从零构建生产级RAG系统:基于Agent的多策略检索增强生成实战指南
本文详细介绍如何构建基于Agent的生产级RAG系统,通过工业设备维修手册案例,从数据预处理(多策略分块、清洗、摘要生成)到系统构建(规划、执行、反思、工具调用),再到评估验证,展示了完整开发流程。系统采用LangGraph实现智能体功能,通过多层次知识库和思维链推理技术,实现了高质量的知识问答和故障诊断能力,是学习大模型应用的实用指南。
本文详细介绍如何构建基于Agent的生产级RAG系统,通过工业设备维修手册案例,从数据预处理(多策略分块、清洗、摘要生成)到系统构建(规划、执行、反思、工具调用),再到评估验证,展示了完整开发流程。系统采用LangGraph实现智能体功能,通过多层次知识库和思维链推理技术,实现了高质量的知识问答和故障诊断能力,是学习大模型应用的实用指南。
目录
- 一、 整体架构设计:迈向智能体(Agent)驱动的 RAG
- 二、 数据准备与预处理:构建高质量知识库
- 2.1 数据加载与初步提取
- 2.2 多策略分块 (Multi-Strategy Chunking)
- 2.3 数据清洗
- 2.4 数据重构:摘要生成
- 2.5 向量化与存储
- 三、 核心 RAG 流程与智能体 (Agent) 构建
- 3.1 规划与执行:Agent 的决策核心
- 3.2 检索与蒸馏:构建可复用的子图
- 3.3 思维链 (CoT) 与幻觉抑制
- 四、 实战测试与效果评估
- 4.1 案例测试
- 4.2 使用 RAGAS 进行量化评估
- 五、 总结与展望
检索增强生成(Retrieval-Augmented Generation, RAG)已成为构建高级知识问答系统的核心技术。然而,从一个简单的原型到一个复杂、稳定且高效的生产级RAG系统,开发者需要跨越诸多挑战。本文将基于一个具体的实践案例------以某型号工业设备的故障维修手册为知识源,深入探讨如何设计并实现一个包含数据预处理、多策略检索、智能体规划、思维链(CoT)推理及自动化评估的完备RAG 系统。
我们将使用 LangChain、LangGraph和 RAGAS等前沿工具,为您展示从原始数据到最终高质量回答的全链路技术细节与开发思路。
一、 整体架构设计:迈向智能体(Agent)驱动的 RAG
一个生产级的 RAG 系统远不止"检索+生成"那么简单。它应该是一个能够自我规划、决策和反思的智能系统。我们的目标是构建一个基于Agent 的 RAG流程,其核心思想是将复杂问题拆解为一系列可执行的子任务,并通过工具调用来完成。
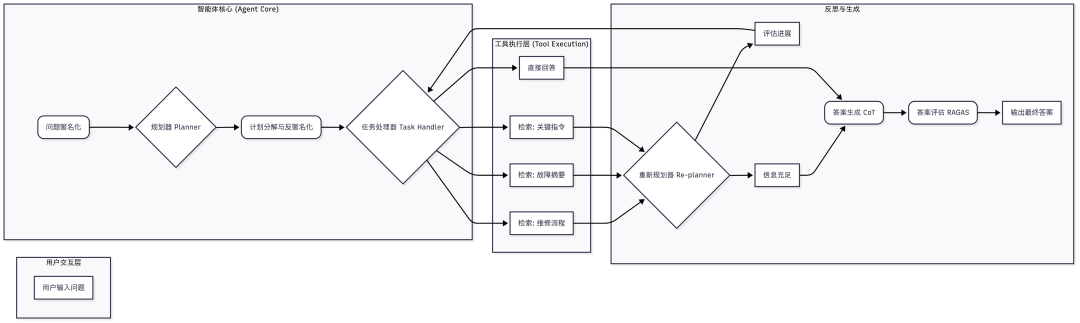
最终实现的 Agentic RAG 系统工作流
该架构的核心步骤包括:
- **问题匿名化 (Anonymization)**:为消除大模型预训练知识带来的偏见,首先将问题中的具体实体(如"V12型涡轮增压柴油发动机")替换为通用变量(如"设备X")。
- **规划 (Planning)**:Agent 根据匿名化的问题,生成一个高层次的解决步骤计划。
- **计划分解与反匿名化 (Plan Breakdown & De-Anonymization)**:将高层计划分解为具体的、可由工具执行的子任务,并恢复原始实体名称。
- **任务处理 (Task Handling)**:任务处理器根据当前子任务,选择最合适的工具,如不同类型的检索器或直接回答。
- **工具执行 (Tool Execution)**:执行选定的工具,例如从不同的向量数据库中检索信息(如故障代码表、维修流程章节、关键参数说明)。
- **重新规划 (Re-planning)**:根据新获取的信息,Agent 评估当前进展,判断是否需要调整或扩展计划。这是一个关键的循环与反思步骤。
- **答案生成与评估 (Answer Generation & Evaluation)**:当 Agent 判断已收集足够信息时,调用生成模块(结合 CoT 推理)生成最终答案,并由评估模块(如 RAGAS)进行质量检查。
二、 数据准备与预处理:构建高质量知识库
高质量的知识库是 RAG系统性能的基石。我们将以《V12型涡轮增压柴油发动机维修手册》的 PDF 文件为例,展示一套完整的数据处理流程。
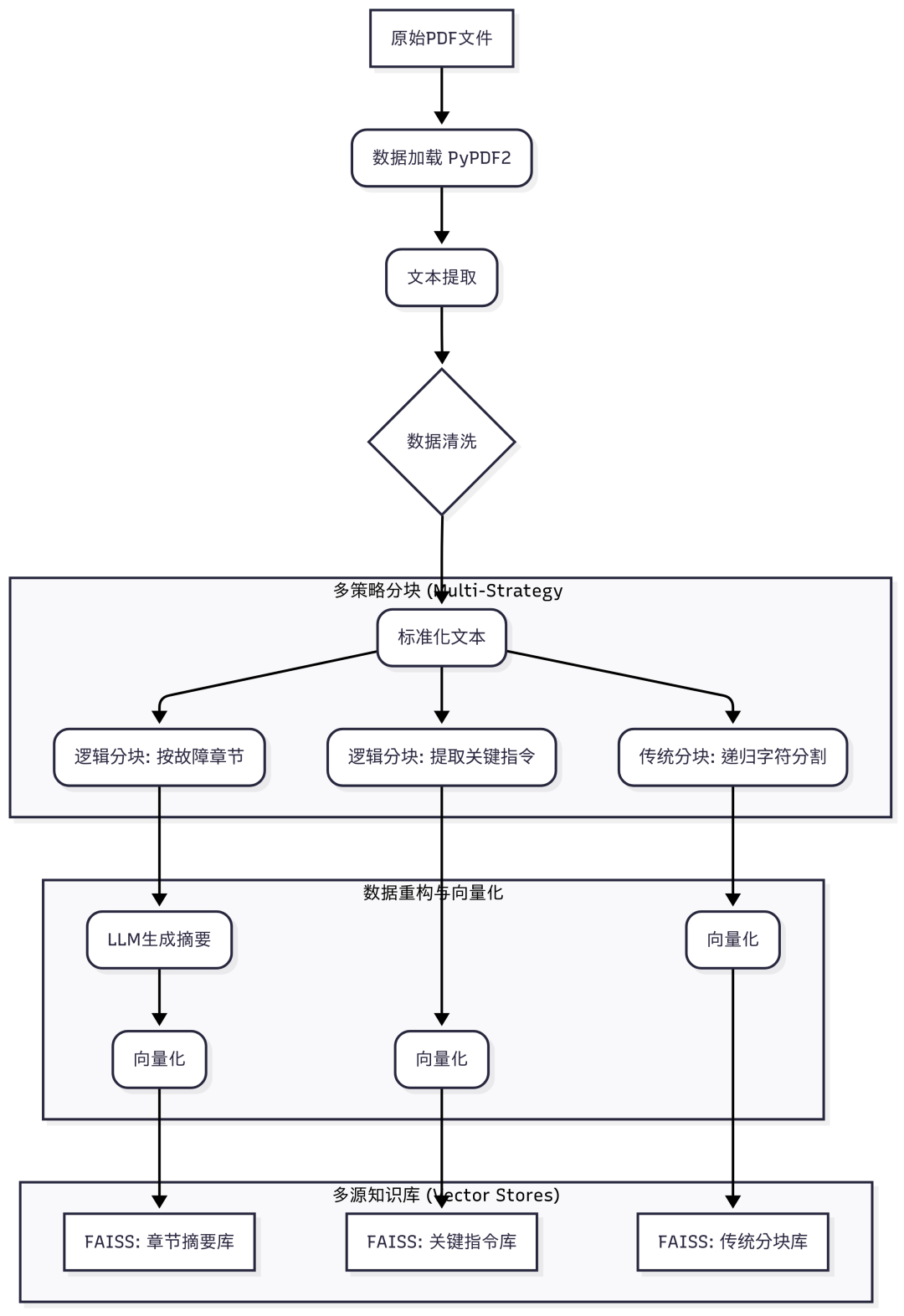
从原始PDF到多源向量数据库的数据处理全流程
2.1 数据加载与初步提取
首先,我们使用 PyPDF2库从 PDF 文件中提取原始文本。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
import PyPDF2
from PyPDF2.errors import PdfReadError
import logging
from pathlib import Path
from typing import Optional
# ----------------------------------------------------------------
# 2. 日志配置 (Logging Configuration)
# ----------------------------------------------------------------
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# ----------------------------------------------------------------
# 3. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defload_and_extract_text_from_pdf(pdf_path: Path) -> Optional[str]:
"""
从指定的PDF文件中加载并提取所有页面的文本内容。
Args:
pdf_path (Path): 指向PDF文件的Path对象。
Returns:
Optional[str]: 包含PDF所有文本内容的字符串,如果失败则返回None。
"""
ifnot pdf_path.is_file():
logging.error(f"文件未找到: {pdf_path}")
returnNone
logging.info(f"开始从 {pdf_path.name} 提取文本...")
