从Prompt到Context Engineering,构建强大AI Agent系统
文章探讨了Prompt Engineering与Context Engineering的区别与联系,指出Context Engineering是更高阶的系统设计学科,关注动态构建和管理上下文。RAG作为Context Engineering的基础架构,通过检索外部数据增强模型能力。文章详细分析了Context Stack、向量数据库选型、上下文管理策略及多智能体系统中的数据流编排,展示了如何从战术
文章探讨了Prompt Engineering与Context Engineering的区别与联系,指出Context Engineering是更高阶的系统设计学科,关注动态构建和管理上下文。RAG作为Context Engineering的基础架构,通过检索外部数据增强模型能力。文章详细分析了Context Stack、向量数据库选型、上下文管理策略及多智能体系统中的数据流编排,展示了如何从战术性指令构建转向战略性架构设计,以构建可靠、可扩展的AI Agent系统。
背景
在观察去年以来对于“Prompt Engineering”的解构时,我们可以观察到一个微妙但重要的分歧。
一方面,专注于构建可扩展系统的前沿实践者们(如 Andrej Karpathy 等),积极倡导用 “Context Engineering” 来描述工作,认为 “Prompt Engineering” 这个词不足以涵盖复杂性,认为它只是 “Coming up with a laughably pretentious name for typing in the chat box(给在聊天框里打字起的一个可笑的自命不凡的名字)” 。因为他们构建 Agent 系统的核心挑战并非仅仅是 Prompt,而是设计整个数据流以动态生成最终提示的架构。
另一方面,近年来学术和正式文献倾向用 “Prompt Engineering” 作为一个广义的 umbrella term(伞形术语),其定义包括了 “Supporting content” 或 “Context”,把所有在不改变模型权重的前提下操纵模型输入的技术归为同一类型。
术语上的分歧可以反映该领域的成熟过程:随着 AI 应用从简单的单次交互发展到复杂的、有状态的智能体系统,优化静态指令已经无法满足需求。因此,“Context Engineering” 的出现,是为了区分两种不同层次的活动:一是编写指令的 skill,二是构建自动化系统以为该指令提供成功所需信息的科学。
(本文明确,尽管在学术上 Prompt Engineering 可能涵盖上下文,但在工程实践中,Context Engineering 是专注于如何动态构建和管理上下文的专门学科)
重新定义 Agent 数据流:Context is All You Need
