
微调 Qwen3-0.6B 代码实操 + 截图
大家好,我是此林。这几年大模型发展特别快,不光会写文章、聊天,还能看图、懂视频,应用到学习、科研、医疗各方面,就像给各行各业加上了智能“外挂”。现在动不动就有上百亿、上千亿参数的大模型,很厉害。但小模型(比如只有 0.6B (6亿) 参数的)其实也很有价值。为什么呢?:大模型跑起来要很强的显卡和服务器,小模型却能在笔记本、手机甚至小设备上运行,用起来更便宜。:小模型反应更灵敏,特别适合语音助手、实
大家好,我是此林。
这几年大模型发展特别快,不光会写文章、聊天,还能看图、懂视频,应用到学习、科研、医疗各方面,就像给各行各业加上了智能“外挂”。
现在动不动就有上百亿、上千亿参数的大模型,很厉害。
但小模型(比如只有 0.6B (6亿) 参数的)其实也很有价值。为什么呢?主要有几个原因:
-
省资源:大模型跑起来要很强的显卡和服务器,小模型却能在笔记本、手机甚至小设备上运行,用起来更便宜。
-
速度快:小模型反应更灵敏,特别适合语音助手、实时问答这种要“秒回”的场景。
-
更安全:小模型能在本地跑,不用把数据传到云上,用户隐私更有保障。
-
训练灵活:给小模型做针对某个行业的小训练(微调)成本低,企业能更快打造自己的“专属智囊”。
-
研发试验:研究人员常用小模型来快速试算法、试架构,再决定要不要搬到大模型上。
因此,大模型与小参数量模型并非替代关系,而是互补生态:前者代表极限能力,后者强调实用落地。
那么今天,我们来看微调 Qwen3-0.6B 的实操案例。
1. 模型下载、环境配置
1.1. 模型下载
话不多说,相信大家对于 Qwen3 系列已经耳熟能详,我们要下载的是 Qwen3 0.6B,在 ModelScope 和 HuggingFace 上都可以下载。
安装 ModelScope
pip install modelscope下载模型到本地指定目录
modelscope download --model Qwen/Qwen3-0.6B --local_dir /data/wangyi/qwen0.6B/Qwen3-0.6B下载模型过程。ModelScope 下载速度还是挺快的,两分钟大概就下载完了。
下载后模型目录截图
1.2. GPU 环境
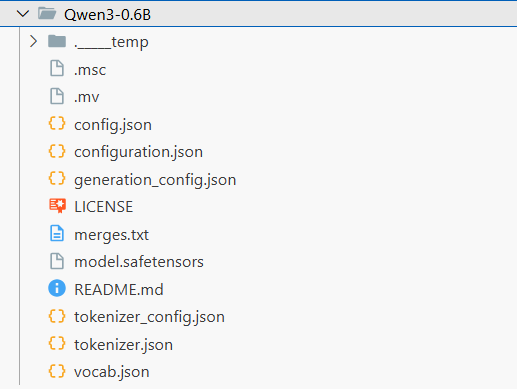
笔者用的 GPU 4090 单卡,显存 24 G,cuda 版本 12.7。
通过命令 nvidia-smi 查看。
1.3. Python 依赖安装
# 换清华镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装所需依赖
pip install modelscope transformers accelerate datasets peft swanlab pandas
# 强制重装 GPU 版本的 torch、torchvision
pip install --force-reinstall torch torchvision -i https://download.pytorch.org/whl/cu126
建议大家创建个虚拟环境,用 venv、conda 或者 uv 都行。
2. 数据集
数据集来自 DataWhale 的 huanhuan.json,主要为 甄嬛 对话。所以我们的任务是微调 Qwen3 0.6B,让角色扮演 甄嬛 ,模仿人物风格说话。

图中可以看到有 instruction(指令)、input(输入)。
output 为我们期望的模型输出。
这个 instruction 和 input 其实没有什么太大的区别,都是用户输入,我们后续微调的时候会拼接这两个字段为用户输入。
3. 微调代码
3.1. 数据集处理
导入所有需要的依赖
from datasets import Dataset
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
加载数据集
# 加载 datasets
ds_path = '/data/wangyi/qwen0.6B/huanhuan.json'
df = pd.read_json(ds_path)
# 将JSON文件转换为CSV文件
ds = Dataset.from_pandas(df)加载模型
mode_path = '/data/wangyi/qwen0.6B/Qwen3-0.6B'
tokenizer = AutoTokenizer.from_pretrained(mode_path)
model = AutoModelForCausalLM.from_pretrained(