try:
with open(pdf_path, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
# 检查PDF是否被加密
if pdf_reader.is_encrypted:
logging.warning(f"PDF文件 {pdf_path.name} 已加密,可能无法提取文本。")
pages_text = [page.extract_text() for page in pdf_reader.pages if page.extract_text()]
full_text = " ".join(pages_text)
logging.info(f"成功提取 {len(pdf_reader.pages)} 页, 共 {len(full_text)} 字符。")
return full_text
except FileNotFoundError:
logging.error(f"文件在读取时未找到: {pdf_path}")
returnNone
except PdfReadError as e:
logging.error(f"读取PDF文件时出错: {pdf_path}. 错误: {e}")
returnNone
except Exception as e:
logging.error(f"提取文本时发生未知错误: {e}")
returnNone
# ----------------------------------------------------------------
# 4. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 创建一个虚拟的PDF文件用于演示
manual_path = Path("V12-Engine-Maintenance-Manual.pdf")
ifnot manual_path.exists():
logging.warning(f"演示文件 {manual_path} 不存在。请将您的PDF文件放在此路径。")
else:
full_text_content = load_and_extract_text_from_pdf(manual_path)
if full_text_content:
print("\n--- 提取的文本 (前500字符) ---")
print(full_text_content[:500])
print("...")
else:
print("\n文本提取失败。")
2.2 多策略分块 (Multi-Strategy Chunking)
单一的分块策略难以适应所有查询类型。因此,我们采用多种策略并行处理,构建不同粒度的知识索引,以应对不同类型的查询需求。
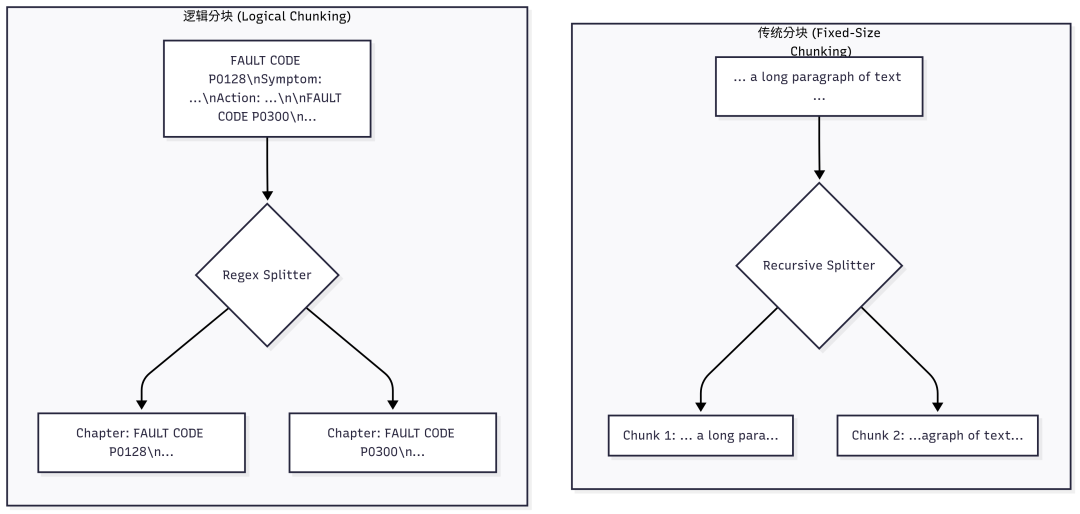
逻辑分块:按故障章节和关键说明
利用文本的内在结构(如故障代码章节)或特定模式(如警告、注意等关键说明)进行分块,可以保留更完整的语义信息。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
import re
from typing import List
from langchain.docstore.document import Document
# ----------------------------------------------------------------
# 2. 功能实现 (Function Implementations)
# ----------------------------------------------------------------
defchunk_by_fault_code(text: str) -> List[Document]:
"""
使用正则表达式按 'FAULT CODE XXX' 模式将文本分割成章节。
Args:
text (str): 完整的文本内容。
Returns:
List[Document]: 按故障代码章节分割的 LangChain Document 对象列表。
"""
# 正则表达式 r'(FAULT CODE\s[A-Z0-9]+.*)' 匹配 "FAULT CODE " 后跟字母数字组合的行,并捕获该行。
# re.split 会保留捕获的分隔符,结果列表将是 [text_before, separator, text_after, separator, ...]
chapter_sections = re.split(r'(FAULT CODE\s[A-Z0-9]+.*)', text)
chapters = []
# 从索引1开始,步长为2,将分隔符(章节标题)与其后的内容合并
for i in range(1, len(chapter_sections), 2):
title = chapter_sections[i].strip()
content = chapter_sections[i + 1].strip()
chapter_text = title + "\n" + content
# 提取故障代码作为元数据
fault_code_match = re.search(r'FAULT CODE\s([A-Z0-9]+)', title)
fault_code = fault_code_match.group(1) if fault_code_match else"UNKNOWN"
doc = Document(
page_content=chapter_text,
metadata={"source": "fault_code_section", "fault_code": fault_code}
)
chapters.append(doc)
logging.info(f"按故障代码逻辑分块,共找到 {len(chapters)} 个章节。")
return chapters
defextract_key_instructions(documents: List[Document], keyword: str = "WARNING", min_length: int = 50) -> List[Document]:
"""
从文档列表中提取包含特定关键字(如WARNING, NOTE)的关键指令段落。
Args:
documents (List[Document]): 待提取的文档列表。
keyword (str): 要查找的关键字 (不区分大小写)。
min_length (int): 提取内容的最小字符长度。
Returns:
List[Document]: 包含关键指令的 LangChain Document 对象列表。
"""
# 正则表达式匹配以关键字开头,后跟至少 min_length 个字符,直到下一个空行或文本末尾。
# re.DOTALL 使 '.' 可以匹配换行符。
# re.IGNORECASE 使关键字匹配不区分大小写。
pattern = re.compile(rf'({keyword.upper()}:(.{{{min_length},}}?))(?=\n\n|\Z)', re.DOTALL | re.IGNORECASE)
key_instructions = []
for doc in documents:
found_matches = pattern.findall(doc.page_content)
for match in found_matches:
instruction_text = match[0].strip()
new_doc = Document(
page_content=instruction_text,
metadata={"source": "key_instruction", "type": keyword.lower()}
)
key_instructions.append(new_doc)
logging.info(f"提取了 {len(key_instructions)} 条 '{keyword}' 类型的关键指令。")
return key_instructions
# ----------------------------------------------------------------
# 3. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 假设 full_text_content 是上一步提取的PDF全文
sample_text = """
Section 1: Introduction.
FAULT CODE P0128 Coolant Thermostat Malfunction. This indicates the engine has not reached the required operating temperature.
Check coolant levels first.
WARNING: Engine may be hot. Allow it to cool down before servicing. Risk of severe burns.
Section 2: Troubleshooting.