本部分旨在建立 Prompt Engineering 与 Context Engineering 的基础概念,清晰地界定二者之间的区别与联系。
从前者到后者的转变,代表了人工智能应用开发领域一次关键的演进——从业界最初关注的战术性指令构建,转向由可扩展、高可靠性系统需求驱动的战略性架构设计。
Prompt Engineering - the Art of Instructions
Prompt Engineering 是与大型语言模型(LLM)交互的基础,其核心在于精心设计输入内容,以引导模型生成期望的输出。这一实践为理解 Context Engineering 的必要性提供了基准。
定义
一个提示(Prompt)远不止一个简单的问题,它是一个结构化的输入,可包含多个组成部分 。这些组件共同构成了与模型沟通的完整指令:
- 指令(Instructions):对模型的核心任务指令,明确告知模型需要执行什么操作 。
- 主要内容/输入数据(Primary Content/Input Data):模型需要处理的文本或数据,是分析、转换或生成任务的对象 。
- 示例(Examples/Shots):演示期望的输入-输出行为,为模型提供“上下文学习”(In-Context Learning)的基础 。
- 线索/输出指示器(Cues/Output Indicators):启动模型输出的引导性词语,或对输出格式(如JSON、Markdown)的明确要求 。
- 支持性内容(Supporting Content/Context):为模型提供的额外背景信息,帮助其更好地理解任务情境。正是这一组件,构成了 Context Engineering 发展的概念萌芽。
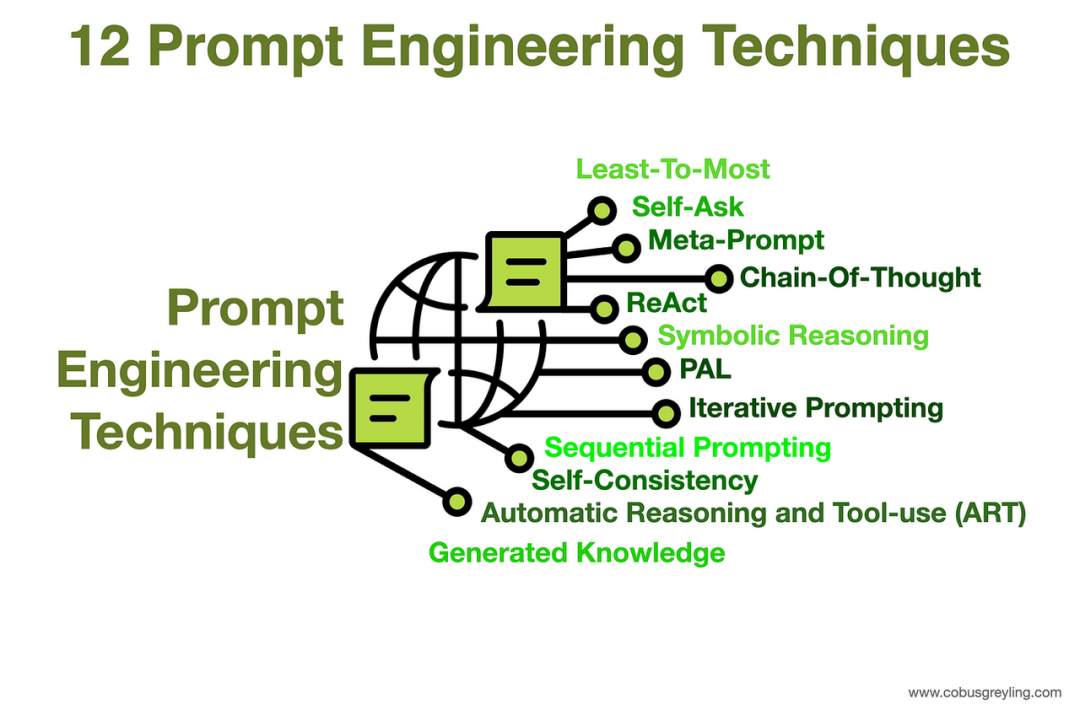
Prompt Engineering 的核心技术
Prompt Engineer 使用一系列技术来优化模型输出,这些技术可按复杂性进行分类:
- 零样本提示(Zero-Shot Prompting): 在不提供任何示例的情况下直接向模型下达任务,完全依赖其在预训练阶段获得的知识和推理能力。
- 少样本提示(Few-Shot Prompting): 在提示中提供少量(通常为 1 到 5 个)高质量的示例,以引导模型的行为。对于复杂任务,这种“上下文学习”方法被证明极为有效。
- 思维链提示(Chain-of-Thought Prompting, CoT): 引导模型将复杂问题分解为一系列中间推理步骤,显著增强了其在逻辑、数学和推理任务上的表现。
- 高级推理技术: 在 CoT 的基础上,研究人员还开发了更为复杂的变体,如思维树(Tree-of-Thought)、苏格拉底式提示(Maieutic Prompting)和由简到繁提示(Least-to-Most Prompting),以探索更多样化的解决方案路径。
以提示为中心的方法的局限性
