
最新AI大模型数据集解决方案:分享两种AI高质量代码数据集生产方案
最新AI大模型数据集解决方案:分享两种AI高质量代码数据集生产方案,你知道哪些?随着AI大模型技术的快速发展,自动化的数据抓取工具逐渐成为了主流,尤其是在需要快速、高效、可定制化的数据抓取时,Web Scraper API工具成为了许多开发者和数据科学家的首选工具。与第一种方式不同,Web Scraper API工具提供了图形化界面以及灵活的配置选项,能够帮助用户更快、更高效地抓取数据。Web S
最新AI大模型数据集解决方案:分享两种AI高质量代码数据集生产方案
在人工智能的世界里,数据是驱动创新和提升模型性能的核心动力。尤其对于大型预训练模型和微调模型,数据的质量直接决定了模型的能力。特别是在处理AI代码相关任务时,高质量的数据集更是不可或缺的基础。然而,构建这样一个高质量且符合需求的AI数据集,往往需要克服许多挑战——从获取到清洗,再到格式化,环环相扣,精细的操作和策略至关重要。
针对这一问题,本文将分享两种实用的解决方案:一种是基于动态住宅代理 + 手动处理的传统方式,另一种则是通过Web Scraper API工具实现的自动化数据抓取。无论你是偏好手动定制化的数据采集方式,还是希望借助自动化工具高效生成数据集,这两种方法都能帮助你快速高效地构建出高质量的AI代码数据集。

文章目录
第一种方式:传统方式 - 动态住宅代理 + 手动处理
在许多情况下,尽管新的自动化工具层出不穷,传统的手动数据采集方法依然在一些特定场景中发挥着重要作用,尤其是当目标数据源的结构复杂,或者需要进行深度定制化处理时。这里,我们以GitHub仓库的issues数据采集为例,详细讲解如何通过动态住宅代理和手动处理方式获取高质量数据集。
1. 使用动态住宅代理实现高效抓取