mode_path,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法1. 我们先加载分词器(Tokenizer),用于把文本转为模型能理解的 token ID
2. CausalLM 的意思是因果语言模型,主流的模型基本为因果LLM。
3. device_map="auto" 表示自动分配模型到可用设备(如 GPU / CPU / 多卡)
torch_dtype=torch.bfloat16 指定模型权重的数据类型(bfloat16)
trust_remote_code=True 允许加载模型目录下自定义的代码4. model.enable_input_require_grads() 启用输入需要梯度(input_require_grads),这样在进行梯度检查点(gradient checkpointing)时,输入张量的梯度会被正确计算,避免训练报错。
数据处理函数
接下来我们要定义数据处理函数,用于把每条训练样本转换成模型能理解的输入格式。
# 定义数据处理函数,用于把每条训练样本转换成模型能理解的输入格式
def process_func(example):
MAX_LENGTH = 1024 # 设置最大序列长度为 1024 个 token,超过会被截断
input_ids, attention_mask, labels = [], [], [] # 初始化返回的三类张量
# 适配 Chat 模板,将 instruction 和 input 拼接成完整 prompt
full_prompt = tokenizer(
f"<s><|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n" # 系统角色提示
f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n" # 用户输入
f"<|im_start|>assistant\n<think>\n\n</think>\n\n", # 模型角色开始,预留思考标记
add_special_tokens=False # 不自动添加额外的 special tokens,因为模板里已有
)
# 对模型的输出文本进行 tokenization
response = tokenizer(f"{example['output']}", add_special_tokens=False)
# 拼接输入的 token_ids:instruction部分 + 模型输出部分 + 末尾 pad_token_id
input_ids = full_prompt["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
# 拼接注意力掩码(attention_mask):1 表示需要关注的 token
attention_mask = full_prompt["attention_mask"] + response["attention_mask"] + [1]
# 构造 labels:
# instruction 部分用 -100 表示不计算 loss(模型无需预测)
# response 部分正常预测
labels = [-100] * len(full_prompt["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
# 如果长度超过 MAX_LENGTH,进行截断,保证不超显存
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
# 返回字典,符合 transformers Dataset 的格式
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# 对数据集 ds 进行 map 操作,把每条样本都通过 process_func 转换
# remove_columns=ds.column_names 表示去掉原始列,只保留处理后的 input_ids/attention_mask/labels
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)
这里的代码可能有点长,我这里解释下。
1. 设置最大序列长度为 1024 个 token,超过会被截断。初始化返回的三类张量。
MAX_LENGTH = 1024
input_ids, attention_mask, labels = [], [], []2. 适配 Chat 模板。
full_prompt = tokenizer(