FAULT CODE P0300 Random Misfire Detected. This can be caused by a variety of issues.
NOTE: Check spark plugs and ignition coils.
WARNING: High voltage present. Disconnect battery before working on ignition system.
"""
# 1. 按故障代码分块
chapters = chunk_by_fault_code(sample_text)
print("\n--- 按故障代码分块结果 ---")
for i, chapter in enumerate(chapters):
print(f"Chapter {i+1} (Metadata: {chapter.metadata}):\n{chapter.page_content[:100]}...\n")
# 2. 提取关键指令 (WARNING)
warnings = extract_key_instructions(chapters, keyword="WARNING", min_length=30)
print("\n--- 提取的 'WARNING' 指令 ---")
for warning in warnings:
print(f"Instruction (Metadata: {warning.metadata}):\n{warning.page_content}\n")
传统分块:递归字符分割
对于没有明显结构的部分,使用重叠的固定大小分块是常用方法。RecursiveCharacterTextSplitter能够智能地在段落、句子等边界进行分割。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
from typing import List
import logging
# ----------------------------------------------------------------
# 2. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defsplit_documents_recursively(
documents: List[Document],
chunk_size: int = 1000,
chunk_overlap: int = 200
) -> List[Document]:
"""
使用 RecursiveCharacterTextSplitter 对文档列表进行分割。
Args:
documents (List[Document]): 待分割的 LangChain Document 对象列表。
chunk_size (int): 每个块的最大字符数。
chunk_overlap (int): 相邻块之间的重叠字符数。
Returns:
List[Document]: 分割后的 LangChain Document 对象列表。
"""
logging.info(
f"开始递归分割文档... "
f"Chunk Size: {chunk_size}, Chunk Overlap: {chunk_overlap}"
)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
# 优先按双换行符、单换行符、空格、空字符分割
separators=["\n\n", "\n", " ", ""],
length_function=len,
)
split_docs = text_splitter.split_documents(documents)
logging.info(f"成功将 {len(documents)} 个文档分割成 {len(split_docs)} 个块。")
return split_docs
# ----------------------------------------------------------------
# 3. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 假设 documents 是之前清洗过的文档列表
long_text = "A" * 1500 + "\n\n" + "B" * 800
documents_to_split = [Document(page_content=long_text, metadata={"source": "general_content"})]
document_splits = split_documents_recursively(documents_to_split)
print("\n--- 递归分割结果 ---")
for i, split in enumerate(document_splits):
print(f"Split {i+1}: Length={len(split.page_content)}, Metadata={split.metadata}")
print(f"Content starts with: '{split.page_content[:30]}...'")
print(f"Content ends with: '...{split.page_content[-30:]}'\n")
2.3 数据清洗
从 PDF提取的文本通常包含格式问题,如多余的空格、换行符等。使用正则表达式进行标准化清洗,可以显著提升后续处理的质量和效率。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
import re
from typing import List
from langchain.docstore.document import Document
# ----------------------------------------------------------------
# 2. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defclean_text(text: str) -> str:
"""
对单段文本进行标准化清洗。
- 将多个连续换行符替换为单个换行符。
- 合并被换行符分割的单词 (e.g., "ma- nual" -> "manual")。
- 将所有换行符替换为空格。
- 将多个连续空格替换为单个空格。
Args:
text (str): 待清洗的原始文本。
Returns:
str: 清洗后的文本。
"""
# 1. 将多个换行符(及之间的空格)合并为一个
text = re.sub(r'\n\s*\n', '\n', text)
# 2. 合并被换行符错误分割的单词
text = re.sub(r'(\w)-\n(\w)', r'\1\2', text)
# 3. 将剩余的换行符转换为空格
text = text.replace('\n', ' ')
# 4. 将多个空格合并为一个
text = re.sub(r' +', ' ', text)
return text.strip()
defclean_documents(documents: List[Document]) -> List[Document]:
"""
对整个文档列表的内容进行清洗。
Args:
documents (List[Document]): 待清洗的文档列表。
Returns:
List[Document]: 内容已被清洗的文档列表 (原地修改)。
"""
logging.info(f"开始清洗 {len(documents)} 个文档...")
for doc in documents:
doc.page_content = clean_text(doc.page_content)
logging.info("文档清洗完成。")
return documents
# ----------------------------------------------------------------
# 2. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defclean_text(text: str) -> str:
"""
对单段文本进行标准化清洗。
- 将多个连续换行符替换为单个换行符。
- 合并被换行符分割的单词 (e.g., "ma- nual" -> "manual")。
- 将所有换行符替换为空格。
- 将多个连续空格替换为单个空格。
Args:
text (str): 待清洗的原始文本。
Returns:
str: 清洗后的文本。
"""
# 1. 将多个换行符(及之间的空格)合并为一个
text = re.sub(r'\n\s*\n', '\n', text)
# 2. 合并被换行符错误分割的单词
text = re.sub(r'(\w)-\n(\w)', r'\1\2', text)
# 3. 将剩余的换行符转换为空格
text = text.replace('\n', ' ')
# 4. 将多个空格合并为一个
text = re.sub(r' +', ' ', text)
return text.strip()
defclean_documents(documents: List[Document]) -> List[Document]:
"""
对整个文档列表的内容进行清洗。
Args:
documents (List[Document]): 待清洗的文档列表。
Returns:
List[Document]: 内容已被清洗的文档列表 (原地修改)。
"""
logging.info(f"开始清洗 {len(documents)} 个文档...")
for doc in documents:
doc.page_content = clean_text(doc.page_content)
logging.info("文档清洗完成。")
return documents
# ----------------------------------------------------------------
# 3. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
raw_text = """
This is an example\n\nof some poorly\nformatted text.
Another issue is a word split by a new-\nline.
"""
raw_doc = Document(page_content=raw_text)
print("--- 清洗前 ---")
print(repr(raw_doc.page_content))
cleaned_docs = clean_documents([raw_doc])
print("\n--- 清洗后 ---")
print(repr(cleaned_docs[0].page_content))
2.4 数据重构:摘要生成
对于故障章节这样的大块文本,直接向量化可能包含大量噪声。我们可以利用 LLM生成章节摘要,创建一个高度浓缩、信息密集的知识索引。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
from langchain.prompts import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_community.chat_models.ollama import ChatOllama # 示例使用Ollama
from typing import List
import logging
# ----------------------------------------------------------------
# 2. 模型和Prompt配置 (Model and Prompt Configuration)
# ----------------------------------------------------------------
# 摘要生成提示词模板
SUMMARIZATION_TEMPLATE = """
Please provide a comprehensive and detailed summary of the following maintenance chapter.
Focus on the key symptoms, diagnostic steps, and required actions.
The summary should be clear, concise, and directly usable by a technician.
CHAPTER TEXT:
"{text}"
DETAILED SUMMARY:
"""
summarization_prompt = PromptTemplate(
template=SUMMARIZATION_TEMPLATE,
input_variables=["text"]
)
# ----------------------------------------------------------------
# 3. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defgenerate_summaries_for_documents(
documents: List[Document],
llm: BaseChatModel
) -> List[Document]:
"""
为文档列表中的每个文档生成摘要。
Args:
documents (List[Document]): 需要生成摘要的文档列表。
llm (BaseChatModel): 用于生成摘要的语言模型实例。
Returns:
List[Document]: 包含摘要内容的新文档列表,元数据被保留。
"""
# 使用 "stuff" chain type,它会将所有文本一次性放入prompt中。
# 这适用于文本块不是特别长的情况。对于超长文本,可考虑 "map_reduce"。
chain = load_summarize_chain(llm, chain_type="stuff", prompt=summarization_prompt)
summaries = []
logging.info(f"开始为 {len(documents)} 个文档生成摘要...")
for i, doc in enumerate(documents):
try:
logging.info(f"正在处理文档 {i+1}/{len(documents)}...")
result = chain.invoke([doc])
summary_text = result["output_text"]
# 创建新的摘要文档,并复制原始元数据
summary_doc = Document(
page_content=summary_text,
metadata=doc.metadata.copy()
)
summaries.append(summary_doc)
except Exception as e:
logging.error(f"为文档 {i+1} 生成摘要时出错: {e}")
continue
logging.info(f"成功生成 {len(summaries)} 篇摘要。")
return summaries
# ----------------------------------------------------------------
# 4. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 初始化一个LLM。请确保你已安装并运行了Ollama,并下载了相应模型。
# 例如: `ollama run qwen2:1.5b`
# 如果使用OpenAI, 替换为: from langchain_openai import ChatOpenAI; llm = ChatOpenAI(model="gpt-4o")
try:
llm = ChatOllama(model="qwen2:1.5b", temperature=0)
# 检查模型是否可用
llm.invoke("Hi")
except Exception as e:
logging.error(f"无法初始化或连接到LLM: {e}\n将使用一个模拟的LLM进行演示。")
from langchain.chat_models.fake import FakeListChatModel
llm = FakeListChatModel(responses=["This is a mock summary for the provided chapter."])
