
DeepAgents 把 Claude Code 的「Skills」抄回来了——核心实现只有一个中间件
去年 10 月,Anthropic 在 Claude Code 里推 Agent Skills 的时候,我第一反应是:这玩意儿不就是 prompt 工程的「换皮」吗?把 SOP 写进一个 Markdown 文件,命名 SKILL.md,放进一个固定目录,让 Agent 自己来读——这跟我以前在项目根目录放一个 prompts/ 文件夹有什么区别?
直到我前几天在跟 DeepAgents Day 12 收尾,准备给自己的 Agent 加点「业务套路」,开 IDE 翻 create_deep_agent 的签名,看到一个我之前一直略过的参数:
skills: list[str] | None = None
跟一行注释:
List of skill source paths (e.g.,
["/skills/user/", "/skills/project/"]).
我当时就停下来了。这个参数我前 12 天笔记里只在 Day 1 提过一句,在 Day 4 默认中间件清单里又一笔带过,真到要用的时候发现完全不知道它能不能解决我手上的问题:我有几套已经在 Claude Code 里跑得很顺的 SKILL.md,能不能直接挪到 LangGraph 跑的 Agent 上?跨平台复用这件事到底是不是真的?
于是我把 deepagents/middleware/skills.py 整个文件(约 1000 行 Python,其中过半是 docstring 和注释)通读了一遍,又对照着 agentskills.io 规范和 Claude Code 的实际目录布局比了一下。这是 Day 13 的笔记,把里面看到的写下来。
阅读提示
- DeepAgents 的 Skills 系统不是新概念——它是 Anthropic Agent Skills 规范的一个第三方实现,本质上一个中间件 + 一个 system prompt 模板
- Progressive Disclosure 的三段式加载,到底什么时候花什么 token
- Tool / Skill / Sub-agent 三者的边界——这套配齐了 DeepAgents「能力扩展」的全部抽象
- 一段把
~/.claude/skills/直接挂到 DeepAgents 上的最小可运行代码 全文约 14 分钟。
一、先把上下文交代清楚:Skills 是 Anthropic 推出的、Open 的标准
很多人——包括之前的我——以为 Skills 是 Claude Code 自家的特性。其实不是。
事实层面(来自 agentskills.io):
agentskills.io是一份公开的规范,定义 SKILL.md 的格式、字段约束、目录结构- 规范的核心是「Progressive Disclosure」:Agent 启动时只装载 skill 的 name + description(约 100 token / skill),决定要用了再读全文(建议 ≤ 5000 token)
- Claude Code 是该规范的第一个实现,但任何 Agent 框架都可以实现这个规范
DeepAgents 干的事情,是把这个规范在 Python 端复现了一遍,让任何用 create_deep_agent 起来的 Agent 都能消费同一套 SKILL.md。
它甚至直说自己抄了 Claude Code,README 最底下那句不显眼的话:
Inspired by Claude Code: an attempt to identify what makes it general-purpose, and push that further.
这意味着:
- 你之前在
~/.claude/skills/攒了一堆 skill?可以直接挂过来,不需要任何格式转换 - 团队内部沉淀的
.claude/skills/项目级 skill?同样可以 - 你新写的 SKILL.md,两边都能用
这是 Day 13 我决定单独写一篇的根本原因——它不是又一个框架专属配置,它是一个跨厂商生态位。
二、Day 13 在哪一层
12 天计划已经收尾。Day 13 是补漏:
- Day 5 讲了 Tool(怎么把函数注册给 Agent)
- Day 7 讲了 Workflow(怎么编排多步流程)
- Day 8 讲了 Sub-agent(怎么开子 Agent 处理子任务)
- Day 13(本篇)讲 Skill——前面三个都不太合适放的那一类东西