尽管 Prompt Engineering 至关重要,但对于构建稳健、可用于生产环境的系统而言,它存在固有的局限性:
- 脆弱性&不可复现性: 提示中微小的措辞变化可能导致输出结果的巨大差异,使得这一过程更像是一种依赖反复试错的“艺术”,而非可复现的“科学”。
- 扩展性差: 手动、迭代地优化提示的过程,在面对大量用户、多样化用例和不断出现的边缘情况时,难以有效扩展。
- 用户负担: 这种方法将精心构建一套详尽指令的负担完全压在了用户身上,对于需要自主运行、或处理高并发请求的系统而言是不切实际的。
- 无状态性: Prompt Engineering 本质上是为单轮、“一次性”的交互而设计的,难以处理需要记忆和状态管理的长对话或多步骤任务。
Context Engineering 兴起:范式的转移
Context Engineering 并非要取代 Prompt Engineering,而是一个更高阶、更侧重于系统设计的必要学科。
定义 Context Engineering
Context Engineering 是一门设计、构建并优化动态自动化系统的学科,旨在为大型语言模型在正确的时间、以正确的格式,提供正确的信息和工具,从而可靠、可扩展地完成复杂任务。
prompt 告诉模型如何思考,而 Context 则赋予模型完成工作所需的知识和工具。
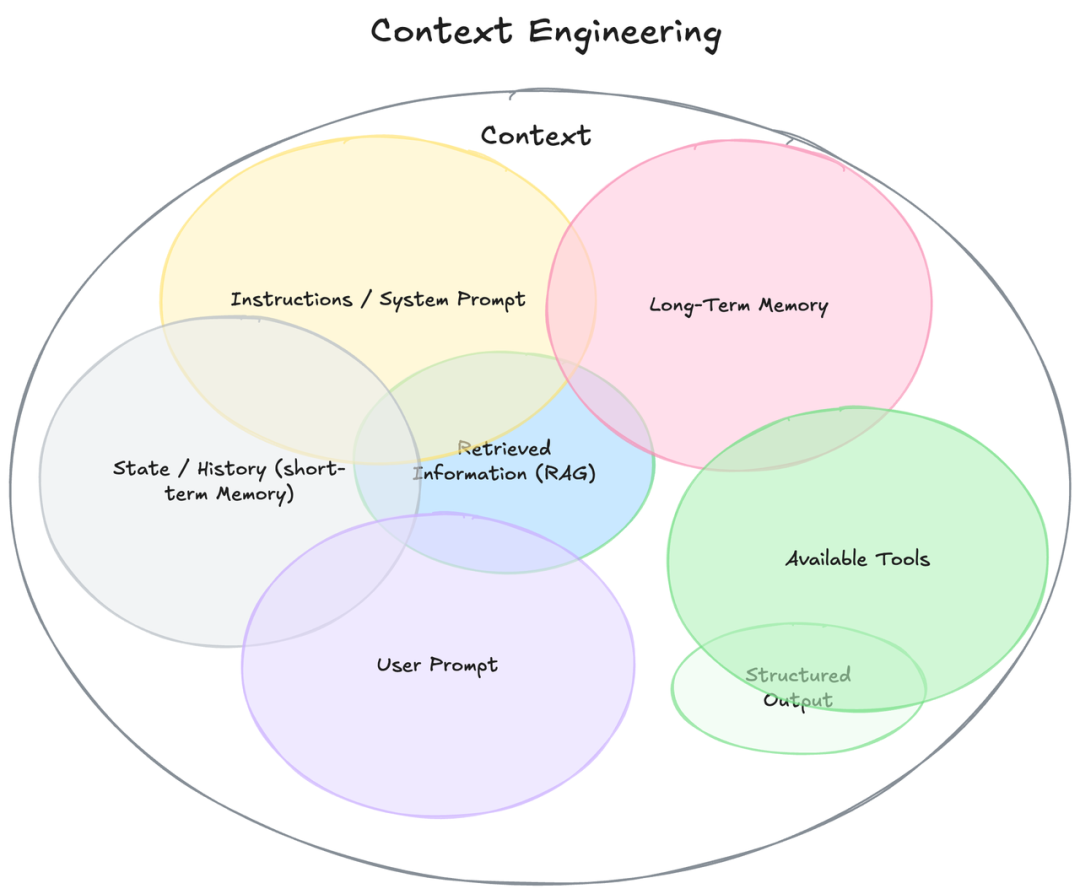
“Context”的范畴
“Context”的定义已远超用户单次的即时提示,它涵盖了 LLM 在做出响应前所能看到的所有信息生态系统:
- 系统级指令和角色设定。
- 对话历史(短期记忆)。
- 持久化的用户偏好和事实(长期记忆)。
- 动态检索的外部数据(例如来自RAG)。
- 可用的工具(API、函数)及其定义。
- 期望的输出格式(例如,JSON Schema)。
对比分析
关系:超集,而非对抗、竞争
Prompt Engineering 是 Context Engineering 的一个子集。
- Context Engineering 决定用什么内容填充 Context Window,
- Prompt Engineering 则负责优化窗口内的具体指令。
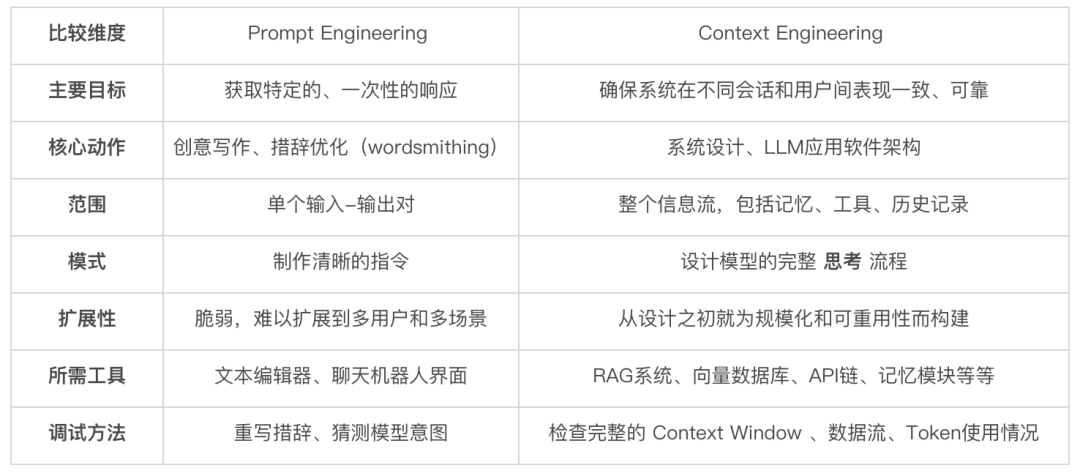
Prompt Engineering vs. Context Engineering
Context Engineering 的基石:RAG
本部分将阐述检索增强生成(RAG)作为实现 Context Engineering 的主要架构模式。从“是什么”转向“如何做”,详细介绍RAG系统的组件和演进。
Retrieval-Augmented Generation
为何 RAG 不仅是一种技术,更是现代 Context Engineering 系统的基础架构?