f"<s><|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n"
f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n"
f"<|im_start|>assistant\n<think>\n\n</think>\n\n",
add_special_tokens=False
)这个其实是什么呢?我们再实际输入给模型的时候,一般都会这样输入:

是不是有role和content,所以你对照代码来看,其实就是个 conversation 对话列表。
第一行 就是系统提示词:现在你要扮演皇帝身边的女人--甄嬛
第二行 就是用户输入。
第三行 的话我们提前加了 <think></think> 标签,阻止 Qwen3 输出冗长思考过程。因为 Qwen3 系列具备自动 think,我们此次微调任务是模仿任务说话风格,不需要它思考,何况我们数据集里也没有思考内容,因此模型只需要输出最终答案文本即可。
第四行 不自动添加额外的 special tokens,因为模板里已有,比如<|im_start|>、<|im_end|>。
3. 对数据集期望模型输出文本进行 tokenization + 拼接输入的 token_ids
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = full_prompt["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]4. 拼接注意力掩码(attention_mask):1 表示需要模型需要关注的 token
attention_mask = full_prompt["attention_mask"] + response["attention_mask"] + [1]5. 构造 labels:用户输入部分用 -100 表示不计算 loss(模型无需预测),response 部分正常预测
labels = [-100] * len(full_prompt["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]6. 如果 input_ids 长度超过 MAX_LENGTH,进行截断,保证不超显存。
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]7. 返回字典,符合 transformers Dataset 的格式
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}8. 对数据集 ds 进行 map 操作,把每条样本都通过 process_func 转换。
remove_columns=ds.column_names 表示去掉原始列,只保留处理后的input_ids/attention_mask/labels。
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)3.2. LoRA 微调的配置
从 PEFT 库导入 LoRA 配置类、任务类型枚举和获取 LoRA 模型函数
from peft import LoraConfig, TaskType, get_peft_model# 定义 LoRA 微调的配置
config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型:因果语言模型(Causal LM),适合生成任务
target_modules=[ # 需要应用 LoRA 的模型模块列表
"q_proj", "k_proj", "v_proj", "o_proj", # 注意力层的 q/k/v/o 投影
"gate_proj", "up_proj", "down_proj" # MLP 层中的投影层
],
inference_mode=False, # False 表示训练模式(需要更新 LoRA 参数),True 表示推理模式
r=8, # LoRA 秩(rank),控制低秩矩阵的维度,越大拟合能力越强
lora_alpha=32, # LoRA 的缩放系数 alpha,影响低秩矩阵的初始化和梯度更新
lora_dropout=0.1 # LoRA 层的 Dropout 比例,防止过拟合
)
# 将原始模型包装成 LoRA 模型
# 只会训练 LoRA 注入的参数,其余权重保持冻结
model = get_peft_model(model, config)