Skill 跟 Tool / Sub-agent 是平行抽象,不是替代关系。后面专门有一节比这件事。
三、源码层面:一个中间件 + 一个 system prompt 模板,完了
我把 middleware/skills.py 通读后,得出一个让我自己也有点意外的结论:
DeepAgents 的 Skills 系统,单文件 1068 行 Python——其中近七成是 docstring 和类型注解,去掉这些以后核心实现只剩 380 行。整个系统就两个东西:一个 AgentMiddleware 子类 + 一段 system prompt 模板。
下面把架构画出来:
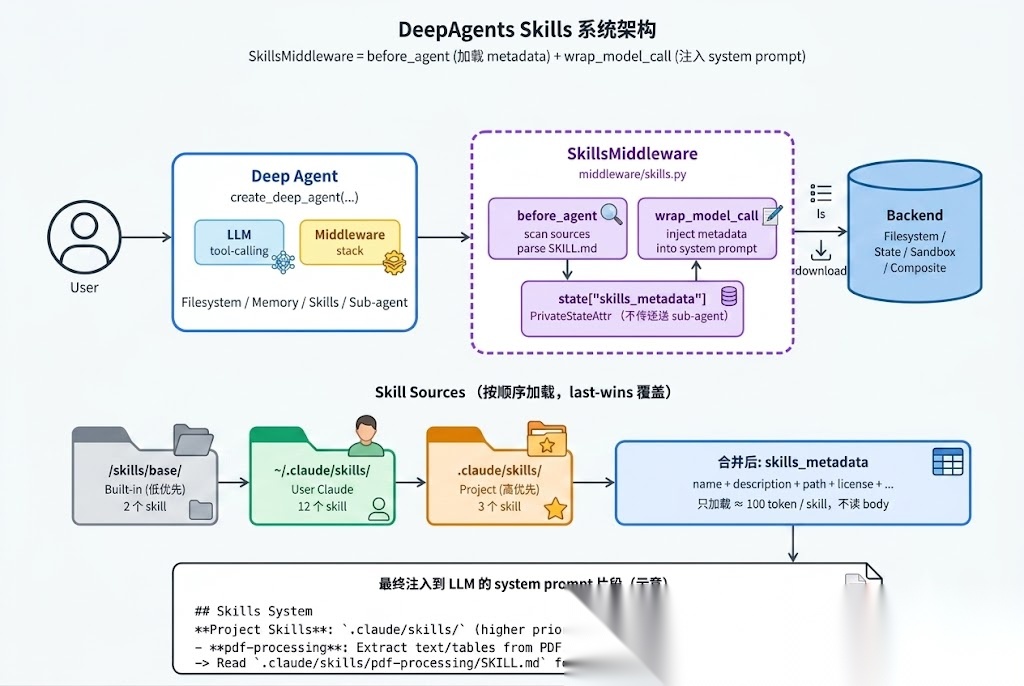
图 1:SkillsMiddleware 通过两个 hook 介入——before_agent 做加载,wrap_model_call 做注入
3.1 SkillsMiddleware 干两件事
读源码可以看到,整个 SkillsMiddleware 类就是 AgentMiddleware 的子类,重写了几个关键钩子(middleware/skills.py:748 起的 SkillsMiddleware 定义):
| 钩子 | 时机 | 干什么 |
|---|---|---|
before_agent |
Agent 启动时跑一次 | 扫描所有 source 目录,下载并解析 SKILL.md 的 YAML frontmatter,结果写进 state["skills_metadata"] |
wrap_model_call |
每轮模型调用前 | 拿 skills_metadata,按模板拼出一段 “## Skills System…”,追加到 system_message |
abefore_agent / awrap_model_call |
同上,异步版本 | 用 await backend.als() / adownload_files() |
注意一个我看源码才意识到的细节:
class SkillsState(AgentState): skills_metadata: NotRequired[Annotated[list[SkillMetadata], PrivateStateAttr]]
PrivateStateAttr 是 LangChain Middleware 的私有状态标注——它不会被传递给 sub-agent。也就是说每个 sub-agent 都得自己挂自己的 SkillsMiddleware,主 Agent 加载好的 metadata 不会污染子 Agent 的上下文。这个设计后面讲 Sub-agent 边界的时候再回来看。
3.2 一个 skill 到底是什么
按规范,一个 skill = 一个目录 + 一个 SKILL.md 文件:
my-skill/├── SKILL.md # 必须:YAML frontmatter + Markdown 正文├── scripts/ # 可选:可执行代码├── references/ # 可选:参考文档└── assets/ # 可选:静态资源
SKILL.md 的 frontmatter(DeepAgents 的解析逻辑在 _parse_skill_metadata 函数里,middleware/skills.py:366 起):
---name: pdf-processing # 必填,1-64 字符,小写字母数字加单连字符description: Extract PDF... # 必填,1-1024 字符license: Apache-2.0 # 可选compatibility: Python 3.10+ # 可选,1-500 字符metadata: # 可选,任意 key-value author: exampleallowed-tools: Bash Read # 可选(实验性),空格分隔---# 正文随你写
源码里有几个我觉得有意思的硬约束:
name必须等于父目录名(_validate_skill_name里这一行:if name != directory_name: return False)——这强制规范化,防止两个目录用同名 skill 互相覆盖- 单文件最大 10 MB(
MAX_SKILL_FILE_SIZE)——防御性的 DoS 防护,因为加载逻辑会把整个文件读进内存解析 description超过 1024 字符会自动截断,不会报错——这点要注意,过长 description 会被默默砍掉
