - 温度: 现在 16°C\n - 天气状况: 多云\n - 体感温度: 16°C\n - 风速: 11 km/h,西南方向\n - 链接: [Weather for San Francisco](https://www.timeanddate.com/weather/usa/san-francisco)\n\n您可以参考上述链接获取更多详细信息 。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 235, 'prompt_tokens': 543, 'total_tokens': 778, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-9f1521be-c651-9d84-a969-fa116c914230', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--1da80204-375b-4621-912c-6e5d9515230c-0', usage_metadata={'input_tokens': 543, 'output_tokens': 235, 'total_tokens': 778, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
我们可以再次打印看看此时该thread_id内存放了哪些的聊天记录,并且也可以用.next命令看看下一步是要做什么:
messages = [HumanMessage(content="Whats the weather in SF?")]
thread = {"configurable": {"thread_id": "11"}}
# for event in abot.graph.stream({"messages": messages}, thread):
# for v in event.values():
# print(v)
# print(abot.graph.get_state(thread))
# print(abot.graph.get_state(thread).next)
# for event in abot.graph.stream(None, thread):
# for v in event.values():
# print(v)
print(abot.graph.get_state(thread))
print(abot.graph.get_state(thread).next)
这个时候我们就可以看到之前所有的聊天过程记录都保存在了StateSnapshot当中,并且.next指令的回复也是空的括号,这也意味着后续没有进一步的指令需要执行,我们可以传入新的问题和语句了。
StateSnapshot(values={'messages': [HumanMessage(content='Whats the weather in SF?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_d2cd50da1a864cefbe13e3', 'function': {'arguments': '{"query": "current weather in San Francisco"}', 'name': 'bocha_web_search'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 241, 'total_tokens': 266, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-e1a02e77-8bd2-9a90-95a4-aa4acb0d0849', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--b9cddaca-3aee-4842-a07e-887e28964a8d-0', tool_calls=[{'name': 'bocha_web_search', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_d2cd50da1a864cefbe13e3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 241, 'output_tokens': 25, 'total_tokens': 266, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), ToolMessage(content='1. San Francisco, California, United States current weather conditions and forecast\n47°F / 8°C Feels like 44.10°F / 7°C Wind: West at 6 mph / 9 km/h Humidity: 86% Pressure: 30 inches /\n链接: https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959\n\n2. Weather for San Francisco, California, USA\nNow 16 °C Passing clouds. Feels Like: 16 °C Forecast: 15 / 9 °C Wind: 11 km/h ↑ from Southwest Locat\n链接: https://www.timeanddate.com/weather/usa/san-francisco\n\n3. San Francisco Weather\nRadar/Satellite images courtesy of NOAA/NWS and Weather Underground . Summary / Temperature Wind Rai\n链接: http://zwilnik.net/wx/wxindex.php\n\n4. San Francisco (United States of America) weather - Met Office\nRELEASE CANDIDATE This is a test website - some features and links may not work, and data may be inc\n链接: https://wwwpre.metoffice.gov.uk/weather/forecast/9q8yym8kr', name='bocha_web_search', tool_call_id='call_d2cd50da1a864cefbe13e3'), AIMessage(content='当前旧金山的天气情况如下:\n\n1. **天气来源 1**:\n - 温度: 47°F / 8°C\n - 体感温度: 44.10°F / 7°C\n - 风速: 西风 6 mph / 9 km/h\n - 湿 度: 86%\n - 气压: 30 英寸\n - 链接: [Weather in San Francisco](https://www.worldtimeserver.com/weather_in_US-CA.aspx?forecastid=gn5391959)\n\n2. **天气来源 2**:\n - 温度: 现在 16°C\n - 天气状况: 多云\n - 体感温度: 16°C\n - 风速: 11 km/h,西南方向\n - 链接: [Weather for San Francisco](https://www.timeanddate.com/weather/usa/san-francisco)\n\n您可以参考上述链接获 取更多详细信息。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 235, 'prompt_tokens': 543, 'total_tokens': 778, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-9f1521be-c651-9d84-a969-fa116c914230', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--1da80204-375b-4621-912c-6e5d9515230c-0', usage_metadata={'input_tokens': 543, 'output_tokens': 235, 'total_tokens': 778, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}, next=(), config={'configurable': {'thread_id': '11', 'checkpoint_ns': '', 'checkpoint_id': '1f06c4e7-7598-6f05-8003-bdf7a5155395'}}, metadata={'source': 'loop', 'step': 3, 'parents': {}}, created_at='2025-07-29T07:34:31.409229+00:00', parent_config={'configurable': {'thread_id': '11', 'checkpoint_ns': '', 'checkpoint_id': '1f06c4e7-355f-62cc-8002-efbbdaa8ad30'}}, tasks=(), interrupts=())
()
这样我们就实现了一个简单的人工介入的操作。那假如我们不希望这么不智能,还要手动的进行调整,而是像真正的Agent产品一样在终端输入y或者n来决定是否进行下一步的话,我们可以使用以下代码来实现:
messages = [HumanMessage("Whats the weather in LA?")]
thread = {"configurable": {"thread_id": "2"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
while abot.graph.get_state(thread).next:
print("\n", abot.graph.get_state(thread),"\n")
_input = input("proceed?")
if _input != "y":
print("aborting")
break
for event in abot.graph.stream(None, thread):
for v in event.values():
print(v)
其实前五行的代码都是一样的,只不过是在后面加了一个while循环来判定是否要继续执行。首先在判定前会通过.get_state()的方法获取当前的聊天记录,然后通过input()来让我们在终端输入判定信息,假如我们输入的不是y的话就直接跳出循环结束程序,假如输入的是y的话就按照我们之前的方式输入None来继续任务,这样我们就能基本实现人工参与的任务执行了!