动态住宅代理是一种利用住宅IP地址池进行数据抓取的方法。通过不断切换IP地址,模拟真实用户的行为,可以有效避免在抓取大量数据时遭遇封禁或速率限制的情况。住宅代理提供了一个真实的IP地址来源,能够在数据抓取过程中实现更高的隐蔽性和稳定性。
操作步骤:
- 选择一个动态住宅代理提供商,并创建账户。
- 配置代理池,设置IP通道规则。
- 使用代理池获取不同的IP地址,避免单一IP过于频繁的请求被封禁。
操作步骤演示:
-
步骤1:打开代理服务商的官网,创建账户。
-
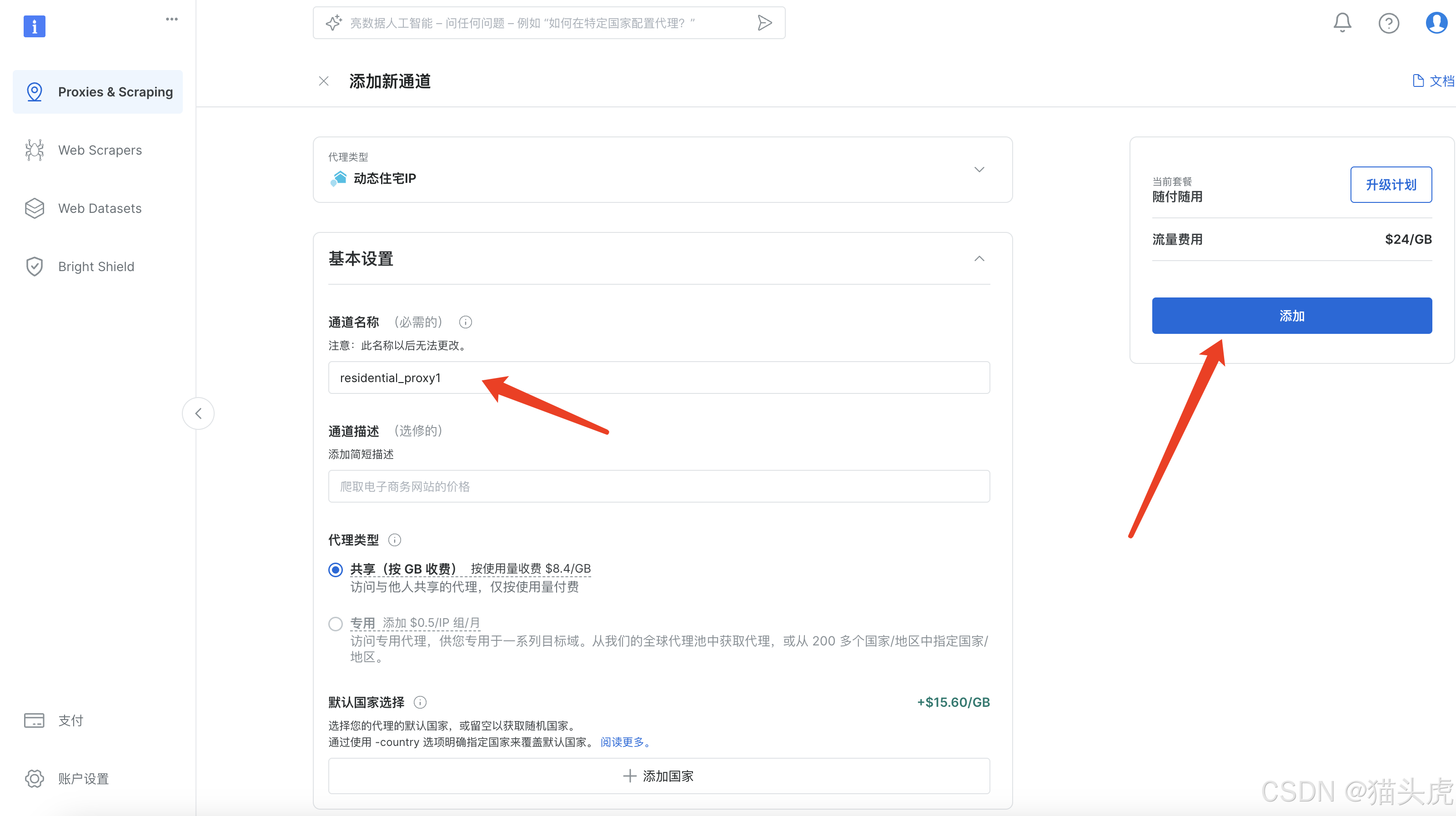
步骤2:配置代理池。
点击左侧第一个菜单-> proxies&Scraping->点击 开始使用创建一个通道 即可

- 步骤3:进行基本信息配置,创建通道名称。
2. 分页读取数据并规避API限制
以GitHub仓库为例,GitHub的API在请求频率上有一定限制。为避免超出API的请求频率限制,可以采用分页读取数据的方式,逐步获取所有的issues数据。
操作步骤:
- 使用GitHub API,进行分页数据请求。
- 通过API文档查阅分页参数,如
page和per_page,设置适当的参数进行分页抓取。
详细步骤演示:
-
步骤1:查看IP连接的URL。
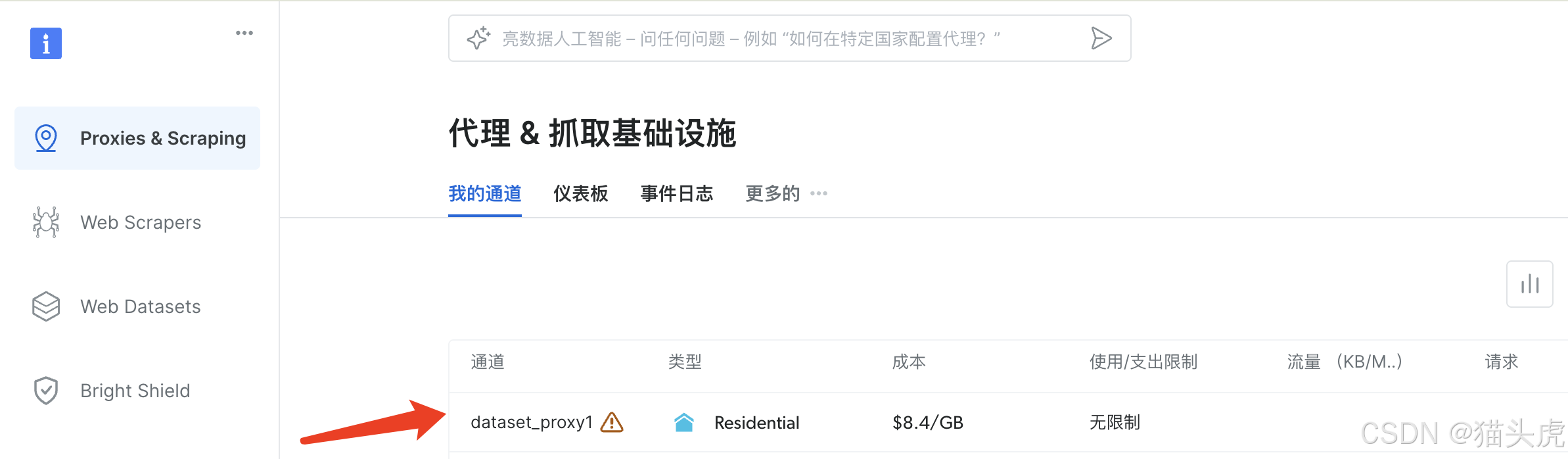
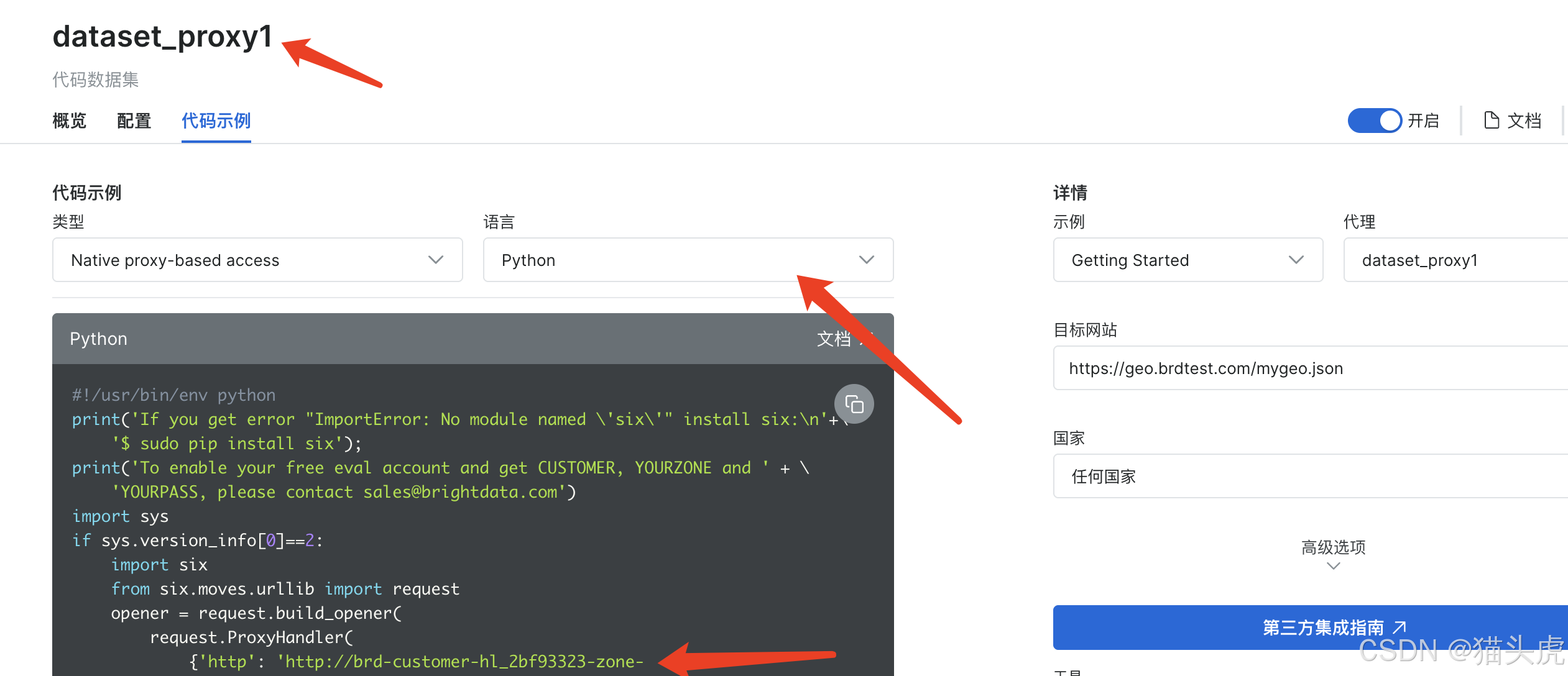
-
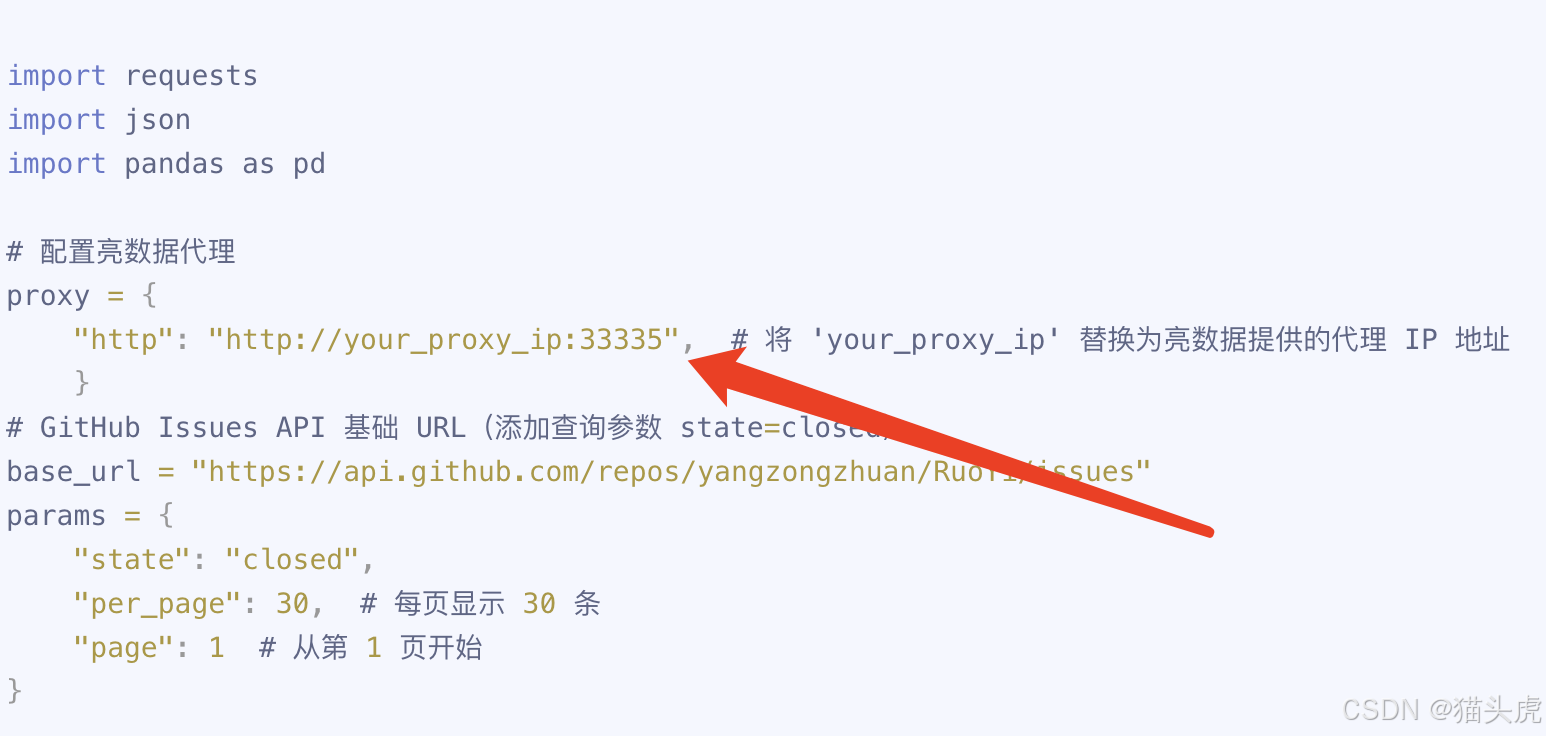
步骤2:替换下方代码案例里面的URL
3. 数据清洗与格式转换
抓取到的数据通常是杂乱无章的JSON或者HTML格式,这些数据往往需要经过清洗和转换,才能成为训练AI模型所需的结构化数据。
操作步骤:
- 清洗数据,去除不必要的字段。
- 将数据转化为JSONL格式。
详细步骤:
- 步骤1:使用Python脚本进行数据清洗。
# 处理获取的数据
for issue in issues_data:
issue_info = {
"issue_id": issue['id'],
"title": issue['title'],
"url": issue['html_url'],
"state": issue['state'],
"created_at": issue['created_at'],
"updated_at": issue['updated_at'],
"closed_at": issue['closed_at'], # 已关闭时间
"user": issue['user']['login'],
"comments": issue['comments'],
"labels": [label['name'] for label in issue['labels']] # 提取标签
}
all_issues.append(issue_info)
- 步骤2:将清洗后的数据转换为JSONL格式。
# 保存为 CSV 文件
df = pd.DataFrame(all_issues)
df.to_csv('github_closed_issues_data.csv', index=False, encoding='utf-8')
# 保存为 JSONL 格式
with open('github_closed_issues_data.jsonl', 'w', encoding='utf-8') as jsonl_file:
for issue in all_issues:
# 将每个 issue 以 JSON 格式写入每一行
jsonl_file.write(json.dumps(issue, ensure_ascii=False) + '\n')
完整代码案例:
import requests
import json
import pandas as pd
# 配置亮数据代理
proxy = {
"http": "http://your_proxy_ip:33335", # 将 'your_proxy_ip' 替换为亮数据提供的代理 IP 地址
}
# GitHub Issues API 基础 URL(添加查询参数 state=closed)
base_url = "https://api.github.com/repos/yangzongzhuan/RuoYi/issues"
params = {
"state": "closed",
"per_page": 30, # 每页显示 30 条
"page": 1 # 从第 1 页开始
}
# 请求头(可选)
headers = {
"Accept": "application/vnd.github.v3+json"
}
# 初始化数据列表
all_issues = []
# 循环翻页,直到没有更多数据
while True:
# 发起请求获取已关闭的 issues 数据
response = requests.get(base_url, proxies=proxy, headers=headers, params=params)
# 检查请求是否成功
if response.status_code == 200:
issues_data = response.json()
# 如果没有更多数据,则跳出循环
if not issues_data:
break
# 处理获取的数据
for issue in issues_data:
issue_info = {
"issue_id": issue['id'],
"title": issue['title'],
"url": issue['html_url'],
"state": issue['state'],
"created_at": issue['created_at'],
"updated_at": issue['updated_at'],