解决 LLM 的核心弱点
RAG 直接解决了标准 LLM 在企业应用中存在的固有局限性:
- 知识冻结:LLM 的知识被冻结在其训练数据的时间点。RAG 通过在推理时注入实时的、最新的信息来解决这个问题。
- 缺乏领域专有知识:标准 LLM 无法访问组织的内部私有数据。RAG 则能够将 LLM 连接到这些内部知识库,如技术手册、政策文件等。
- 幻觉(Hallucination):LLM 会不同程度上地编造事实。RAG 通过将模型的回答“锚定”在可验证的、检索到的证据上,提高事实的准确性和可信度。
RAG 工作流
RAG 的实现通常分为两个主要阶段:
- 索引(离线阶段):在这个阶段,系统会处理外部知识源。文档被加载、分割成更小的 chunks,然后通过 Embedding Model 转换为向量表示,并最终存储在专门的向量数据库中以备检索。
- 推理(在线阶段):当用户提出请求时,系统执行以下步骤:
- 检索(Retrieve):将用户的查询同样转换为向量,然后在向量数据库中进行相似性搜索,找出与查询最相关的文档块。
- 增强(Augment):将检索到的这些文档块与原始的用户查询、系统指令等结合起来,构建一个内容丰富的、增强的最终提示。
- 生成(Generate):将这个增强后的提示输入给 LLM,LLM 会基于提供的上下文生成一个有理有据的回答。
RAG 架构分类
- Naive RAG:即上文描述的基础实现。它适用于简单的问答场景,但在检索质量和上下文处理方面存在局限。
- Advanced RAG:这种范式在检索前后引入了处理步骤以提升质量。许多第三部分将详述的技术都属于这一范畴。关键策略包括:
- 检索前处理:采用更复杂的文本分块策略、查询转换(如 StepBack-prompting)等优化检索输入。
- 检索后处理:对检索到的文档进行 Re-ranking 以提升相关性,并对上下文进行 Compression。
- Modular RAG:一种更灵活、更面向系统的 RAG 视图,其中不同的组件(如搜索、检索、记忆、路由)被视为可互换的模块。这使得构建更复杂、更定制化的流程成为可能。具体模式包括:
-
带记忆的 RAG:融合对话历史,以处理多轮交互,使对话更具连续性。
-
分支/路由 RAG:引入一个路由模块,根据查询的意图决定使用哪个数据源或检索器。
-
Corrective RAG, CRAG:增加了一个自我反思步骤。一个轻量级的评估器会对检索到的文档质量进行打分。如果文档不相关,系统会触发替代的检索策略(如网络搜索)来增强或替换初始结果。
-
Self-RAG:让 LLM 自身学习判断何时需要检索以及检索什么内容,通过生成特殊的检索 Token 来自主触发检索。
-
Agentic RAG:这是 RAG 最先进的形式,将 RAG 集成到一个智能体循环(agentic loop)中。模型能够执行多步骤任务,主动与多个数据源和工具交互,并随时间推移综合信息。这是 Context Engineering 在实践中的顶峰。
向量数据库的角色
本节将分析支撑 RAG 中“检索”步骤的关键基础设施,并比较市场上的主流解决方案。
Context Stack:一个新兴的 abstract layer
观察 RAG 系统的构成—— 数据摄入、分块、嵌入、用于索引和检索的向量数据库、重排序器、压缩器以及最终的 LLM ——可以发现,这些组件并非随意组合,而是形成了一个连贯的、多层次的架构。这可以被抽象地称为 Context Stack。
这个堆栈的数据流非常清晰:在离线索引阶段,数据从原始文档流向分块、嵌入,最终存入向量数据库 。在在线推理阶段,数据流从用户查询开始,经过嵌入、向量搜索、重排序、压缩,最终形成送入 LLM 的提示。
这个堆栈的出现,标志着 AI 应用开发正在走向成熟,不同的技术供应商开始专注于 Stack 中的特定层面:Pinecone、Weaviate 和 Milvus 等公司在做 Database layer;LangChain 和 LlamaIndex 等框架提供了将所有组件粘合在一起的 Application Orchestration Layer;而 Cohere 和 Jina AI 等提供了专业的 Re-ranking as a Service(RaaS)模块。
因此,理解新的 AI Agent 架构,就意味着理解 Context Engineering,就意味着要理解这个新兴的 Context Stack,了解其各个层次以及在每个层次上不同组件之间的权衡。这种视角将讨论从一系列孤立的技术提升到系统设计和技术选型的高度,对工程师和架构师而言具有更高的价值。
选型关键考量因素
组织在选择向量数据库时必须考虑以下主要因素:
- 模型:选择完全托管的云服务(如 Pinecone),还是可自托管的开源方案(如 Milvus、Weaviate)。
- 扩展性:是否能处理数十亿级别的向量数据和高查询负载(Milvus)。
- 功能集: 是否支持混合搜索(关键词+向量)、高级 meta 过滤以及多模态数据处理(Weaviate)。
- 易用性与灵活性:是倾向于API简单、设置最少的方案(Pinecone),还是需要多种索引算法和深度配置选项的方案(Milvus) 。