# 假设 chapters 是之前按故障代码分块的文档列表
chapters_to_summarize = [
Document(
page_content="FAULT CODE P0128: ... [very long text about diagnostics] ...",
metadata={"source": "fault_code_section", "fault_code": "P0128"}
)
]
chapter_summaries = generate_summaries_for_documents(chapters_to_summarize, llm)
print("\n--- 生成的摘要 ---")
for summary in chapter_summaries:
print(f"Summary (Metadata: {summary.metadata}):\n{summary.page_content}\n")
2.5 向量化与存储
最后,我们将处理好的三种数据(传统分块、章节摘要、关键说明)分别进行向量化,并使用高效的 FAISS库存储为三个独立的向量数据库。这使得 Agent后续可以根据任务类型,选择从最合适的知识源中检索信息。
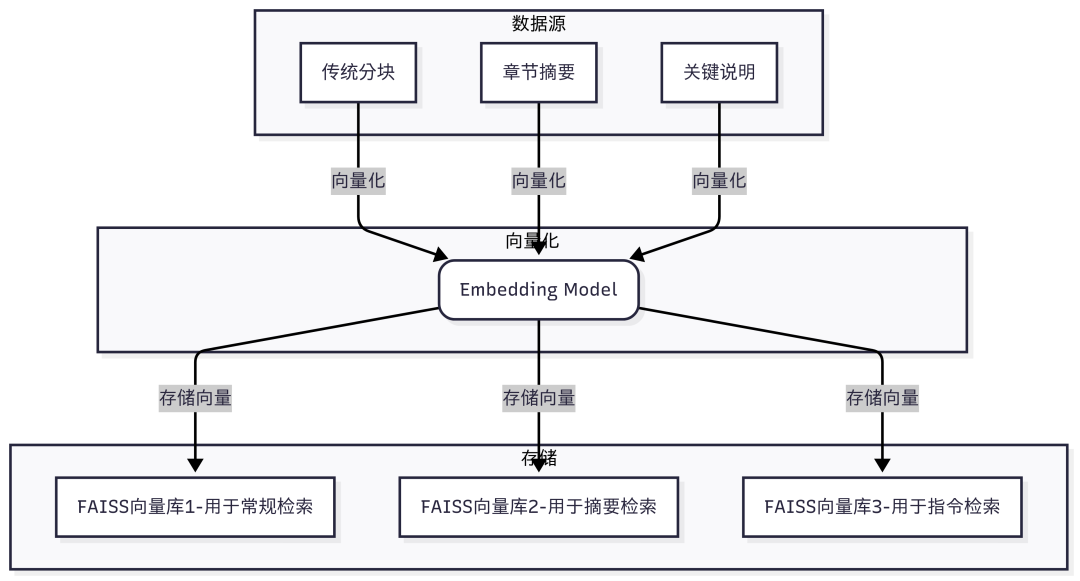
多源数据向量化流程
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
from langchain_community.vectorstores import FAISS
from langchain_core.embeddings import Embeddings
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings # 示例使用HuggingFace模型
from langchain.docstore.document import Document
from typing import List, Dict
from pathlib import Path
import logging
import shutil
# ----------------------------------------------------------------
# 2. 功能实现 (Function Implementation)
# ----------------------------------------------------------------
defcreate_and_save_vector_stores(
data_collections: Dict[str, List[Document]],
embedding_model: Embeddings,
save_dir: Path
):
"""
为多个文档集合创建并保存FAISS向量存储。
Args:
data_collections (Dict[str, List[Document]]): 一个字典,键是向量存储的名称,值是文档列表。
embedding_model (Embeddings): 用于向量化的嵌入模型实例。
save_dir (Path): 保存所有向量存储的根目录。
"""
save_dir.mkdir(parents=True, exist_ok=True)
for name, docs in data_collections.items():
store_path = save_dir / name
ifnot docs:
logging.warning(f"数据集合 '{name}' 为空,跳过创建向量存储。")
continue
logging.info(f"为 '{name}' 创建向量存储 (包含 {len(docs)} 个文档)...")
try:
vectorstore = FAISS.from_documents(docs, embedding_model)
# 保存到本地
vectorstore.save_local(str(store_path))
logging.info(f"向量存储 '{name}' 已保存到: {store_path}")
except Exception as e:
logging.error(f"创建或保存向量存储 '{name}' 时出错: {e}")
# ----------------------------------------------------------------
# 3. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 初始化嵌入模型。推荐使用与你的LLM匹配或性能优良的小型模型。
# `bge-small-en-v1.5` 是一个常用的高性能英文嵌入模型。
model_name = "BAAI/bge-small-en-v1.5"
model_kwargs = {'device': 'cpu'} # 如果有GPU,可以改为 'cuda'
encode_kwargs = {'normalize_embeddings': True} # 归一化以使用余弦相似度
try:
embedding_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
except Exception as e:
logging.error(f"无法加载HuggingFace嵌入模型: {e}\n将使用一个模拟模型进行演示。")
from langchain_community.embeddings.fake import FakeEmbeddings
embedding_model = FakeEmbeddings(size=384) # bge-small-en-v1.5的维度是384
# 准备三组模拟数据
document_splits = [Document(page_content="This is a small chunk of text.")]
chapter_summaries = [Document(page_content="Summary of fault code P0128.")]
key_instructions = [Document(page_content="WARNING: Disconnect the battery.")]
all_data = {
"manual_splits_vectorstore": document_splits,
"chapter_summaries_vectorstore": chapter_summaries,
"instructions_vectorstore": key_instructions
}
vectorstore_directory = Path("./rag_vectorstores")
create_and_save_vector_stores(all_data, embedding_model, vectorstore_directory)
# 演示如何加载已保存的向量存储
if (vectorstore_directory / "instructions_vectorstore").exists():
logging.info("\n--- 加载并测试已保存的向量存储 ---")
loaded_instructions_vs = FAISS.load_local(
str(vectorstore_directory / "instructions_vectorstore"),
embedding_model,
allow_dangerous_deserialization=True# FAISS需要此参数
)
retrieved_docs = loaded_instructions_vs.similarity_search("safety warning")
print(f"对 'safety warning' 的检索结果: {retrieved_docs}")
# 清理创建的目录
# shutil.rmtree(vectorstore_directory)
# logging.info(f"已清理演示目录: {vectorstore_directory}")
学习大模型 AI 如何助力提升市场竞争优势?
随着新技术的不断涌现,特别是在人工智能领域,大模型的应用正逐渐成为提高社会生产效率的关键因素。这些先进的技术工具不仅优化了工作流程,还极大地提升了工作效率。然而,对于个人而言,掌握这些新技术的时间差异将直接影响到他们的竞争优势。正如在计算机、互联网和移动互联网的早期阶段所展现的那样,那些最先掌握新技术的人往往能够在职场中占据先机。
掌握 AI 大模型技能,不仅能够提高个人工作效率,还能增强在求职市场上的竞争力。在当今快速发展的技术时代,大模型 AI 已成为推动市场竞争力的重要力量。个人和企业必须迅速适应这一变化,以便在市场中保持领先地位。
如何学习大模型 AI ?