"closed_at": issue['closed_at'], # 已关闭时间
"user": issue['user']['login'],
"comments": issue['comments'],
"labels": [label['name'] for label in issue['labels']] # 提取标签
}
all_issues.append(issue_info)
# 增加页面参数以获取下一页数据
params["page"] += 1
else:
print(f"请求失败,错误码: {response.status_code}")
break
# 保存为 CSV 文件
df = pd.DataFrame(all_issues)
df.to_csv('github_closed_issues_data.csv', index=False, encoding='utf-8')
# 保存为 JSONL 格式
with open('github_closed_issues_data.jsonl', 'w', encoding='utf-8') as jsonl_file:
for issue in all_issues:
# 将每个 issue 以 JSON 格式写入每一行
jsonl_file.write(json.dumps(issue, ensure_ascii=False) + '\n')
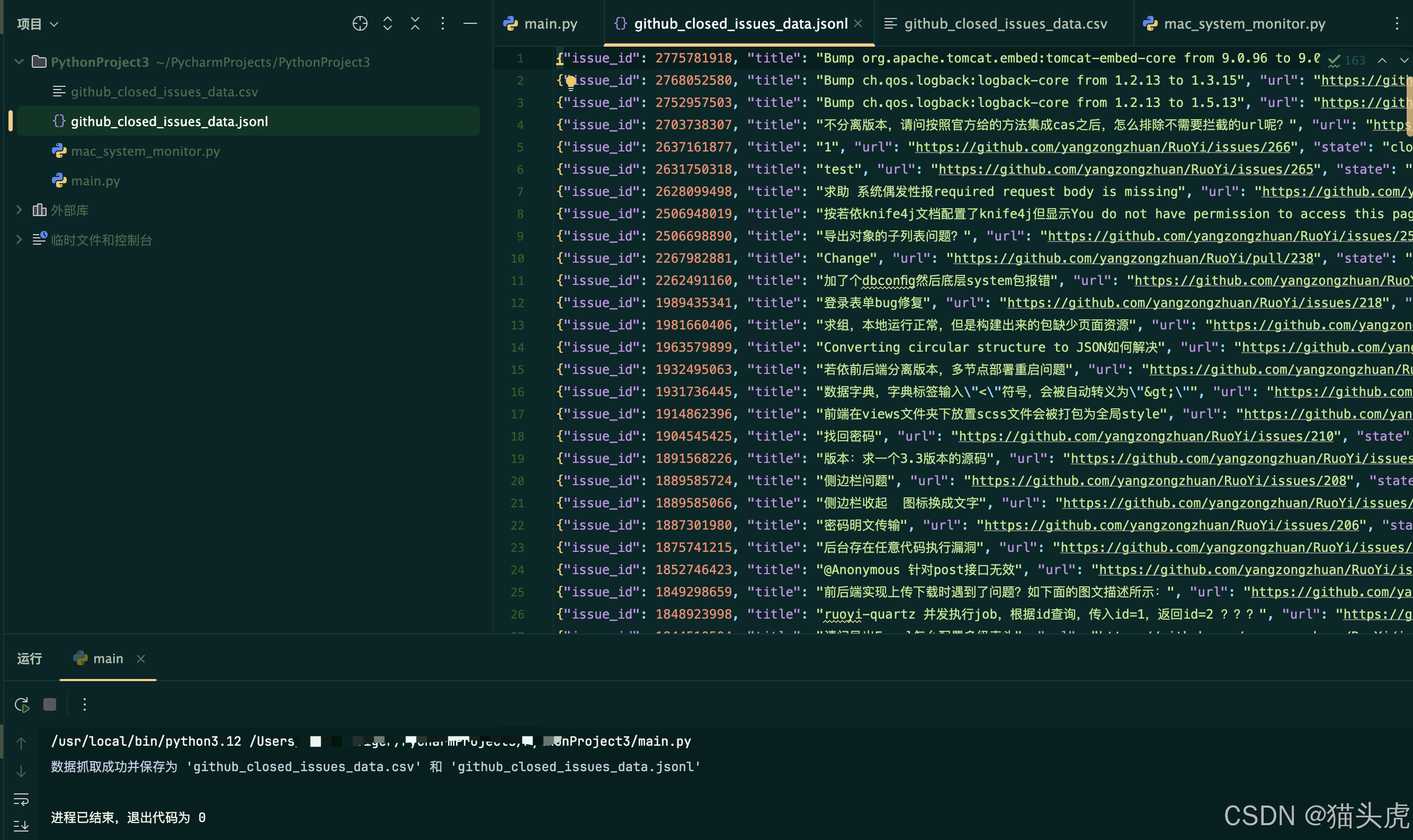
print("数据抓取成功并保存为 'github_closed_issues_data.csv' 和 'github_closed_issues_data.jsonl'")
运行结果:
传统方式虽然效果显著,但通常需要较强的编程能力和一定的业务基础。为了降低门槛并提高效率,我将介绍一款支持可视化操作的数据集处理工具。通过简单的配置,你就可以轻松完成大批量数据的处理,并直接将其输出为所需的数据集格式。
第二种方式:Web Scraper API工具 - 自定义配置数据源
随着AI大模型技术的快速发展,自动化的数据抓取工具逐渐成为了主流,尤其是在需要快速、高效、可定制化的数据抓取时,Web Scraper API工具成为了许多开发者和数据科学家的首选工具。与第一种方式不同,Web Scraper API工具提供了图形化界面以及灵活的配置选项,能够帮助用户更快、更高效地抓取数据。
1. 自定义配置数据源
Web Scraper API工具允许用户通过简单的配置,指定抓取的目标网站及数据源。例如,用户可以通过该工具配置抓取GitHub仓库中的数据、tiktok上的评论数据,甚至是其他技术论坛、博客上的内容。
操作步骤:
- 登录Web Scraper平台,创建一个新的抓取任务。
- 配置抓取目标和数据字段。
- 下载结果。
详细步骤演示:
- 步骤1:登录Web Scraper平台->创建抓取任务
入口:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202503&promo=APIS25
选择左侧的web Scrapers->之后选择 web 爬虫库

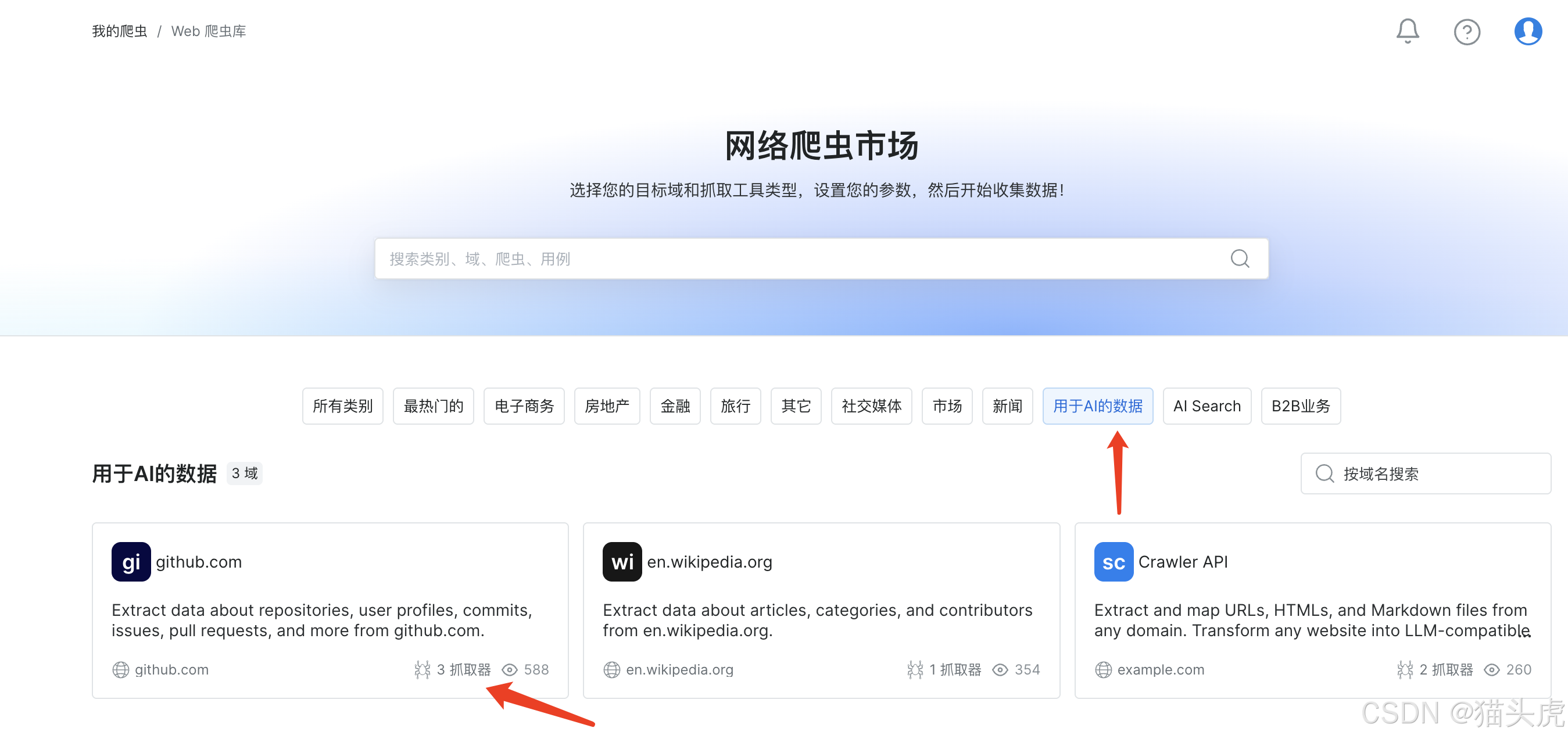
- 步骤2:选择 用于AI的数据
我这里继续选择GitHub的案例作为演示
-
步骤3: 选择 第三个,根据仓库URL

-
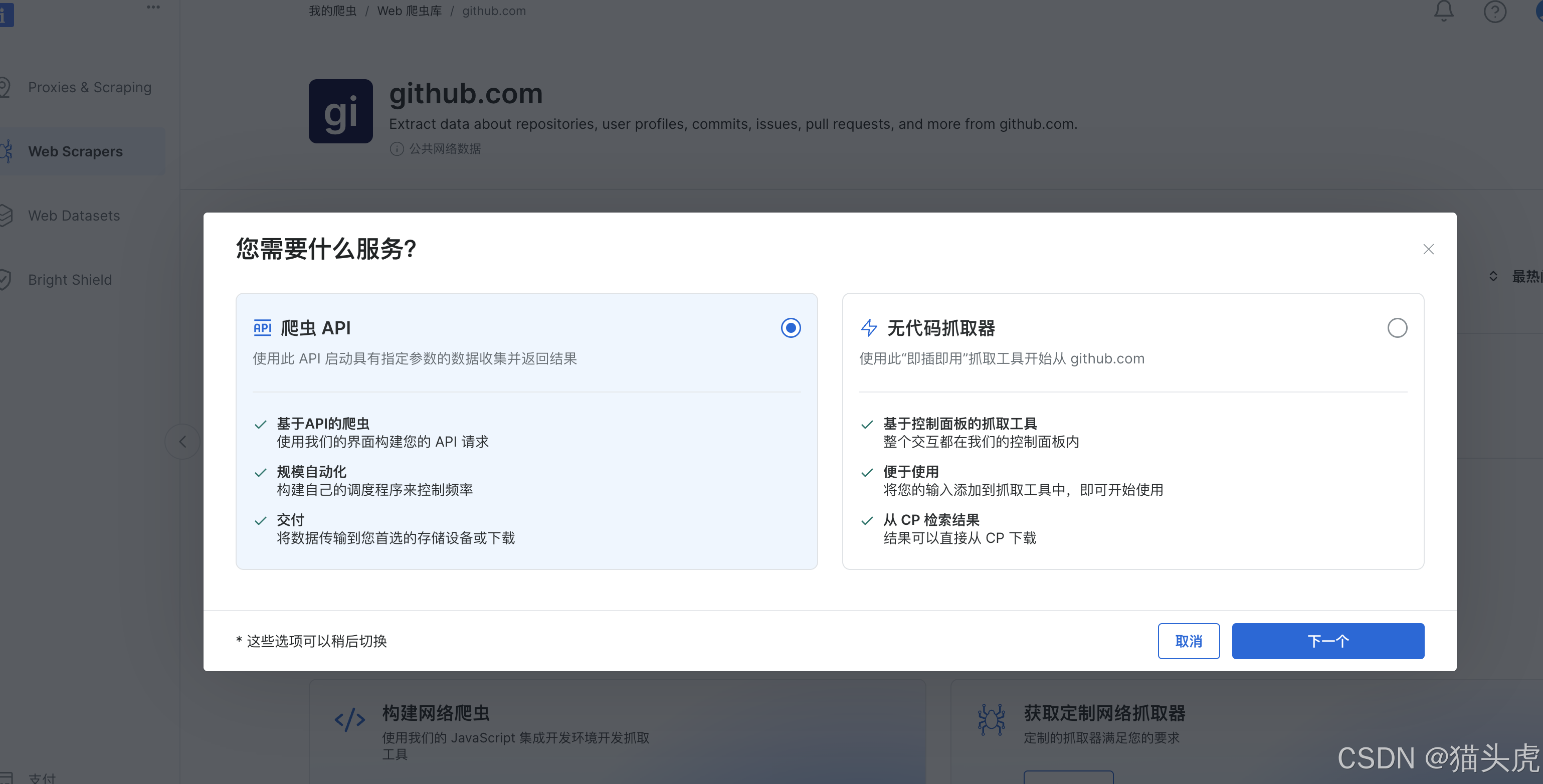
步骤4: 选择服务模式
根据实际业务情况选择即可
- 步骤5: 添加细节配置
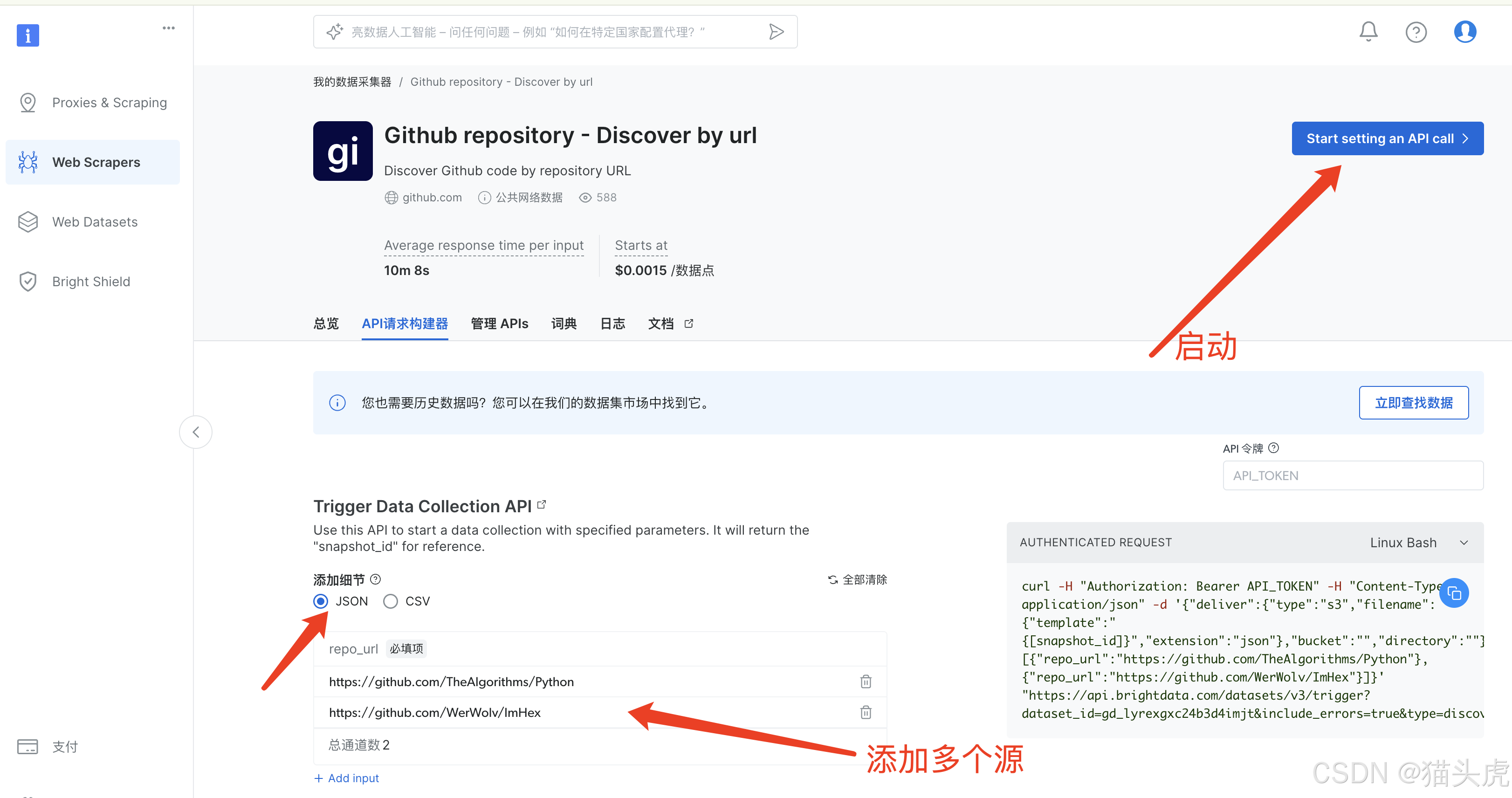
2. 可选上传到云端