为了给技术选型提供一个实用的决策框架,下表对几个主流的向量数据库进行了比较。
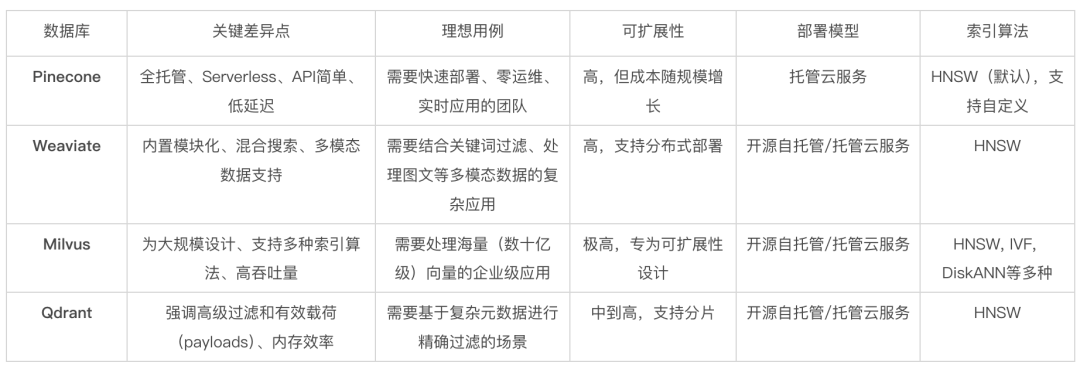
主流 RAG 向量数据库对比分析
Context 工程化的核心概念和目标
从原始数据到相关分块
本节聚焦于从知识库中识别和检索最有价值信息的初始阶段。
高级分块策略
文本分块(Chunking)是 RAG 流程中最关键也最容易被忽视的一步。其目标是创建在语义上自成一体的文本块。
- 朴素分块的问题:固定大小的分块方法虽然简单,但常常会粗暴地切断句子或段落,导致上下文支离破碎,语义不完整。
- 内容感知分块:
- 递归字符分割:一种更智能的方法,它会按照一个预设的分割符层次结构(如:先按段落,再按句子,最后按单词)进行分割,以尽可能保持文本的自然结构。
- 文档特定分块:利用文档自身的结构进行分割,例如,根据 Markdown 的标题、代码文件的函数或法律合同的条款来划分。
- 语言学分块:使用 NLTK、spaCy 等自然语言处理库,基于句子、名词短语或动词短语等语法边界进行分割。
- 语义分块: 这是最先进的方法之一。它使用嵌入模型来检测文本中语义的转变点。当文本的主题或意义发生变化时,就在该处进行分割,从而确保每个分块在主题上是高度内聚的。研究表明,这种策略的性能优于其他方法。
- 智能体分块:一个前沿概念,即利用一个 LLM 智能体来决定如何对文本进行分块,例如,通过将文本分解为一系列独立的 propositions 来实现。
通过重排序提升精度
为了平衡检索的速度和准确性,业界普遍采用两阶段检索流程。
- 两阶段流程:
-
第一阶段(召回): 使用一个快速、高效的检索器(如基于 bi-encoder 的向量搜索或 BM25 等词法搜索)进行广泛撒网,召回一个较大的候选文档集(例如,前 100 个)。
-
第二阶段(精排/重排序): 使用一个更强大但计算成本更高的模型,对这个较小的候选集进行重新评估,以识别出最相关的少数几个文档(例如,前 5 个)。
- Cross-Encoder: 交叉编码器之所以在重排序阶段表现优越,是因为它与双编码器的工作方式不同。双编码器独立地为查询和文档生成嵌入向量,然后计算它们的相似度。而交叉编码器则是将查询和文档同时作为输入,让模型在内部通过 Attention Mechanism 对二者进行深度交互。这使得模型能够捕捉到更细微的语义关系,从而给出更准确的相关性评分。
- 实际影响: 重排序显著提高了最终送入 LLM 的上下文质量,从而产出更准确、幻觉更少的答案。在金融、法律等高风险领域,重排序被认为是必不可少而非可选的步骤。
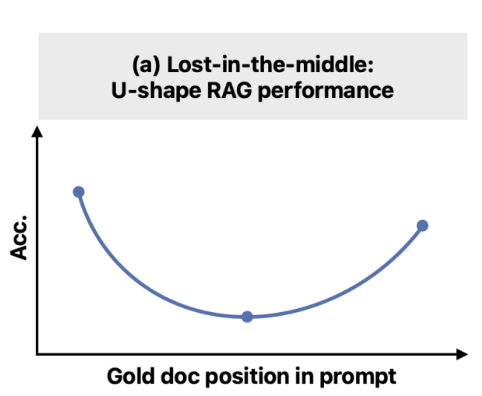
核心问题 - Lost in the Middle
https://arxiv.org/abs/2307.03172 Lost in the Middle: How Language Models Use Long Contexts
当前 LLM 存在一个根本性认知局限,这一局限使得简单的上下文堆砌变得无效,并催生了后续的优化技术。
- 定义:LLM 在处理长上下文时表现出一种独特的 U 型 性能曲线。当关键信息位于上下文窗口的开头(首因效应)或结尾(近因效应)时,模型能够高效地利用这些信息。然而,当关键信息被 “hidden”在长篇上下文的中间位置时,模型的性能会显著下降。
- 实验: 在多文档问答任务时,即使检索器召回了更多相关的文档,模型的性能提升也很快达到饱和。这意味着简单地增加上下文长度(即添加更多文档)不仅无益,甚至因为关键信息被淹没而损害性能 。
- “知道但说不出来”: 并非模型“找不到”信息。通过探测模型的内部表征发现,模型通常能够准确地编码关键信息的位置,但在生成最终答案时却未能有效利用这些信息。这表明在模型内部,信息检索和信息利用(或沟通)之间存在脱节。
上下文丰富性与窗口局限性之间的考量
Context Engineering 的核心存在一个根本性的矛盾。一方面,提供丰富、全面的上下文是获得高质量响应的关键。另一方面,LLM 的上下文窗口是有限的,并且由于 Lost in the Middle、contextual distraction 等问题,过长的上下文反而会导致性能下降。
一个朴素的想法是尽可能多地将相关信息塞进上下文窗口。然而,研究和实践都证明这是适得其反的。LLM 会被无关信息淹没、分心,或者干脆忽略那些不在窗口两端的信息。
这就产生了一个核心的优化问题:如何在固定的 Token 预算内,最大化“信号”(真正相关的信息),同时最小化“噪声”(不相关或分散注意力的信息),并充分考虑到模型存在的认知偏差?
这个考量是 Context Engineering 领域创新的主要驱动力。所有的高级技术——无论是语义分块、重排序,还是后续将讨论的压缩、摘要和智能体隔离——都是为了有效管理这一权衡而设计的。因此,Context Engineering 不仅是关于提供上下文,更是关于如何策划和塑造上下文,使其对一个认知能力有限的处理单元(LLM)最为有效。
学习大模型 AI 如何助力提升市场竞争优势?