3.3 多 Source 叠加的 “last-wins” 是怎么实现的
这是 Skills 系统最被低估的设计点。你可以同时挂多个 source,按顺序加载,后挂的覆盖先挂的:
sources=[ "/skills/base/", # 框架自带,最低优先级 "~/.claude/skills/", # 个人 skill ".claude/skills/", # 项目 skill,最高优先级]
源码实现极其朴素(before_agent,middleware/skills.py:941 起):
all_skills: dict[str, SkillMetadata] = {}for source_path in self.sources: source_skills, source_error = _list_skills_with_errors(backend, source_path) for skill in source_skills: all_skills[skill["name"]] = skill # 同名直接赋值,后挂的赢
就一个 dict。但这就是「base → user → project」三层 skill 叠加的全部秘密。它对应的实际意义:
- base 层:放公司/团队的基础 skill,强制全员继承
- user 层:放个人偏好,比如「我喜欢用中文写注释」
- project 层:放当前项目的硬规则,比如「这个 repo 用 pytest 不用 unittest」
跟 Python 的 ChainMap、Git 的 config 优先级、CSS 的级联,是完全一样的设计哲学。
四、Progressive Disclosure:到底省了多少 token
这是 Skills 系统真正的卖点。我把启动到激活的完整时序画出来:
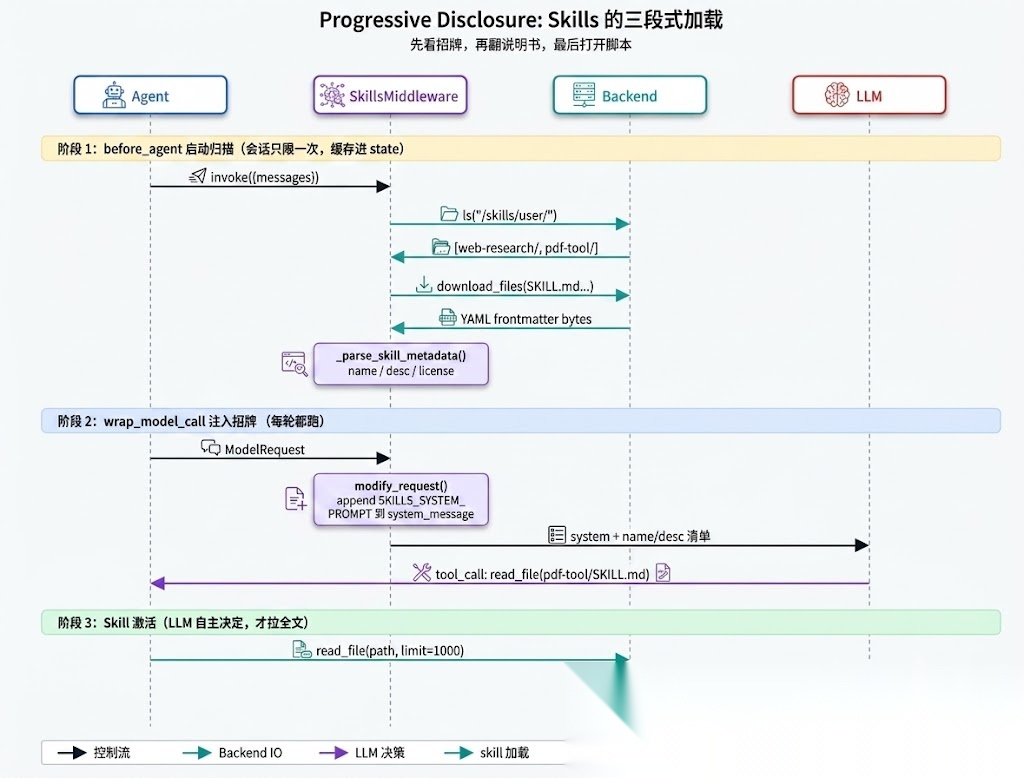
图 2:三个阶段——启动扫描、每轮注入、按需激活,每个阶段花的 token 量级不同
来做个粗略的 token 对比。这里用规范建议的上限做估算:单个 SKILL.md 建议正文 ≤ 5000 token(agentskills.io 推荐),metadata 部分约 100-200 token(name 最多 64 字符 + description 最多 1024 字符)。假设你有 20 个 skill:
做法 A:全塞 system prompt(很多人最初的做法)
启动注入:20 × 5000 = 100,000 token(上限)每轮 prompt 都带:~100,000 tokenLLM 决策:在十万 token 里挑要用哪个
模型 context 直接被 system 占满,每次 input 都贵,模型注意力还会被冗余信息淹没。
做法 B:Progressive Disclosure(DeepAgents 默认)
启动注入:仅 metadata,20 × ~150 = ~3,000 token每轮 prompt 都带:~3,000 token触发激活:LLM 决定用 pdf-processing -> 调 read_file(limit=1000)单 skill 全文:≤ 5,000 token,只在用到的那一轮带
最不利情况下,做法 B 也比做法 A 少了一个数量级的常驻 token;这个差距随 skill 数量线性放大。这个估算用的是规范建议的上限,实际 SKILL.md 大多比 5000 token 短,差距会更大。
source 里把这个意图写得很直白(SKILLS_SYSTEM_PROMPT,middleware/skills.py:705):
Skills follow a **progressive disclosure** pattern - you see their name and description above, but only read full instructions when needed:1. Recognize when a skill applies2. Read the skill's full instructions: Use read_file ... Pass limit=1000 since the default of 100 lines is too small for most skill files.
注意第 2 步那个 limit=1000——这是给 LLM 的明确指令。默认的 read_file 只读 100 行,对大多数 skill 不够,所以模板里把这个值固定写死提示给模型。一个小细节,但能看出工程上踩过的坑。