对于大规模数据集的管理和存储,Web Scraper提供了云端上传功能,用户可以直接将抓取的数据上传到云存储平台。
操作步骤:
- 配置数据上传到云平台。
- 确认数据上传和存储。

3. 启动自动化生成数据集
Web Scraper API工具最大的优势之一就是能够自动化生成符合机器学习要求的数据集。通过预定义的配置,工具会自动抓取并处理数据,转化为机器学习中常用的格式。
操作步骤:
- 配置抓取的规则后,启动抓取任务。
- 系统会自动抓取数据并将其转换为JSONL、CSV等格式。
- 步骤1:启动自动抓取任务。

运行中…
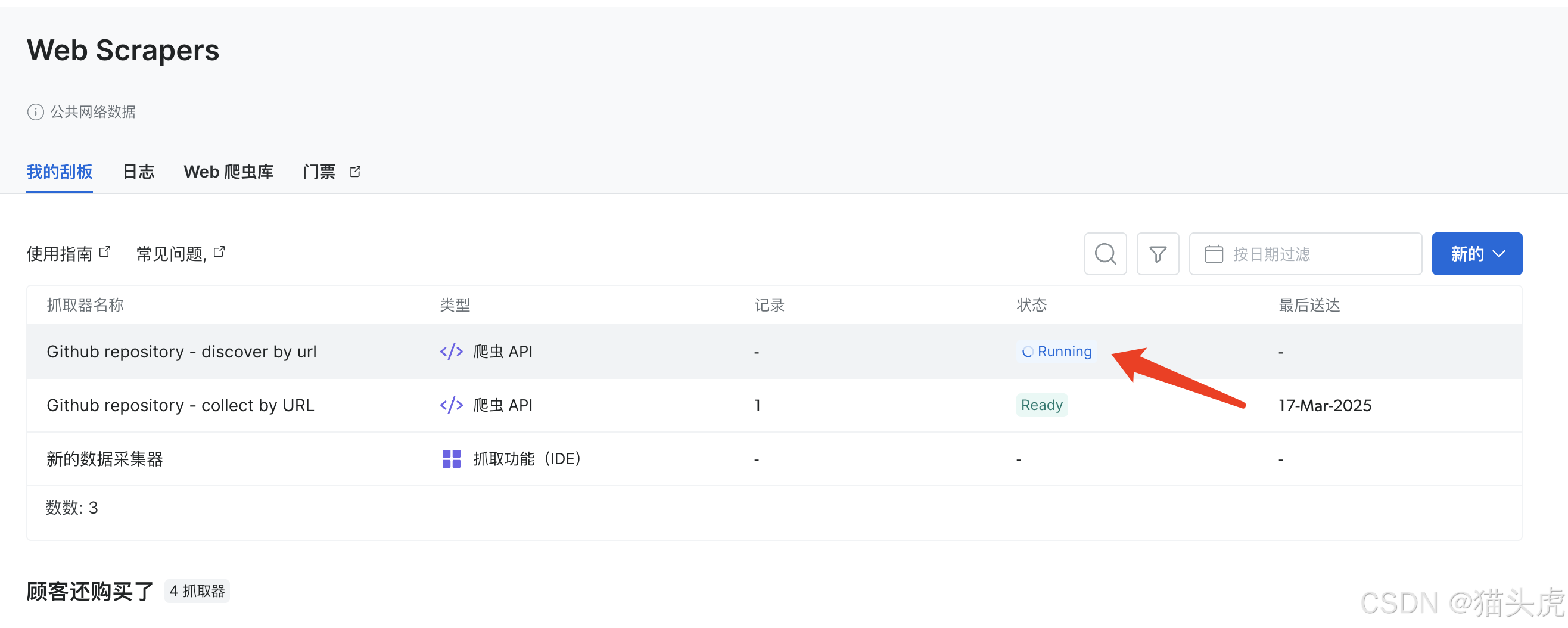
等待运行完成即可
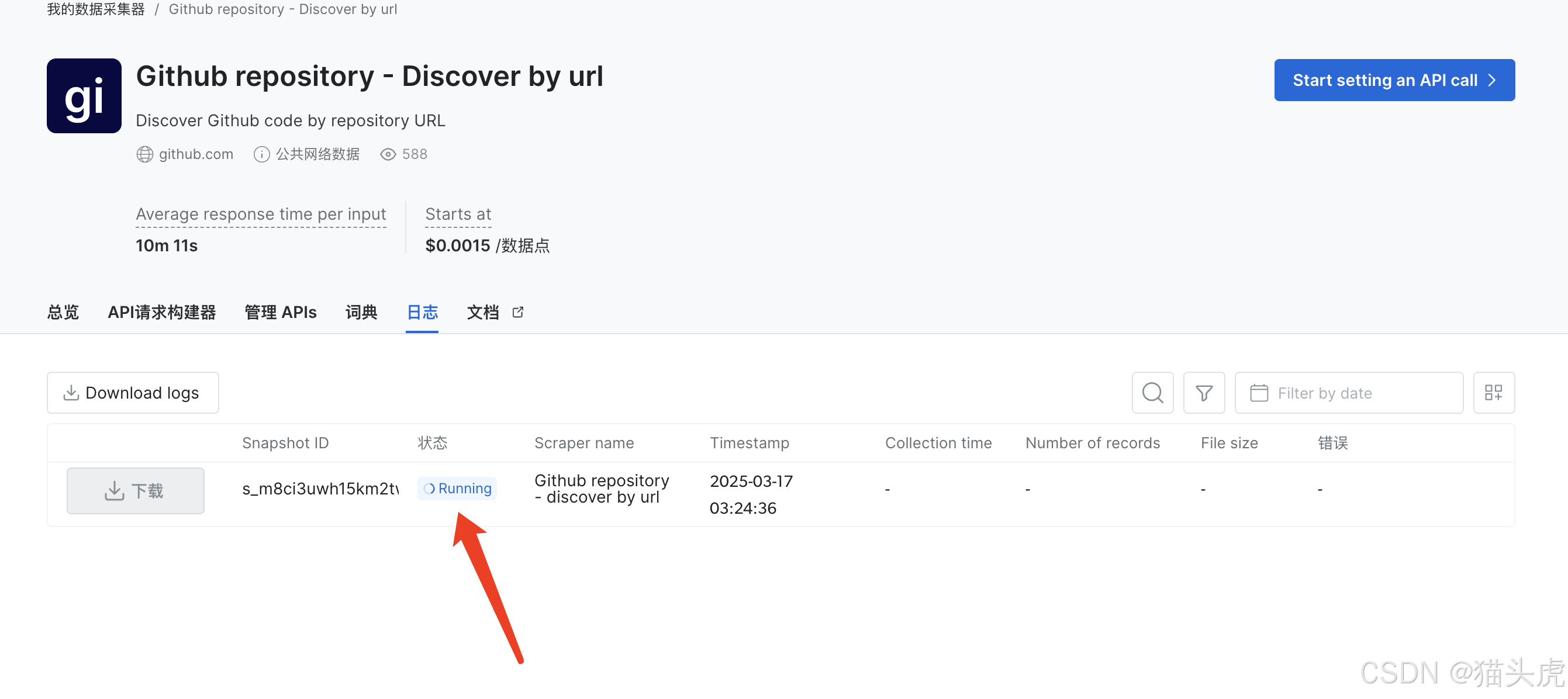
-
步骤2:查看生成的数据集并导出。

可根据实际情况选择需要 下载的数据集格式,支持 json,jsonl,csv等多种格式。
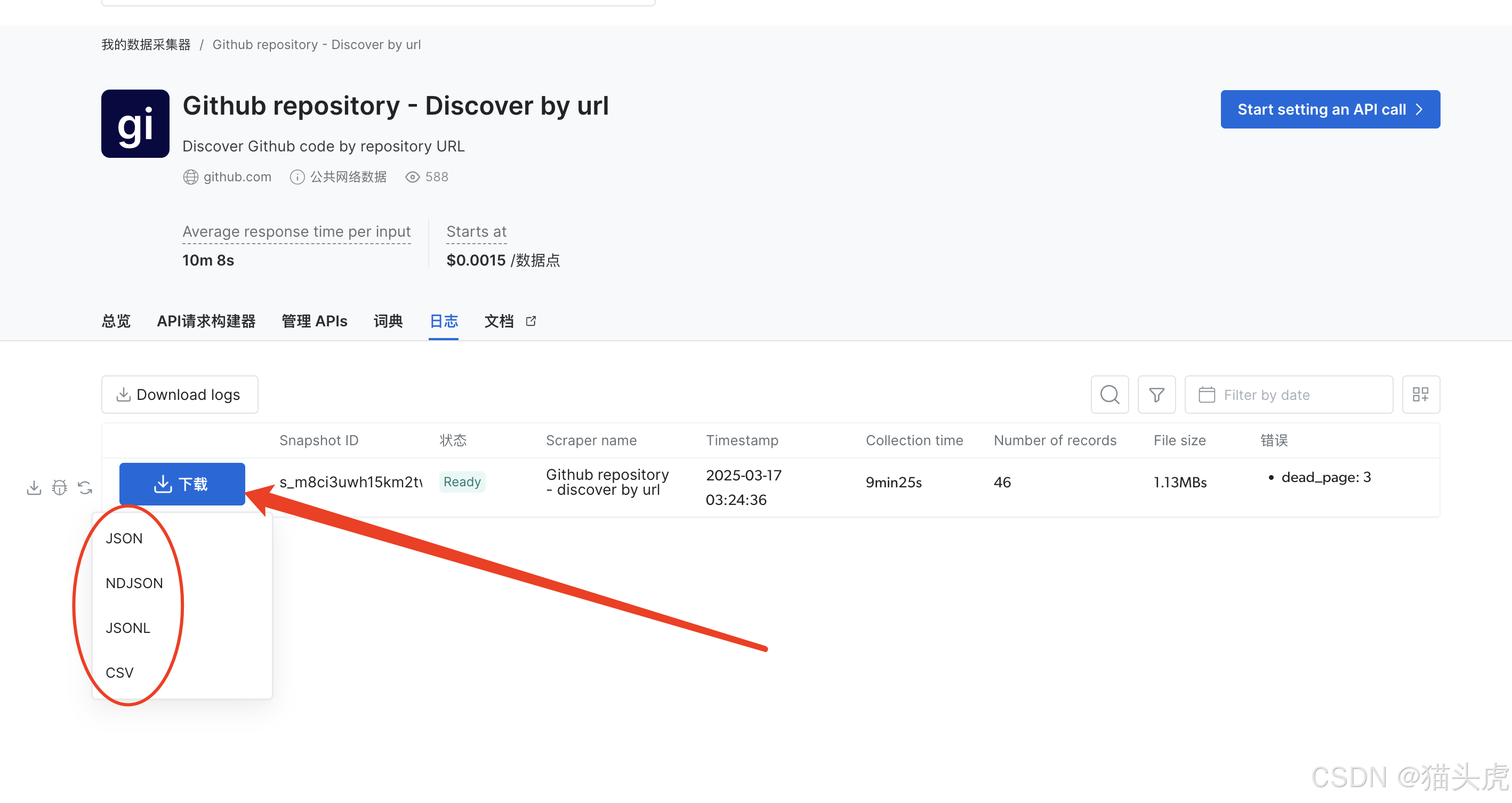
下载后的数据集格式如下:

基本操作步骤就这些,大家可以根据自己的实际业务场景调整。
总结与展望
在AI大模型的训练过程中,数据的质量和获取效率至关重要。无论是传统的动态住宅代理 + 手动处理方式,还是更为现代的Web Scraper API工具,二者都各有优势,具体使用哪一种方案取决于团队的需求、技术能力以及目标数据源的复杂性。
通过本文的操作步骤演示,大家可以更清楚地了解如何使用这两种方案高效地构建高质量的数据集。随着AI技术的不断发展,未来的数据采集和处理工具将变得越来越智能化和自动化,帮助我们更快速、更便捷地获取高质量数据,为AI模型的训练提供强有力的支持。
粉丝福利:专属优惠,提升数据采集效率
作为本文的粉丝福利,我们特别为大家准备了两项实用的优惠活动,帮助大家在进行数据采集和API调用时,降低成本,提升效率。如果你正在寻找高质量的数据采集解决方案,下面的粉丝专属链接将为你带来实实在在的省省省…。