随着新技术的不断涌现,特别是在人工智能领域,大模型的应用正逐渐成为提高社会生产效率的关键因素。这些先进的技术工具不仅优化了工作流程,还极大地提升了工作效率。然而,对于个人而言,掌握这些新技术的时间差异将直接影响到他们的竞争优势。正如在计算机、互联网和移动互联网的早期阶段所展现的那样,那些最先掌握新技术的人往往能够在职场中占据先机。
掌握 AI 大模型技能,不仅能够提高个人工作效率,还能增强在求职市场上的竞争力。在当今快速发展的技术时代,大模型 AI 已成为推动市场竞争力的重要力量。个人和企业必须迅速适应这一变化,以便在市场中保持领先地位。
如何学习大模型 AI ?
在我超过十年的互联网企业工作经验中,我有幸指导了许多同行和后辈,并帮助他们实现个人成长和学习进步。我深刻认识到,分享经验和知识对于推动整个行业的发展至关重要。因此,尽管工作繁忙,我仍然致力于整理和分享各种有价值的AI大模型资料,包括AI大模型入门学习思维导图、精选学习书籍手册、视频教程以及实战学习等内容。通过这些免费的资源,我希望能够帮助更多的互联网行业朋友获取正确的学习资料,进而提升大家的技能和竞争力。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、初阶应用:建立AI基础认知
在第一阶段(10天),重点是对大模型 AI 的基本概念和功能进行深入了解。这将帮助您在相关讨论中发表高级、独特的见解,而不仅仅是跟随他人。您将学习如何调教 AI,以及如何将大模型与业务相结合。
主要学习内容:
- 大模型AI的功能与应用场景:探索AI在各个领域的实际应用
- AI智能的起源与进化:深入了解AI如何获得并提升其智能水平
- AI的核心原理与心法:掌握AI技术的核心概念和关键原理
- 大模型应用的业务与技术架构:学习如何将大模型AI应用于业务场景和技术架构中
- 代码实践:向GPT-3.5注入新知识的示例代码
- 提示工程的重要性与核心思想:理解提示工程在AI应用中的关键作用
- Prompt的构建与指令调优方法:学习如何构建有效的Prompt和进行指令调优
- 思维链与思维树的应用:掌握思维链和思维树在AI推理和决策中的作用
- Prompt攻击与防范策略:了解Prompt攻击的类型和如何进行有效的防范


、、、
二、中阶应用:深入AI实战开发
在第二阶段(30天),您将进入大模型 AI 的进阶实战学习。这将帮助您构建私有知识库,扩展 AI 的能力,并快速开发基于 agent 的对话机器人。适合 Python 和 JavaScript 程序员。
主要学习内容:
- RAG的重要性:理解RAG在AI应用中的关键作用
- 构建基础ChatPDF:动手搭建一个简单的ChatPDF应用
- 检索基础:掌握信息检索的基本概念和原理
- 理解向量表示:深入探讨Embeddings的原理和应用
- 向量数据库与检索技术:学习如何使用向量数据库进行高效检索
- 基于 vector 的 RAG 实现:掌握基于向量的RAG构建方法
- RAG系统的高级扩展:探索RAG系统的进阶知识和技巧
- 混合检索与RAG-Fusion:了解混合检索和RAG-Fusion的概念和应用
- 向量模型的本地部署策略:学习如何在本地环境中部署向量模型

三、高阶应用:模型训练
在这个阶段,你将掌握模型训练的核心技术,能够独立训练和优化大模型AI。你将了解模型训练的基本概念、技术和方法,并能够进行实际操作。
- 模型训练的意义:理解为什么需要进行模型训练。
- 模型训练的基本概念:学习模型训练的基本术语和概念。
- 求解器与损失函数:了解求解器和损失函数在模型训练中的作用。
- 神经网络训练实践:通过实验学习如何手写一个简单的神经网络并进行训练。
- 训练与微调:掌握训练、预训练、微调和轻量化微调的概念和应用。
- Transformer结构:了解Transformer的结构和原理。
- 轻量化微调:学习如何进行轻量化微调以优化模型性能。
- 实验数据集构建:掌握如何构建和准备实验数据集。

四、专家应用:AI商业应用与创业
在这个阶段,你将了解全球大模型的性能、吞吐量和成本等方面的知识,能够在云端和本地等多种环境下部署大模型。你将找到适合自己的项目或创业方向,成为一名被AI武装的产品经理。
- 硬件选型:学习如何选择合适的硬件来部署和运行大模型AI。
- 全球大模型概览:了解全球大模型的发展趋势和主要玩家。
- 国产大模型服务:探索国产大模型服务的优势和特点。
- OpenAI代理搭建:学习如何搭建OpenAI代理以扩展AI的功能和应用范围。
- 热身练习:在阿里云 PAI 上部署 Stable Diffusion
- 本地化部署:在个人计算机上运行大型模型
- 私有化部署策略:大型模型的内部部署方法
- 利用 vLLM 进行模型部署:高效部署大型模型的技术
- 案例分析:如何在阿里云上优雅地私有部署开源大型模型