Progressive Disclosure 的代价
这套设计有一个不太被提及的成本:它把「要不要激活 skill」的决策权交给了 LLM。
- 如果 description 写得不好,LLM 不会激活——skill 等于白挂
- 如果 description 写得太宽泛,LLM 在不该激活的时候也激活——浪费 read_file 一轮
- 多个 skill 描述重叠,LLM 可能挑错的那个
所以 SKILL.md 的 description 字段是整个体系最值钱的字段。规范甚至写明要求:
Should describe both what the skill does and when to use it. Should include specific keywords that help agents identify relevant tasks.
「用途 + 触发条件 + 关键词」三件套缺一不可。我自己写 SKILL.md 都会先把这一行打磨 5 分钟。
五、跟 Tool / Sub-agent 摆在一起看
到这里我突然意识到一件事:DeepAgents 提供了三种「让 Agent 多会一点东西」的机制,三者完全不能互相替代。
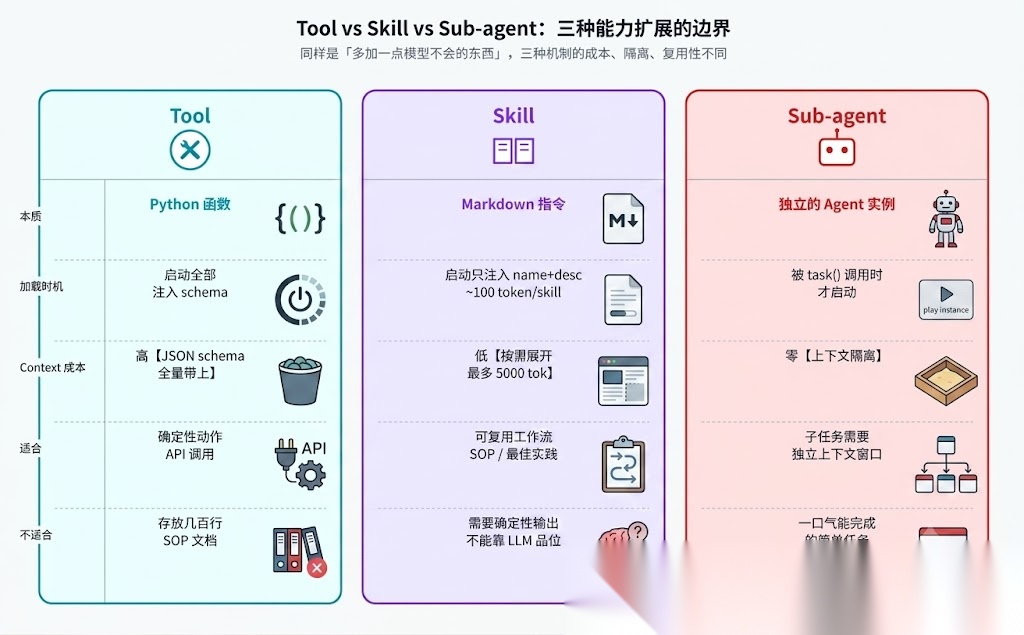
图 3:三种能力扩展的本质、加载时机、context 成本、适合与不适合的场景
我把决策树写出来——你下次想给 Agent 加点东西时,对照这个决定该选哪种:
你要加的是「一个确定性动作」?→ 用 Tool
- 调一个 REST API、查一次数据库、跑一个计算
- 输入输出有明确 schema、结果可以复现、不需要 LLM 二次理解
- 例子:
get_weather(city)、query_user_orders(uid)
Tool 的代价是它的完整 schema 必须进 system prompt(OpenAI / Anthropic 都这样),所以加多了 context 涨得快。
你要加的是「一套做事的方法 / SOP」?→ 用 Skill
- 「怎么做技术评审」「怎么写公众号文章」「怎么从 PDF 抽表格再交叉验证」
- 内容是指令,不是函数;执行靠 LLM 理解 + 调用现有 tool 组合
- 例子:本仓库
~/.opencode/skills/creator-weixin/SKILL.md,里面写了一整套微信公众号文章的写作规范、自查清单、图表风格——LLM 读完按它去写
Skill 的优势是 progressive disclosure 控成本,加 100 个 skill 也不会爆 context;劣势是结果不确定性高——同一个 SKILL.md 不同模型读出来的产出可能不一样。
你要加的是「需要独立思考多步的子任务」?→ 用 Sub-agent
- 子任务复杂到需要自己有完整的 reasoning loop
- 主 Agent 不希望子任务的中间 tool_call 污染自己的上下文
- 例子:「研究 LangChain 最新版本变化」——主 Agent 给一句话,sub-agent 自己 plan、自己调搜索工具、自己整理,最后只把结论返回
Sub-agent 最贵——它是一个完整的 Agent 实例,自己有 LLM 调用、自己有 context 窗口。别用 sub-agent 干 tool 该干的事。
三者还能组合
最后这一点 Day 8 没讲透,Day 13 补回来:Skill 可以告诉 LLM 该调哪些 Tool,Sub-agent 可以独立挂自己的 Skill。
比如一个 code-review skill 可能写着:
1. 先用 `read_file` 读出 PR 涉及的所有文件2. 用 `grep` 找出所有可能的 SQL 注入点3. 用 `task` 调 sub-agent "security-reviewer" 做深度审查
整套 SOP 就在 skill 里固化下来,LLM 读完按部就班执行——这才是 Skill 的真正价值。它不是替代 Tool / Sub-agent,它是它们的编排说明书。
六、最小可运行 Demo:把 ~/.claude/skills 直接挂到 DeepAgents
废话讲完,看代码。下面这套代码是基于源码 API 直接读出来的最小写法,前面三节涉及的所有机制都跑通一遍。
6.1 准备一个 skill
如果你已经有 ~/.claude/skills/,可以跳过。没有的话造一个最简单的:
mkdir -p ~/.claude/skills/sql-reviewcat > ~/.claude/skills/sql-review/SKILL.md <<'EOF'---name: sql-reviewdescription: Review SQL queries for performance issues and common bugs. Use when the user asks to review, optimize, or check SQL/HiveQL/Spark SQL code.---# SQL Review SkillWhen reviewing a SQL query, walk through these checks in order:1. **Full table scan**: does any subquery miss a WHERE on the partition key?2. **Join order**: largest table on the left (broadcast hint for small dim tables)?3. **DISTINCT after GROUP BY**: redundant?4. **Window function**: PARTITION BY missing leads to scan-all-data?5. **Cartesian product**: any JOIN missing the ON clause?Output format:- One issue per line- Severity tag: [HIGH] / [MEDIUM] / [LOW]- Suggested fix in one sentenceEOF
这个 SKILL.md 同时是合法的 Claude Code skill 和合法的 DeepAgents skill——一份文件,两边都能跑。
6.2 挂载到 DeepAgents
import osfrom deepagents import create_deep_agentfrom deepagents.backends.filesystem import FilesystemBackend# 用 FilesystemBackend 直读本地文件,root_dir 设到家目录backend = FilesystemBackend(root_dir=os.path.expanduser("~"))agent = create_deep_agent( model="openai:gpt-4o-mini", backend=backend, skills=[".claude/skills/"], # 相对 root_dir 的路径 system_prompt="You are a senior data engineer.",)result = agent.invoke({ "messages": [{"role": "user", "content": """帮我 review 这段 SQL:SELECT u.user_id, COUNT(DISTINCT o.order_id)FROM user u JOIN orders o ON u.user_id = o.user_idWHERE o.dt = '2024-01-01'GROUP BY u.user_id"""}]})print(result["messages"][-1].content)
按源码逻辑,跑出来你应该能观察到三件事(开 LangSmith trace 或直接打 log 验证):
- 第一轮:Agent 收到消息,system prompt 已经被
wrap_model_call注入了 “## Skills System … sql-review: Review SQL queries…” - 第二轮:LLM 看到 description 里的「Use when the user asks to review … SQL」匹配,发出
read_file(file_path=".claude/skills/sql-review/SKILL.md", limit=1000)的 tool call - 第三轮:拿到完整 SKILL.md 后,按里面的 5 条 check 逐条输出 review 结果
如果第 2 步没发生(LLM 没激活 skill),通常是 description 写得不够具体,或者用户 prompt 的关键词跟 description 没对上——回去把 description 重写一下,加上明确的触发关键词(「SQL」「HiveQL」「review」这类)。