-
动态住宅代理服务:
如果你正在考虑使用动态住宅代理来抓取数据,避免被封禁或限制,可以通过如下入口:- 点击此处:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202503&promo=RESIYERA50。
- 该优惠将帮助你以更低的价格获取稳定的代理服务,适合大规模数据抓取,特别是需要高频次访问目标网站时。
-
Web Scraper API抓取服务:
如果你更倾向于使用API工具进行自动化数据抓取,可以通过以下链接享受API服务的专属粉丝体验:- 点击此处获取API服务:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202503&promo=APIS25。
- 该工具将帮助你以更优惠的成本获取API服务,无论是自定义数据抓取,还是大规模的数据处理,都能够满足你的需求。
如何利用这些福利?
-
购买动态住宅代理服务:使用动态住宅代理进行大规模数据采集时,代理的稳定性和匿名性非常关键。通过优惠链接,你可以获得更高效、更稳定的代理服务,确保抓取任务不受限制。
-
使用API工具进行数据采集:如果你更倾向于自动化处理数据并省时省力,API抓取服务无疑是一个非常适合的选择。通过专属优惠,你将能够以更低的价格使用这些强大的API工具,提升数据抓取的效率。
希望这些福利能够帮助大家节省成本,提升数据采集的效率。


欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 122
122 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容













































所有评论(0)