- 开源 LLM 项目的全面部署:从零开始部署开源大型语言模型
- 内容安全与合规:确保AI应用的内容安全和合规性
- 算法备案流程:互联网信息服务算法的备案指南
通过这些学习内容,您不仅能够掌握大模型 AI 的基本技能,还能够深入理解其高级应用,从而在市场竞争中占据优势。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你无疑是AI领域的佼佼者。然而,即使你只能完成60-70%的内容,你也已经展现出了成为一名大模型AI大师的潜力。
最后,本文提供的完整版大模型 AI 学习资料已上传至 CSDN,您可以通过微信扫描下方的 CSDN 官方认证二维码免费领取【保证100%免费】。
优化上下文窗口:压缩与摘要
本节详细介绍用于主动管理上下文的技术,确保最有价值的信息被优先呈现。
上下文压缩的目标
缩短检索到的文档列表和/或精简单个文档的内容,只将最相关的信息传递给LLM。这能有效降低API调用成本、减少延迟,并缓解 Lost in the Middle 的问题 。
压缩方法
- 过滤式压缩: 这类方法决定是保留还是丢弃整个检索到的文档。
- LLMChainFilter:利用一个 LLM 对每个文档的相关性做出简单的“是/否”判断。
- EmbeddingsFilter:更经济快速的方法,根据文档嵌入与查询嵌入的余弦相似度来过滤文档。
- 内容提取式压缩:这类方法会直接修改文档内容。
- LLMChainExtractor:遍历每个文档,并使用 LLM 从中提取仅与查询相关的句子或陈述 。
- 用 top N 代替压缩:像 LLMListwiseRerank 这样的技术,使用 LLM 对检索到的文档进行重排序,并只返回排名最高的 N 个,从而起到高质量过滤器的作用。
作为压缩策略的摘要
对于非常长的文档或冗长的对话历史,可以利用 LLM 生成摘要。这些摘要随后被注入上下文,既保留了关键信息,又大幅减少了 Token 数量。这是在长时程运行的智能体中管理上下文的关键技术。
智能体系统的上下文管理
从 HITL 到 SITL
Prompt Engineering 本质上是一个手动的、Human-in-the-Loop 的试错过程。而 Context Engineering,尤其是在其智能体形式中,则是关于构建一个自动化的 System-in-the-Loop,这个系统在LLM看到提示之前就为其准备好上下文。
一个人类提示工程师需要手动收集信息、组织语言并进行测试。而一个 Context Engineering 化的系统则将此过程自动化:RAG 流程本身就是一个自动收集信息的系统;路由器是一个自动决定收集哪些信息的系统;记忆模块是一个自动持久化和检索历史信息的系统。
正是这种自动化,使得 AI 系统能够变得“智能体化”(Agentic)——即能够在没有人类为每一步微观管理上下文的情况下,进行自主的、多步骤的推理 。因此,Context Engineering 的目标是构建一个可靠、可重复的上下文组装机器。这台机器取代了提示工程师的临时性、手工劳动,从而使创建真正自主和可扩展的 AI 智能体成为可能。焦点从单个提示的“技艺”转向了生成该提示的“系统工程”。
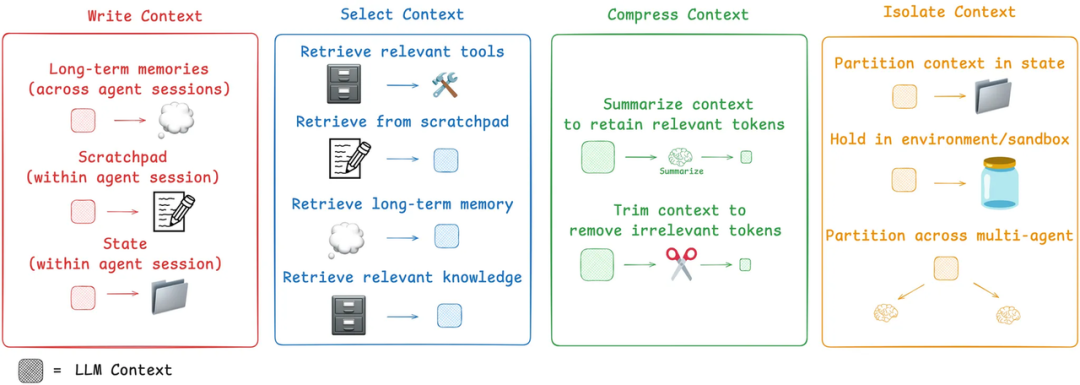
智能体上下文管理框架
LangChain 博客中提出的四个关键策略 :
- Write - 持久化上下文:
- Scratchpads:供智能体在执行复杂任务时使用的临时、会话内记忆,用于记录中间步骤。
- Memory:长期、持久化的存储,记录关键事实、用户偏好或对话摘要,可在不同会话间调用。
- Select - 检索上下文:根据当前的子任务,使用 RAG 技术动态地从记忆、工具库或知识库中选择相关上下文。这甚至包括对工具描述本身应用 RAG,以避免向智能体提供过多无关的工具选项。
- Compress - 优化上下文:利用摘要或修剪技术来管理智能体在长时程任务中不断增长的上下文,防止上下文窗口溢出和“ Lost in the Middle ”问题。
- Isolate - 分割上下文:
- 多智能体系统: 将一个复杂问题分解,并将子任务分配给专门的子智能体,每个子智能体都拥有自己独立的、更聚焦的上下文窗口。
- 沙盒环境: 在一个隔离的环境中执行工具调用,只将必要的执行结果返回给 LLM,从而将包含大量 Token 的复杂对象隔离在主上下文窗口之外。
多智能体架构中的 Context 数据流与工作流编排
LLM 正在从被动地响应用户查询的“响应者”,演变为能够自主规划、决策并执行多步骤复杂任务的“执行者”——即我们所说的“智能体”(AI Agent)。
当一个智能体不再是简单地“输入-输出”,而是需要调用工具、访问数据库、与用户进行多轮交互时,其内部的数据是如何流动和管理的?如何进行技术选型?