在我超过十年的互联网企业工作经验中,我有幸指导了许多同行和后辈,并帮助他们实现个人成长和学习进步。我深刻认识到,分享经验和知识对于推动整个行业的发展至关重要。因此,尽管工作繁忙,我仍然致力于整理和分享各种有价值的AI大模型资料,包括AI大模型入门学习思维导图、精选学习书籍手册、视频教程以及实战学习等内容。通过这些免费的资源,我希望能够帮助更多的互联网行业朋友获取正确的学习资料,进而提升大家的技能和竞争力。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、初阶应用:建立AI基础认知
在第一阶段(10天),重点是对大模型 AI 的基本概念和功能进行深入了解。这将帮助您在相关讨论中发表高级、独特的见解,而不仅仅是跟随他人。您将学习如何调教 AI,以及如何将大模型与业务相结合。
主要学习内容:
- 大模型AI的功能与应用场景:探索AI在各个领域的实际应用
- AI智能的起源与进化:深入了解AI如何获得并提升其智能水平
- AI的核心原理与心法:掌握AI技术的核心概念和关键原理
- 大模型应用的业务与技术架构:学习如何将大模型AI应用于业务场景和技术架构中
- 代码实践:向GPT-3.5注入新知识的示例代码
- 提示工程的重要性与核心思想:理解提示工程在AI应用中的关键作用
- Prompt的构建与指令调优方法:学习如何构建有效的Prompt和进行指令调优
- 思维链与思维树的应用:掌握思维链和思维树在AI推理和决策中的作用
- Prompt攻击与防范策略:了解Prompt攻击的类型和如何进行有效的防范


、、、
二、中阶应用:深入AI实战开发
在第二阶段(30天),您将进入大模型 AI 的进阶实战学习。这将帮助您构建私有知识库,扩展 AI 的能力,并快速开发基于 agent 的对话机器人。适合 Python 和 JavaScript 程序员。
主要学习内容:
- RAG的重要性:理解RAG在AI应用中的关键作用
- 构建基础ChatPDF:动手搭建一个简单的ChatPDF应用
- 检索基础:掌握信息检索的基本概念和原理
- 理解向量表示:深入探讨Embeddings的原理和应用
- 向量数据库与检索技术:学习如何使用向量数据库进行高效检索
- 基于 vector 的 RAG 实现:掌握基于向量的RAG构建方法
- RAG系统的高级扩展:探索RAG系统的进阶知识和技巧
- 混合检索与RAG-Fusion:了解混合检索和RAG-Fusion的概念和应用
- 向量模型的本地部署策略:学习如何在本地环境中部署向量模型

三、高阶应用:模型训练
在这个阶段,你将掌握模型训练的核心技术,能够独立训练和优化大模型AI。你将了解模型训练的基本概念、技术和方法,并能够进行实际操作。
- 模型训练的意义:理解为什么需要进行模型训练。
- 模型训练的基本概念:学习模型训练的基本术语和概念。
- 求解器与损失函数:了解求解器和损失函数在模型训练中的作用。
- 神经网络训练实践:通过实验学习如何手写一个简单的神经网络并进行训练。
- 训练与微调:掌握训练、预训练、微调和轻量化微调的概念和应用。
- Transformer结构:了解Transformer的结构和原理。
- 轻量化微调:学习如何进行轻量化微调以优化模型性能。
- 实验数据集构建:掌握如何构建和准备实验数据集。

四、专家应用:AI商业应用与创业
在这个阶段,你将了解全球大模型的性能、吞吐量和成本等方面的知识,能够在云端和本地等多种环境下部署大模型。你将找到适合自己的项目或创业方向,成为一名被AI武装的产品经理。
- 硬件选型:学习如何选择合适的硬件来部署和运行大模型AI。
- 全球大模型概览:了解全球大模型的发展趋势和主要玩家。
- 国产大模型服务:探索国产大模型服务的优势和特点。
- OpenAI代理搭建:学习如何搭建OpenAI代理以扩展AI的功能和应用范围。
- 热身练习:在阿里云 PAI 上部署 Stable Diffusion
- 本地化部署:在个人计算机上运行大型模型
- 私有化部署策略:大型模型的内部部署方法
- 利用 vLLM 进行模型部署:高效部署大型模型的技术
- 案例分析:如何在阿里云上优雅地私有部署开源大型模型
- 开源 LLM 项目的全面部署:从零开始部署开源大型语言模型
- 内容安全与合规:确保AI应用的内容安全和合规性
- 算法备案流程:互联网信息服务算法的备案指南
通过这些学习内容,您不仅能够掌握大模型 AI 的基本技能,还能够深入理解其高级应用,从而在市场竞争中占据优势。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你无疑是AI领域的佼佼者。然而,即使你只能完成60-70%的内容,你也已经展现出了成为一名大模型AI大师的潜力。
最后,本文提供的完整版大模型 AI 学习资料已上传至 CSDN,您可以通过微信扫描下方的 CSDN 官方认证二维码免费领取【保证100%免费】。
三、 核心 RAG 流程与智能体 (Agent) 构建
有了高质量的知识库,我们开始构建 RAG 系统的"大脑"------一个基于LangGraph的智能体。LangGraph允许我们用图(Graph)的形式定义复杂、有状态、可循环的工作流,非常适合实现 Agent 的规划、执行与反思逻辑。
3.1 规划与执行:Agent 的决策核心
Agent 的核心能力在于规划。我们通过一系列精心设计的 Prompt 和 LLM Chain来实现这一能力。
Planner & Re-planner
Planner 负责生成初始计划,而 Re-planner则在每一步执行后,根据新信息动态调整计划。
重新规划器 Prompt (摘录):
你的目标是: {question}
你的原始计划是: {plan}
你当前已完成以下步骤: {past_steps}
你已掌握以下上下文信息: {aggregated_context}
请据此更新你的计划。如果需要更多步骤,请仅填写这些新增的步骤。
Task Handler
任务处理器是计划的执行者。它接收一个任务,并决定调用哪个工具来完成。这使得系统具有极高的灵活性和可扩展性。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
from pydantic import BaseModel, Field
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_community.chat_models.ollama import ChatOllama
import logging
# ----------------------------------------------------------------
# 2. Pydantic 输出模型定义 (Pydantic Output Model)
# ----------------------------------------------------------------
classTaskHandlerOutput(BaseModel):
"""定义任务处理器LLM调用的输出结构。"""
query: str = Field(description="The specific query to be used for the chosen tool. This could be a search term or a question.")
curr_context: str = Field(description="The context to be used for answering the question, if the tool is 'answer_question'.")
tool: Literal['retrieve_chunks', 'retrieve_summaries', 'retrieve_instructions', 'answer_question'] = Field(
description="The specific tool to be used to accomplish the current task."
)
# ----------------------------------------------------------------
# 3. Prompt 模板 (Prompt Template)
# ----------------------------------------------------------------
TASK_HANDLER_PROMPT_TEMPLATE = """
You are an expert task handler in a RAG system for industrial maintenance.
Your role is to analyze the current task and select the most appropriate tool to execute it.
**Available Tools:**
- `retrieve_chunks`: Use this to find specific, detailed information from the raw maintenance manual. Best for precise technical data or step-by-step procedures.
- `retrieve_summaries`: Use this to get a high-level overview of a fault code or a complex chapter. Best for understanding the general context of a problem.
- `retrieve_instructions`: Use this to find critical safety warnings, notes, or cautions related to a task.
- `answer_question`: Use this ONLY when you have gathered enough context to formulate a final answer.
**Current Context:**
You have access to the original question and the aggregated information gathered so far.
Original Question: {question}
Aggregated Context: {aggregated_context}
**Current Task:**
Your current task is: **{curr_task}**
Based on the current task, which tool should you use? What query should you pass to it?
Provide your response in the required JSON format.
"""
# ----------------------------------------------------------------
# 4. 构建并测试 Chain (Build and Test the Chain)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 初始化LLM
try:
task_handler_llm = ChatOllama(model="qwen2:1.5b", temperature=0, format='json')
task_handler_llm.invoke("Hi")
except Exception as e:
logging.error(f"LLM初始化失败: {e}. 将使用模拟LLM。")
from langchain.chat_models.fake import FakeListChatModel
import json
mock_response = TaskHandlerOutput(
query="meaning of fault code P0128",
curr_context="",
tool='retrieve_summaries'
)
task_handler_llm = FakeListChatModel(responses=[json.dumps(mock_response.dict())])
# 创建Prompt
task_handler_prompt = ChatPromptTemplate.from_template(TASK_HANDLER_PROMPT_TEMPLATE)
# 构建完整的Chain,它会自动将LLM的输出解析为Pydantic对象
task_handler_chain = task_handler_prompt | task_handler_llm.with_structured_output(TaskHandlerOutput)
# 模拟输入
input_data = {
"question": "What does fault code P0128 mean and how do I fix it?",
"aggregated_context": "",
"curr_task": "First, understand what fault code P0128 means."