注意:第 2 步是 LLM 自主决定的,不是中间件强制的。如果换一个能力较弱的模型(比如本地 7B),它可能不会激活 skill——这是 Progressive Disclosure 的固有代价,前面讲过。
6.3 进阶:多源叠加
agent = create_deep_agent( model="anthropic:claude-sonnet-4-5", backend=backend, skills=[ ".claude/skills/team-base/", # 团队基础 skill(低优先级) ".claude/skills/", # 个人 skill # 用 (path, label) 元组给 source 取显示名,否则两个 skills 目录会撞名 # 注意:当前 create_deep_agent 的 skills 参数只接 list[str], # 如果要 (path, label) 元组,需要手动构造 SkillsMiddleware 传 middleware 参数 ], system_prompt="You are a senior engineer.",)
如果有同名 skill,后挂的赢。这是 source 顺序敏感的——别搞反。
6.4 在 Sub-agent 里独立挂 skill
源码 graph.py:629 有这段:
subagent_skills = spec.get("skills")if subagent_skills: subagent_middleware.append(SkillsMiddleware(backend=backend, sources=subagent_skills))
所以每个 sub-agent 可以有自己的 skill 集——主 Agent 的 skill 不会被继承下去,子 Agent 也不会污染主 Agent。前面提到的 PrivateStateAttr 就是为了这个隔离设计的。
agent = create_deep_agent( model="openai:gpt-4o-mini", backend=backend, skills=[".claude/skills/"], # 主 agent 用通用 skill subagents=[{ "name": "security-reviewer", "description": "Security audit specialist", "skills": [".claude/skills/security/"], # 子 agent 用专精 skill }],)
这是工程上很重要的一点——避免 skill 列表无脑膨胀到所有 Agent 都看到。
七、跟 Claude Code Skills 的实际差异(源码对照)
讲到这里,必须把「跨平台复用」这件事拆开看,不能只说「兼容」就过去。我把目前能确认的差异点列一下:
| 维度 | Claude Code | DeepAgents |
|---|---|---|
| SKILL.md 格式 | agentskills.io 规范 | 完全相同,可双向迁移 |
| 加载机制 | 进程启动时扫描 ~/.claude/skills/ 和 CWD 的 .claude/skills/ |
由 skills=[...] 参数显式指定 source 路径 |
| 激活方式 | LLM 决定(Progressive Disclosure) | LLM 决定(同 Progressive Disclosure) |
| scripts 执行 | 内置 Bash tool 直接跑 | 需要 backend 支持 execute tool(Sandbox / LocalShell) |
| allowed-tools 字段 | 严格执行(限制 skill 能调哪些 tool) | 仅当作元信息暴露给 LLM,不强制(截至当前版本) |
| 多 source 叠加 | user + project 两层,固定 | 任意多层,顺序自定义 |
最值得注意的一条:allowed-tools 字段。规范说它是 “experimental”,DeepAgents 在 _parse_allowed_tools 里只是把它读出来挂在 metadata 上,并不会真的强制限制 skill 能调哪些工具——它只会让 LLM 在 system prompt 看到这条信息。