我们运行了一下就返回了以下内容:
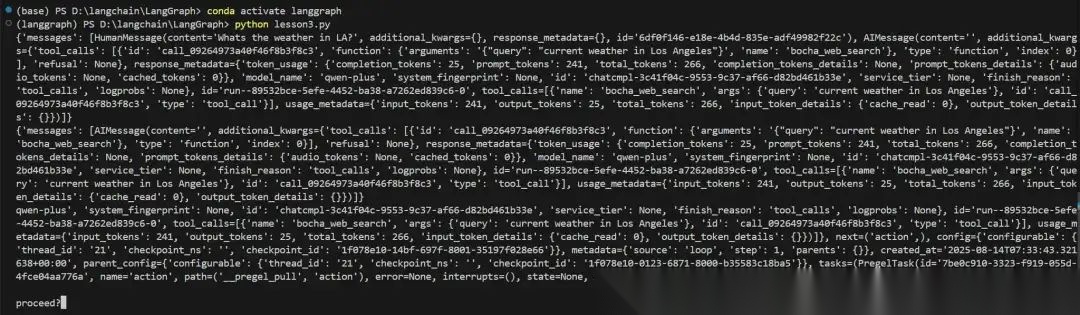
输入y以后就执行action任务,这样我们就简单的实现了人工的参与:
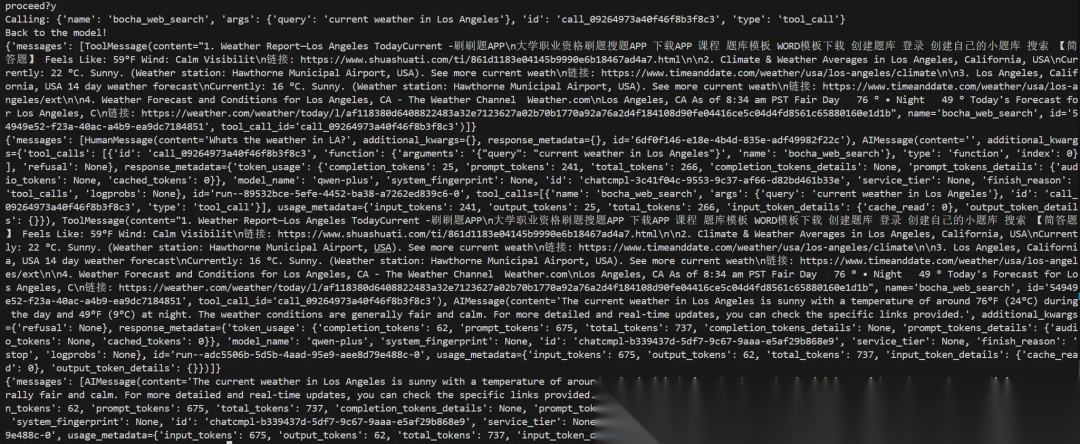
通过这些基本的状态操作步骤,我们可以更好地掌控 Agent 的任务执行流程。不过,我认为还有一种更优雅的方式:不必每次都由我们主动介入,而是由大模型根据实际需要主动请求人工参与。
具体来说,我们可以将“人工参与”设计为一个工具(Tool)的形式。当大模型在执行任务过程中遇到自身难以处理的情况时,它便调用该工具向人类发出请求,获取补充信息后再继续任务。这种方式能够让模型在必要时引入人类反馈,从而生成更完善、更加贴合实际的回复。
当然,大模型是否具备这种“请求人类协助”的能力,本质上取决于模型本身的理解与决策水平。这也是为什么过去一年里,各大公司纷纷投入资源打造自己的 SOTA 级基座模型——因为只有更强大的基础模型,才能实现更加智能、灵活的 Agent 协同机制。
总结
通过本节课的学习,我们完成了两项智能体能力的核心升级:
- 持久化记忆(Checkpointing):借助
SqliteSaver将智能体的对话与任务执行状态保存到 SQLite 数据库,结合thread_id管理不同会话的上下文,实现了“随时暂停、随时恢复”的能力。 - 状态可视化与人工介入(Streaming + HITL):使用
graph.stream()实时查看每个节点的执行过程,并能在关键节点前中断,人工判断是否继续执行,进一步增强了智能体的可控性与安全性。
这两个功能结合后,你的 LangGraph 智能体不仅能 记住过去,还能 实时受控,从而更好地应对复杂的多轮任务和长周期运行场景。下一步,你可以尝试将人工介入设计成独立的工具,让模型在需要时主动请求人类参与,实现更加自然的协作流程。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)