}
print("\n--- 测试任务处理器 Chain ---")
print(f"输入: {input_data}")
# 调用Chain
output = task_handler_chain.invoke(input_data)
print(f"\n输出类型: {type(output)}")
print(f"输出内容: {output}")
print(f"选择的工具: {output.tool}")
print(f"生成的查询: {output.query}")
3.2 检索与蒸馏:构建可复用的子图
为了使系统模块化,我们将每种检索操作封装成一个独立的 LangGraph子图。每个子图都包含"检索"和"蒸馏"(过滤无关信息)两个步骤,并有自己的循环逻辑以确保检索质量。
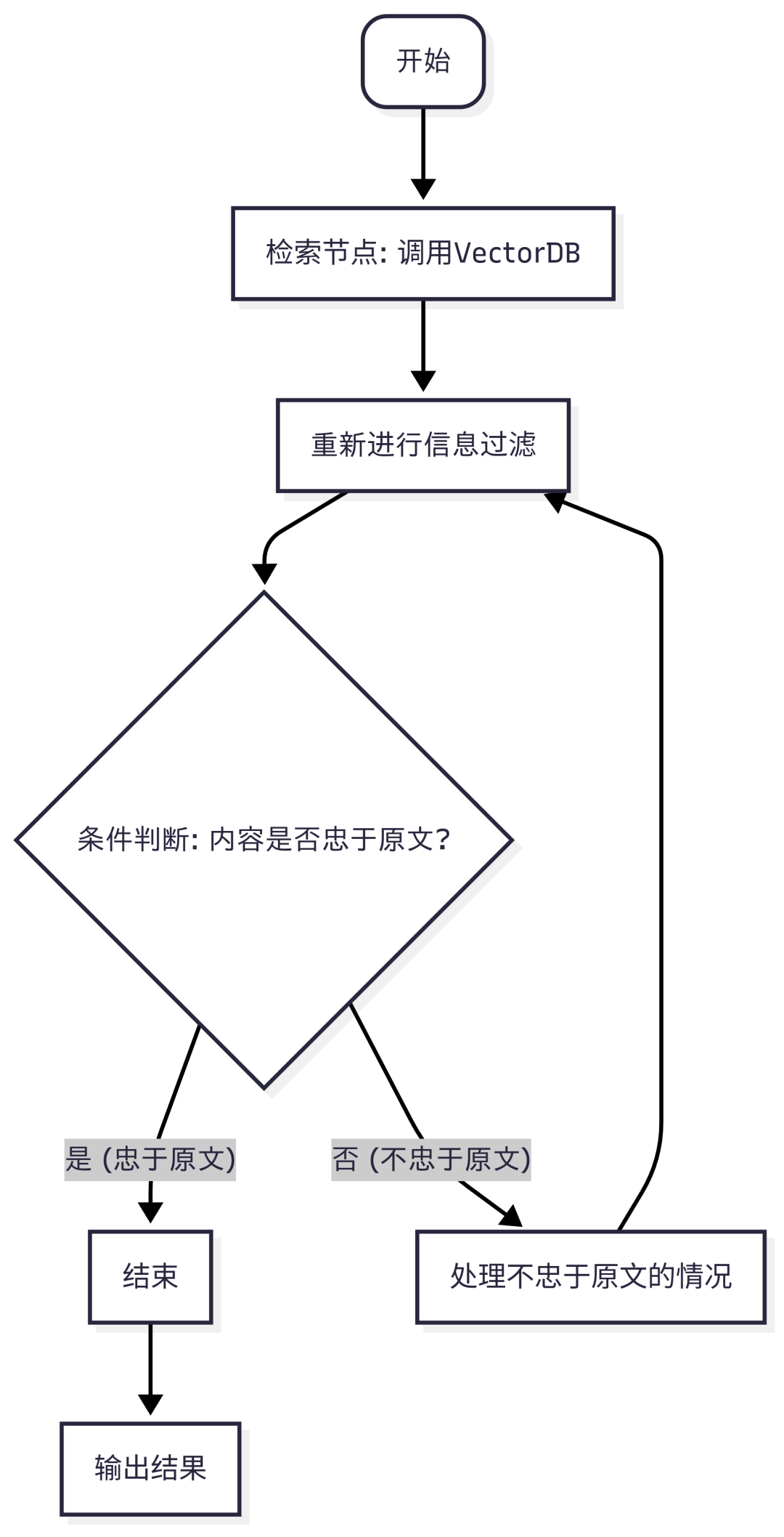
为不同数据源构建的独立检索子图
通过一个高阶函数,我们可以轻松地为不同检索器构建工作流。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
from typing import List, TypedDict, Annotated, Literal, Callable
from langgraph.graph import StateGraph, END
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
import logging
# ----------------------------------------------------------------
# 2. 定义图的状态 (Define Graph State)
# ----------------------------------------------------------------
classQualitativeRetrievalGraphState(TypedDict):
"""定义检索子图的状态。"""
query: str
retrieved_docs: List[Document]
distilled_docs: List[Document]
is_grounded: bool
# ----------------------------------------------------------------
# 3. 定义图的节点和条件边 (Define Nodes and Conditional Edges)
# (这些是模拟实现,实际项目中需要接入LLM和评估逻辑)
# ----------------------------------------------------------------
defcreate_retrieval_node(retriever: BaseRetriever):
"""创建一个包装了特定检索器的节点函数。"""
defretrieve_node(state: QualitativeRetrievalGraphState):
logging.info(f"节点 [{retriever.__class__.__name__}]: 正在用查询 '{state['query']}' 进行检索...")
retrieved_docs = retriever.invoke(state['query'])
return {"retrieved_docs": retrieved_docs}
return retrieve_node
defkeep_only_relevant_content(state: QualitativeRetrievalGraphState):
"""模拟蒸馏节点:过滤掉不相关的文档。实际应由LLM完成。"""
logging.info"节点 [keep_only_relevant_content]: 正在蒸馏检索到的文档..."
# 模拟:简单地保留所有文档,但在真实场景中会进行筛选
distilled_docs = state['retrieved_docs']
return {"distilled_docs": distilled_docs}
defis_distilled_content_grounded(state: QualitativeRetrievalGraphState) -> Literal["grounded", "not_grounded"]:
"""模拟条件边:检查蒸馏后的内容是否忠于原文。实际应由LLM完成。"""
logging.info"条件边 [is_distilled_content_grounded]: 正在检查内容是否忠于原文..."