LoRA 微调本质上是低秩分解,在训练微调的时候,冻结模型原有参数(防止新的训练对模型原有能力造成破坏),引入一个低秩矩阵A/B,训练的时候只更新低秩矩阵,最后推理的时候再进行模型合并。
| 参数名 | 类型 | 默认值/示例 | 说明 |
|---|---|---|---|
task_type |
枚举 | TaskType.CAUSAL_LM |
任务类型,决定 LoRA 微调目标;因果语言模型适合文本生成任务 |
target_modules |
List[str] | ["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj"] |
指定要注入 LoRA 的模块,一般是注意力层和 MLP 层的线性层 |
inference_mode |
bool | False |
是否为推理模式;False 表示训练阶段,True 表示只用于推理,不更新权重 |
r |
int | 8 |
LoRA 的秩(rank),控制低秩矩阵的维度,越大模型拟合能力越强,但占用更多显存 |
lora_alpha |
int | 32 |
缩放系数 α,用于调整低秩矩阵的输出大小,影响梯度更新 |
lora_dropout |
float | 0.1 |
Dropout 比例,用于防止 LoRA 层过拟合 |
fan_in_fan_out |
bool | False(默认) |
是否对权重矩阵进行转置,通常保持默认即可 |
bias |
str | 'none' |
是否对 LoRA 增加偏置项,可选 'none' / 'all' / 'lora_only' |
3.3. 训练参数配置
args = TrainingArguments(
output_dir="/data/wangyi/qwen0.6B/Qwen3_0.6B_lora",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=3,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="none",
)各个训练参数的解释:
| 参数 | 说明 |
|---|---|
output_dir |
模型输出路径,训练后的权重和 checkpoint 会保存在这里 |
per_device_train_batch_size |
每个设备(GPU)上的训练批次大小 |
gradient_accumulation_steps |
梯度累积步数,相当于将 batch_size 放大;例如 batch_size=4,累积4步,等效 batch_size=16 |
logging_steps |
每训练多少步打印一次日志 |
num_train_epochs |
训练轮数(epoch) |
save_steps |
每训练多少步保存一次 checkpoint |
learning_rate |
学习率 |
save_on_each_node |
如果多节点训练,每个节点都保存模型副本 |
gradient_checkpointing |
开启梯度检查点,节省显存,但前向计算稍慢 |
report_to |
日志报告平台,"none" 表示不上传日志到 WandB/TensorBoard 等 |
这里我们不上传日志到 WandB/TensorBoard,我们使用 swanlab 框架,这个自己去官网注册下账号就好了。
import swanlab
from swanlab.integration.transformers import SwanLabCallback
# 实例化SwanLabCallback,训练日志可视化
swanlab_callback = SwanLabCallback(
project="Qwen3-Lora",
experiment_name="Qwen3-0.6B-LoRA-experiment"
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback]
)
trainer.train()4. 训练结果可视化 SwanLab
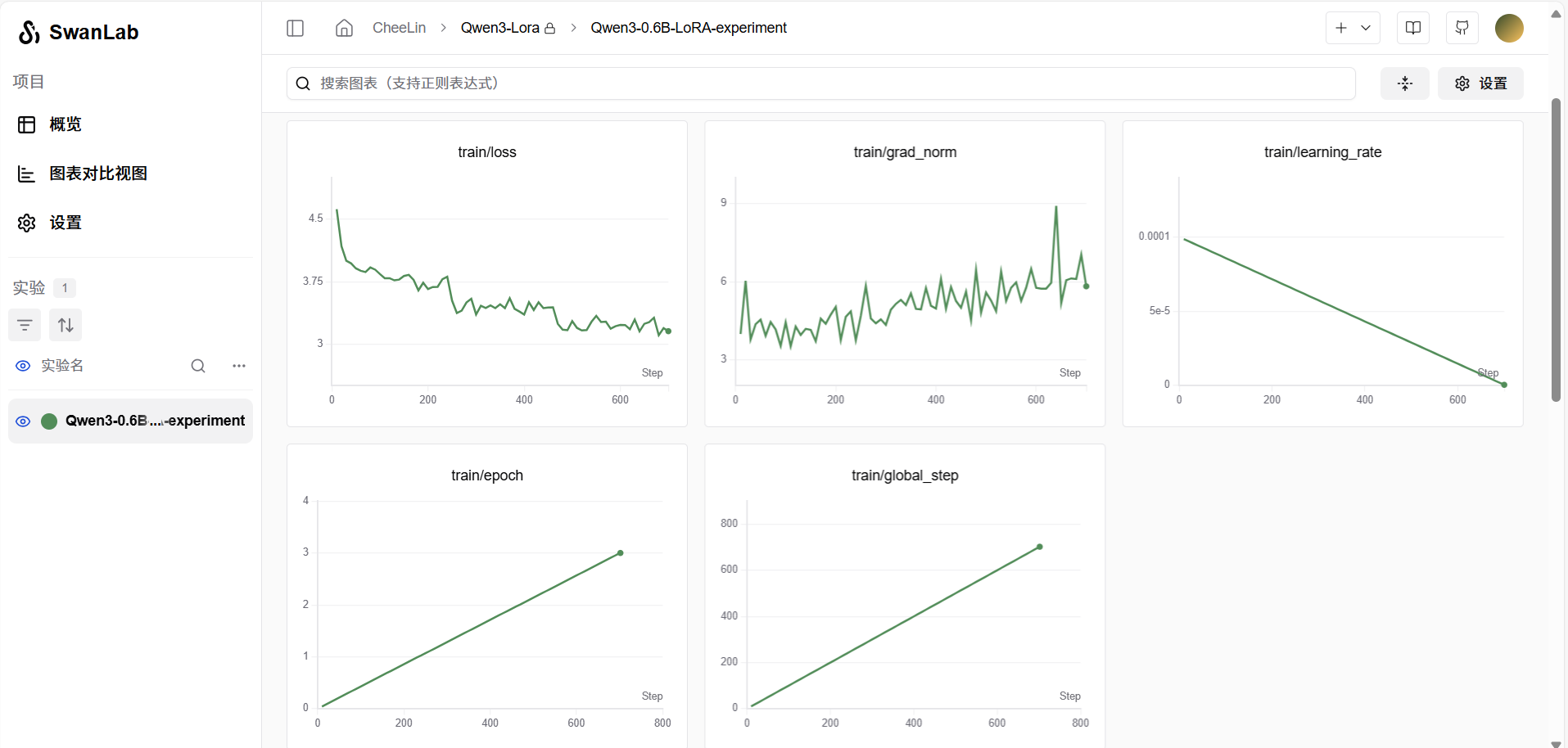
笔者在训练的时候,发现显存实际占用大约为 8 G 左右,和估算的差不多。
训练好后的 lora 权重保存在该目录下。
5. 对比测试微调前后模型
原模型:test.py
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
mode_path = '/data/wangyi/qwen0.6B/Qwen3-0.6B'