也就是说,当前版本(截至 2026 年 6 月)DeepAgents 的 skill 安全边界靠的是 LLM 自己「听话」。如果你在生产环境用 skill 跑敏感操作,别只依赖 allowed-tools,要在 backend 层用 permissions 或者 HITL 拦一道。
这是规范 vs 实现的一个典型 gap,写文章不交代清楚就是不诚实。
八、什么时候别用 Skill
讲完优势,也讲讲不适合的场景。我自己踩过的:
8.1 输出需要严格确定性的场景
Skill 的执行靠 LLM 阅读理解 markdown,不同模型、不同温度、甚至同一模型不同 turn 都可能产出不一样。如果你的需求是「给我一个能严格按规则跑的 pipeline」,写 Tool 或者写一段确定性 Python 代码,别写 Skill。
我自己的判断标准:如果两个一线工程师严格按 SKILL.md 执行,产出会不会一致? 如果不会,那 LLM 执行也不会一致。
8.2 改动频繁的场景
Skill 写完是「固化」的——改一次就要重新测一次 LLM 在不同模型上的执行表现。如果你的 SOP 每周都在改,Skill 不如直接动态拼 prompt 来得灵活。
8.3 简单到不需要复用的场景
只用一次的指令,不要包装成 Skill。Skill 是为「跨项目、跨 Agent、跨人复用」存在的——一次性的事直接写在用户消息里就行。
8.4 LLM 不够强的场景
Progressive Disclosure 的工作原理是「让 LLM 自己决定要不要读 SKILL.md 全文」——这个决策对模型的 instruction following 能力有要求。
我自己在 gpt-4o-mini 上跑前面那个 sql-review 例子是稳定能激活的;但机制上,更弱的模型很可能出现两类问题:要么不激活 skill(白挂),要么激活了但不严格按 SKILL.md 步骤走。这跟 ReAct 模式在弱模型上经常跑飞是同一个原因。
建议做法:如果你用的不是 GPT-4 / Claude Sonnet 4 级别的模型,先用 LangSmith 把几个典型用户输入跑一遍 trace,确认 LLM 真的会发出read_file(SKILL.md, limit=1000) 的 tool_call 再上 skill——别把这件事的成功率当默认值。
九、Skill 不是新东西,但它把一件事变得便宜了
整篇笔记看到这里,可以收一下了。
Skill 这套机制从技术角度看一点都不复杂——它就是「Markdown 文档 + Progressive Disclosure 加载」。任何 Agent 框架都能在一周内自己实现一遍。
但它的真正价值在两个工程层面的小事:
第一,它定义了一个跨厂商的标准目录布局——.claude/skills/<name>/SKILL.md。我可以在 Claude Code 里写 skill,在 DeepAgents 里直接用;下次出现新框架,只要它实现 agentskills.io 规范,我的 skill 也能跑。这种「写一次到处跑」的能力对真正在生产环境维护 Agent 的人价值很大。
第二,它把 SOP / 最佳实践这种**「半结构化经验知识」**有了一个稳定的存放地点。以前这些东西要么散在 prompts/ 文件夹里没人管,要么塞进 system prompt 越塞越长。现在有了 SKILL.md,团队的领域专家把套路写下来,所有 Agent 都能受益。
但它没解决的事也要清楚:
- 不解决 LLM 执行的不确定性
- 不解决安全边界(allowed-tools 当前不强制)
- 不解决 skill 数量爆炸后的 description 撞车问题
- 不解决弱模型激活率低的问题
下一步该做哪一步:
- 如果你已经在用 Claude Code,先把现有 skill 挂到 DeepAgents 跑一遍 demo,确认能跑通
- 如果你在用 DeepAgents 但还没用 skill,先把一个你最常重复写的 SOP 抽成 SKILL.md——通常是「代码评审」「文档审阅」「数据探查」这类高频流程
- 如果你打算把 skill 上生产,先在 backend 层加 permissions,不要依赖 allowed-tools
Skill 不会让你的 Agent 突然变强,但它能让你少写很多重复 prompt——这对工程师就够了。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 6
6 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)