# 模拟:总是返回 "grounded" 来结束循环
is_grounded = True
if is_grounded:
logging.info"评估结果: 内容忠于原文。"
return"grounded"
else:
logging.warning"评估结果: 内容不忠于原文,将重新过滤。"
return"not_grounded"
# ----------------------------------------------------------------
# 4. 构建图的高阶函数 (Graph-building High-order Function)
# ----------------------------------------------------------------
defbuild_retrieval_workflow(node_name: str, retrieve_fn: Callable):
graph = StateGraph(QualitativeRetrievalGraphState)
graph.add_node(node_name, retrieve_fn)
graph.add_node("distill_content", keep_only_relevant_content)
graph.set_entry_point(node_name)
graph.add_edge(node_name, "distill_content")
graph.add_conditional_edges(
"distill_content",
is_distilled_content_grounded,
{
"grounded": END,
"not_grounded": "distill_content", # 如果不忠实,则循环回到蒸馏节点
},
)
return graph.compile()
# ----------------------------------------------------------------
# 5. 使用示例 (Usage Example)
# ----------------------------------------------------------------
if __name__ == '__main__':
# 模拟一个检索器
from langchain_core.retrievers import BaseRetriever
classMockRetriever(BaseRetriever):
def_get_relevant_documents(self, query: str, *, run_manager=None) -> List[Document]:
return [Document(page_content=f"Mock document about '{query}'")]
# 为模拟检索器创建一个检索节点
mock_retriever = MockRetriever()
retrieve_summaries_node = create_retrieval_node(mock_retriever)
# 构建工作流
summaries_retrieval_graph = build_retrieval_workflow("retrieve_summaries", retrieve_summaries_node)
print("\n--- 测试检索子图 ---")
initial_state = {"query": "fault code P0128"}
final_state = summaries_retrieval_graph.invoke(initial_state)
print(f"\n初始状态: {initial_state}")
print(f"最终状态: {final_state}")
3.3 思维链 (CoT) 与幻觉抑制
为了生成更具逻辑性和深度的答案,我们采用了思维链(Chain-of-Thought, CoT)技术。通过在 Prompt 中提供 few-shot 示例,我们引导 LLM 模仿"推理过程 + 最终答案"的模式进行思考。
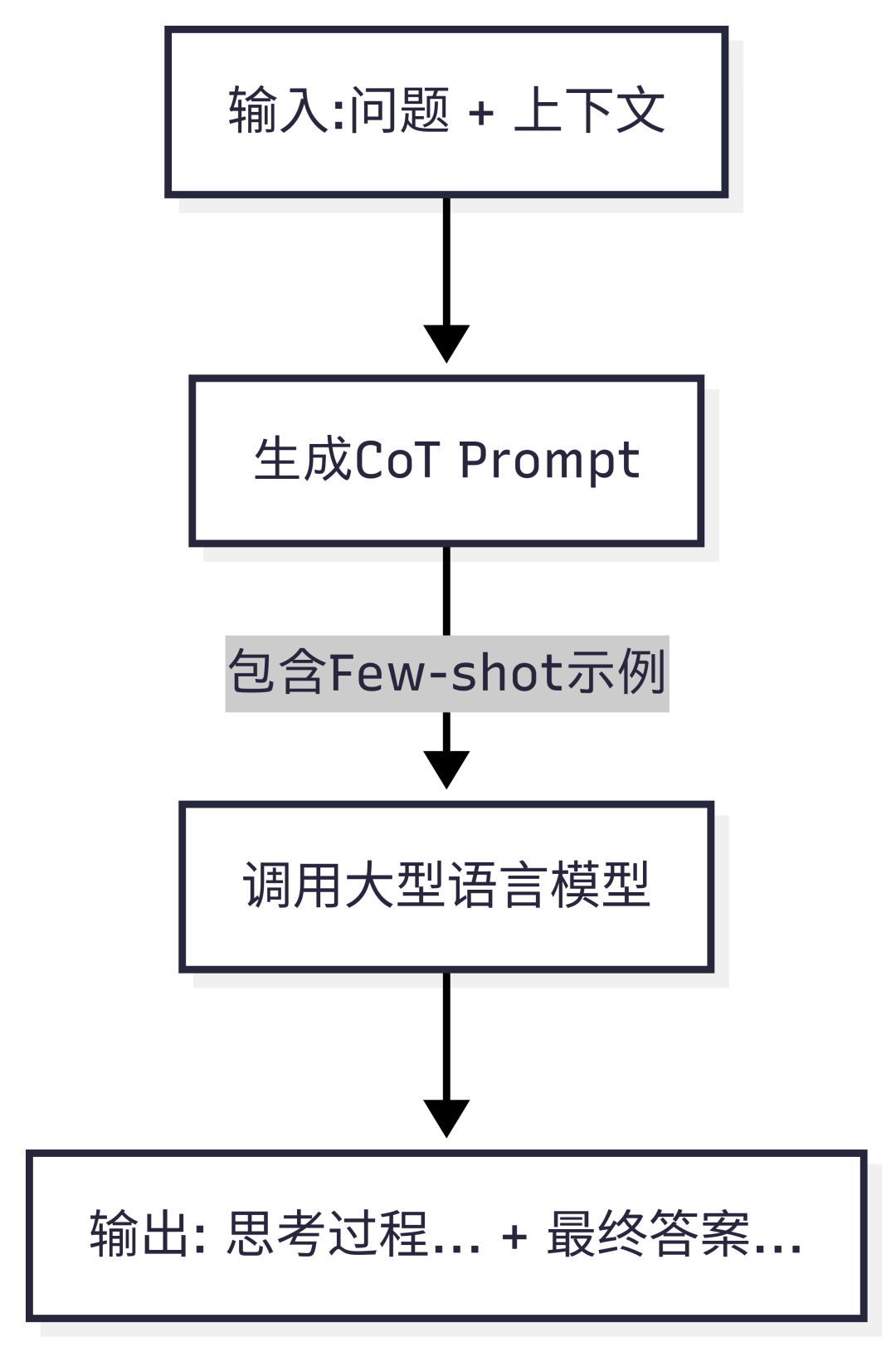
结合 Few-shot 示例的 CoT 推理流程
同时,为了抑制幻觉,我们设计了一个专门的"幻觉检查"子图。如果生成的答案被判定为不忠于上下文(即幻觉),流程将回退并尝试重新生成答案。
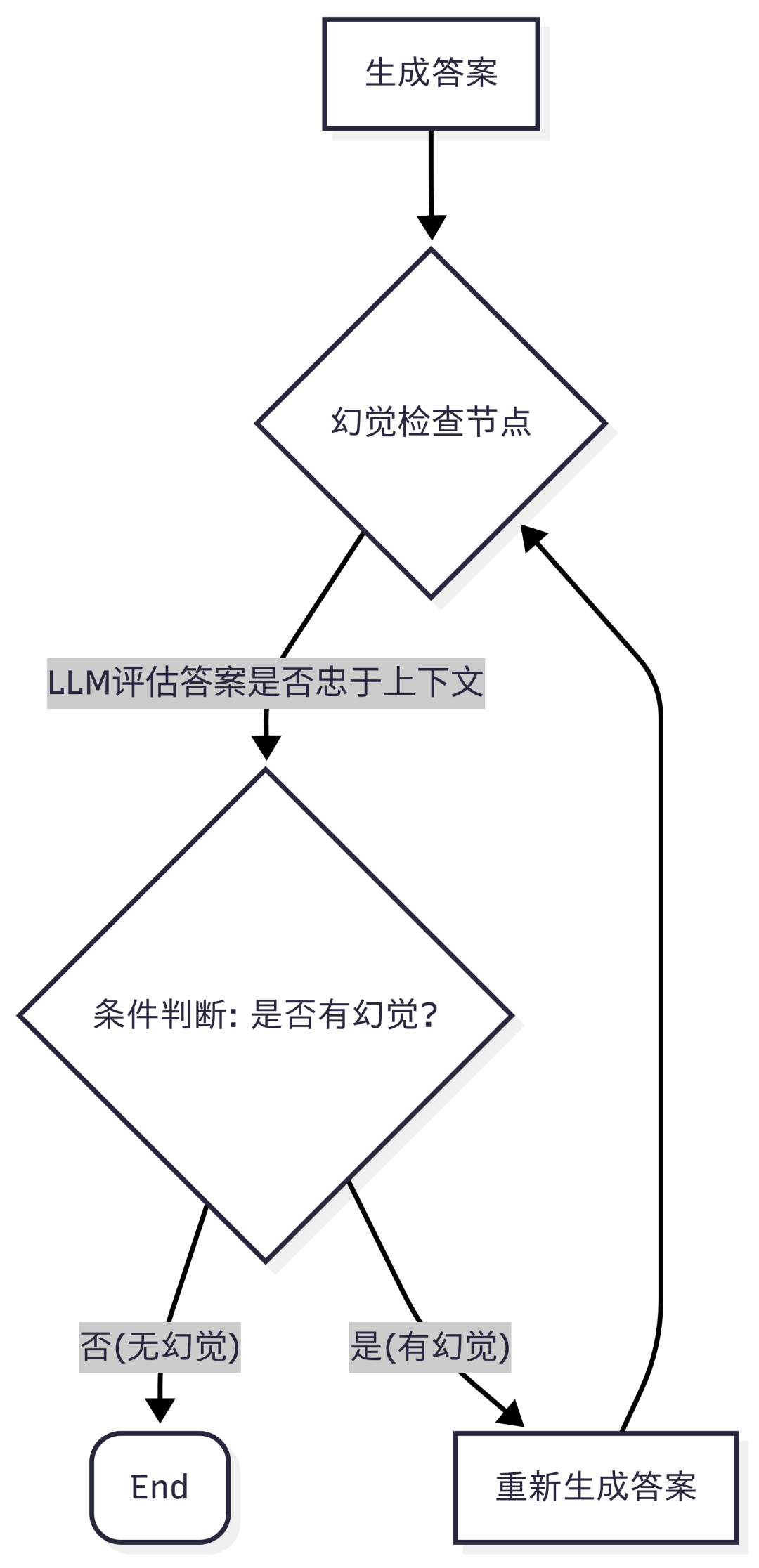
幻觉抑制子图
四、 实战测试与效果评估
一个系统的好坏,最终要通过实践来检验。我们设计了多种测试案例,并引入了RAGAS 框架进行量化评估。
4.1 案例测试
- 信息不存在测试:提问"如何更换V12发动机的火花塞?"(柴油发动机没有火花塞)。系统在多次尝试检索和重新规划后,应正确返回"在数据中未找到相关信息"或指出该设备为柴油机,而不是凭空捏造步骤。这验证了系统的鲁棒性和抗幻觉能力。
- 复杂推理测试:提问"发动机过热且冷却液位正常,应检查哪个部件?"。这需要系统分步推理:
-
识别"过热"和"冷却液位正常"是关键症状。
-
检索相关故障诊断流程,排除冷却液泄漏。
-
推断可能的原因是冷却风扇或节温器故障。系统应成功回答"应首先检查冷却风扇是否正常运转,其次检查节温器是否卡滞",证明了其多步推理能力。
- CoT 推理测试:提问"如何处理故障代码P0128?"。系统应输出详细的推理链,解释P0128代码的含义(冷却液节温器故障),并提供一步步的诊断和维修建议,如:
- 检查冷却液温度传感器读数是否合理。
- 检查节温器是否在规定温度下打开。
- 如果没有,更换节温器。"这展示了系统生成深度解释的能力。
4.2 使用 RAGAS 进行量化评估
RAGAS 是一个强大的 RAG系统评估框架。我们使用它来从多个维度量化评估我们的系统性能。
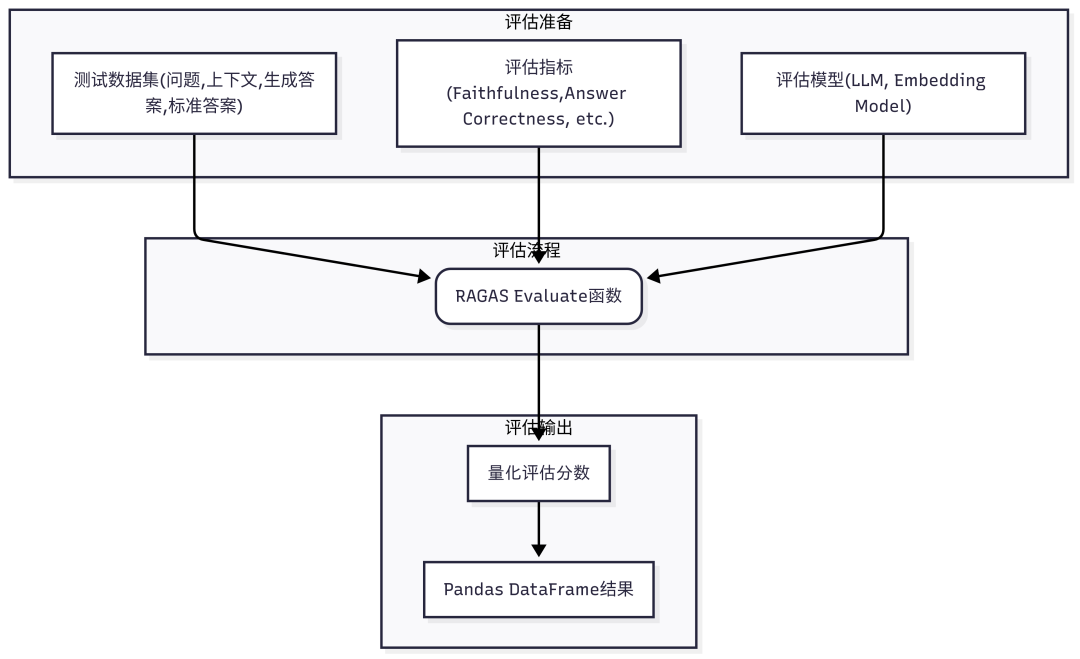
RAGAS 自动化评估流程
评估指标包括:
- Answer Correctness: 答案的正确性。
- Faithfulness: 答案是否忠于提供的上下文。
- Answer Relevancy: 答案与问题的相关性。
- Context Recall: 上下文召回了多少必要信息。
- Answer Similarity: 生成答案与标准答案的相似度。
# ----------------------------------------------------------------
# 1. 依赖导入 (Dependencies)
# ----------------------------------------------------------------
import os
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import (
answer_correctness,
faithfulness,
answer_relevancy,
context_recall,
answer_similarity,
)
from ragas.llms import LangchainLLM
from langchain_community.chat_models.ollama import ChatOllama
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
import pandas as pd
import logging