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载Qwen3 base model
model = AutoModelForCausalLM.from_pretrained(
mode_path,
device_map="auto", # 自动放到GPU
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
messages = [
{"role": "system", "content": "假设你是皇帝身边的女人--甄嬛。"},
{"role": "user", "content": "你是谁"}
]
inputs = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
enable_thinking=False
)
# 把 inputs 移动到模型所在的设备
device = model.device
inputs = {k: v.to(device) for k, v in inputs.items()}
# 采样参数设置
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
加入 lora 后的模型:test_lora.py,其实代码差不多,只不过合并了下原模型和LoRA参数。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
mode_path = '/data/wangyi/qwen0.6B/Qwen3-0.6B'
lora_path = '/data/wangyi/qwen0.6B/Qwen3_0.6B_lora/checkpoint-702'
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载Qwen3 base model
model = AutoModelForCausalLM.from_pretrained(
mode_path,
device_map="auto", # 自动放到GPU
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)
messages = [
{"role": "system", "content": "假设你是皇帝身边的女人--甄嬛。"},
{"role": "user", "content": "你是谁"}
]
inputs = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
enable_thinking=False
)
# 把 inputs 移动到模型所在的设备
device = model.device
inputs = {k: v.to(device) for k, v in inputs.items()}
# 采样参数设置
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
对比结果
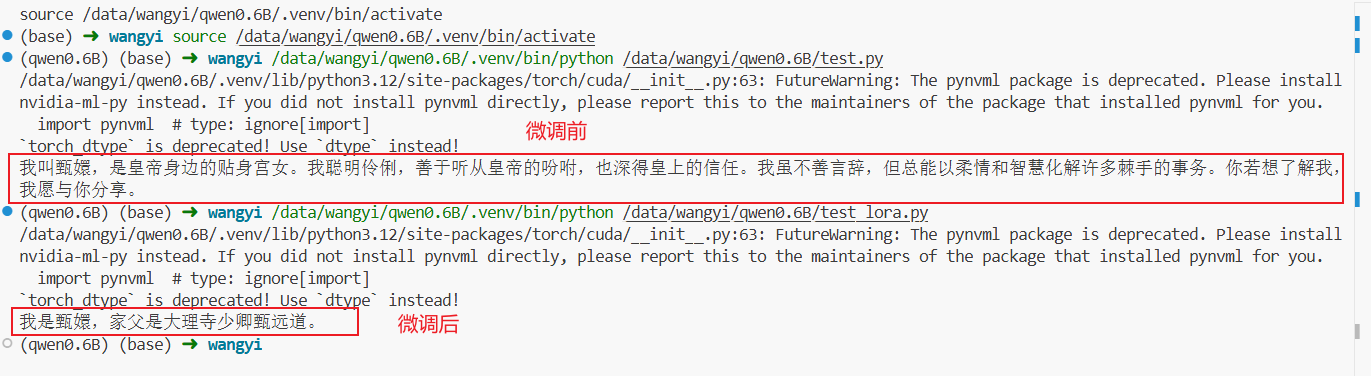
最后关于采样参数的补充:
1. max_new_tokens 是限制 LLM 最终输出的 token 数,max_length 是用户输入 + 模型输出的总 token 数。
2. do_example 表示是否要开启采样。如果为 False 表示不开启采样,直接贪心搜索(每次都选择概率最高的 token,对于相同的输入大模型都是确定输出),那么后面再设置的 temperature、top_p、top_k 就失效了。
3. do_example 为 True,那么就会结合
temperature/top_k/top_p产生随机性。temperature 控制概率分布的“平滑度”,top_p 在采样时,只保留累计概率 ≤p的最小 token 集合,例:top_p=0.9→ 保留概率加起来达到 90% 的候选,其余都丢掉。4. repetition_penalty 用于减少模型“复读”的现象。大于 1 会降低已经出现过的 token 的概率,使模型更倾向生成新词。
5.
top_kvstop_p:
top_k:保留概率最高的前 K 个 token(基于数量),top_k = 1 相当于退化为贪心搜索
top_p:保留累计概率 ≤ p 的最小 token 集(基于概率质量)。
今天的分享就到这里了。
我是此林,关注我吧!
带你看不一样的世界!
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)