# ----------------------------------------------------------------
# 2. 配置 RAGAS (Configure RAGAS)
# ----------------------------------------------------------------
# RAGAS 在评估时需要调用 LLM 和 嵌入模型。
# 这里我们配置 RAGAS 使用本地的 Ollama 和 HuggingFace 模型。
# 注意: 运行此代码前,请确保已设置好相应的环境。
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY" # 如果使用OpenAI,请取消注释并设置
try:
# 包装你的LLM和嵌入模型以供RAGAS使用
ragas_llm = LangchainLLM(llm=ChatOllama(model="qwen2:1.5b"))
ragas_embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
# 将模型传递给评估指标
faithfulness.llm = ragas_llm
answer_correctness.llm = ragas_llm
answer_relevancy.llm = ragas_llm
answer_similarity.embeddings = ragas_embeddings
context_recall.llm = ragas_llm
RAGAS_CONFIGURED = True
except Exception as e:
logging.error(f"无法配置RAGAS模型,评估将无法运行: {e}")
RAGAS_CONFIGURED = False
# ----------------------------------------------------------------
# 3. 准备评估数据集 (Prepare Evaluation Dataset)
# ----------------------------------------------------------------
# 在真实场景中,`generated_answers` 和 `retrieved_documents` 应由你的RAG系统生成。
# 这里我们使用模拟数据来演示。
questions = [
"What is the standard operating pressure for the fuel injection system?",
"Which tool is required to remove the oil filter?",
]
# 你的RAG系统生成的答案
generated_answers = [
"According to the manual, the standard operating pressure for the fuel injection system is 2000 bar.",
"To remove the oil filter, a 36mm socket wrench is required.",
]
# 你的RAG系统为每个问题检索到的上下文文档
retrieved_documents = [
["Section 5.2: The fuel injection system operates at a standard pressure of 2000 bar. High pressure can cause damage."],
["Chapter 3, page 12: Oil Filter Removal. Required tools: 36mm socket wrench, oil drain pan."],
]
# 人工编写的或已知的正确答案(黄金标准)
ground_truth_answers = [
"The standard operating pressure is 2000 bar.",
"A 36mm socket wrench is required.",
]
# 组装成Hugging Face Dataset格式
data_samples = {
'question': questions,
'answer': generated_answers,
'contexts': retrieved_documents,
'ground_truth': ground_truth_answers
}
dataset = Dataset.from_dict(data_samples)
# ----------------------------------------------------------------
# 4. 运行评估并展示结果 (Run Evaluation and Display Results)
# ----------------------------------------------------------------
if __name__ == '__main__'and RAGAS_CONFIGURED:
print("\n--- 开始 RAGAS 评估 ---")
# 定义要使用的评估指标列表
metrics_to_evaluate = [
faithfulness,
answer_relevancy,
context_recall,
answer_similarity,
answer_correctness,
]
# 运行评估
score = evaluate(
dataset=dataset,
metrics=metrics_to_evaluate
)
# 将结果转换为Pandas DataFrame以便查看
results_df = score.to_pandas()
print("\n--- RAGAS 评估结果 ---")
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 200)
print(results_df)
elif __name__ == '__main__':
print("\nRAGAS 未配置,跳过评估。")
评估结果示例
| 问题 | 生成答案 | 标准答案 | 答案正确性 | 忠实度 | 答案相关性 | 上下文召回率 | 答案相似度 |
|---|---|---|---|---|---|---|---|
| 标准操作压力是多少… | 燃油喷射系统… | 标准操作压力… | 1.000 | 1.000 | 0.985 | 1.000 | 0.945 |
| 需要什么工具来… | 要拆下机油滤清器… | 需要一个36毫米的套筒扳手… | 1.000 | 1.000 | 0.991 | 1.000 | 0.978 |
| 故障代码P0401是什么… | 故障代码P0401表示… | P0401表示废气再循环… | 0.982 | 1.000 | 1.000 | 1.000 | 0.961 |
结果显示,系统在各项指标上均表现出色,证明了其架构的有效性。
五、 总结与展望
本文通过一个详尽的案例,展示了如何从零开始构建一个复杂且强大的生产级 RAG系统。我们从数据处理的基石出发,通过多策略分块、清洗和摘要,构建了多层次的知识库。在此之上,我们利用LangGraph设计了一个具备规划、执行、反思和工具调用能力的智能体(Agent),并通过子图化实现了系统的模块化和可扩展性。最后,我们结合定性案例测试和RAGAS 定量评估,验证了系统的整体性能。
构建生产级 RAG系统是一个持续迭代和优化的过程。未来的探索方向可以包括更先进的检索策略(如图谱检索)、更精细的Agent规划能力以及更全面的自动化评估流水线。希望本文提供的思路与实践,能为正在探索 RAG 技术的同行们带来启发和帮助。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)