工作流(Workflow) vs. 智能体(Agent)
在深入技术细节之前,建立一个清晰的概念框架至关重要。业界(如 Anthropic)倾向于对“智能体系统”进行两种架构上的区分。
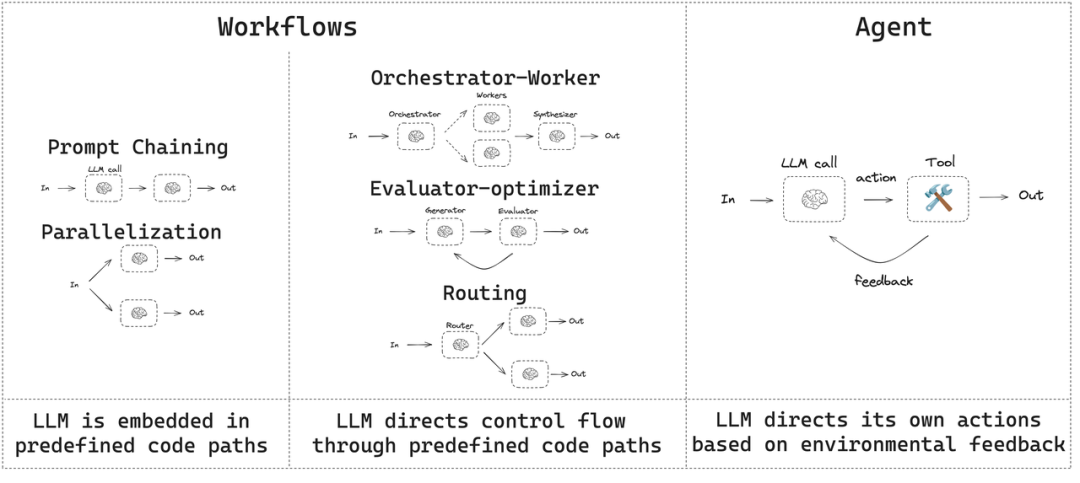
工作流(Workflows)
指的是 LLM 和工具通过预定义的代码路径进行编排的系统。在这种模式下,数据流动的路径是固定的、由开发者明确设计的,类似于上世纪流行的“专家系统”。例如,“第一步:分析用户邮件;第二步:根据分析结果在日历中查找空闲时段;第三步:起草会议邀请邮件”。这种模式确定性高,易于调试和控制,非常适合有明确业务流程的场景(如风控需求高、数据敏感、安全等级要求)。
智能体(Agents)
指的是 LLM 动态地指导自己的流程和工具使用,自主控制如何完成任务的系统。在这种模式下,数据流动的路径不是预先固定的,而是由LLM在每一步根据当前情况和目标动态决定的。这种模式灵活性高,能处理开放式问题,但可控性和可预测性较低。
复杂的智能体通常是这两种模式的混合体,在宏观层面遵循一个预定义的工作流,但在某些节点内部,又赋予 LLM 一定的自主决策权。管理这一切的核心,我们称之为编排层(Orchestration Layer)。
多 Agent 编排的核心架构:预定义数据流的实现
为了实现可靠、可控的数据流动,开发者们已经探索出几种成熟的架构模式。这些模式可以单独使用,也可以组合成更复杂的系统。
链式工作流(Prompt Chaining)(GPT-3.5 时期的工作原理)
- 数据流: 输入 -> 模块 A -> 输出 A -> 模块 B -> 输出 B ->… -> 最终输出
- 工作原理: 每个模块(LLM 调用)只负责一个定义明确的子任务。
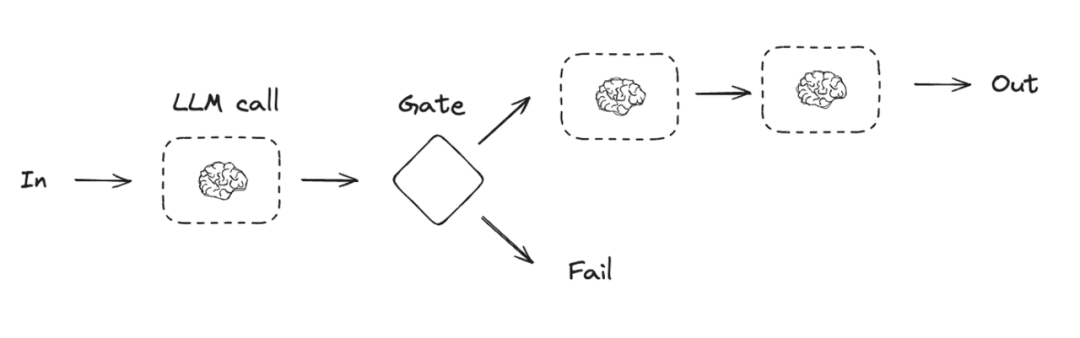
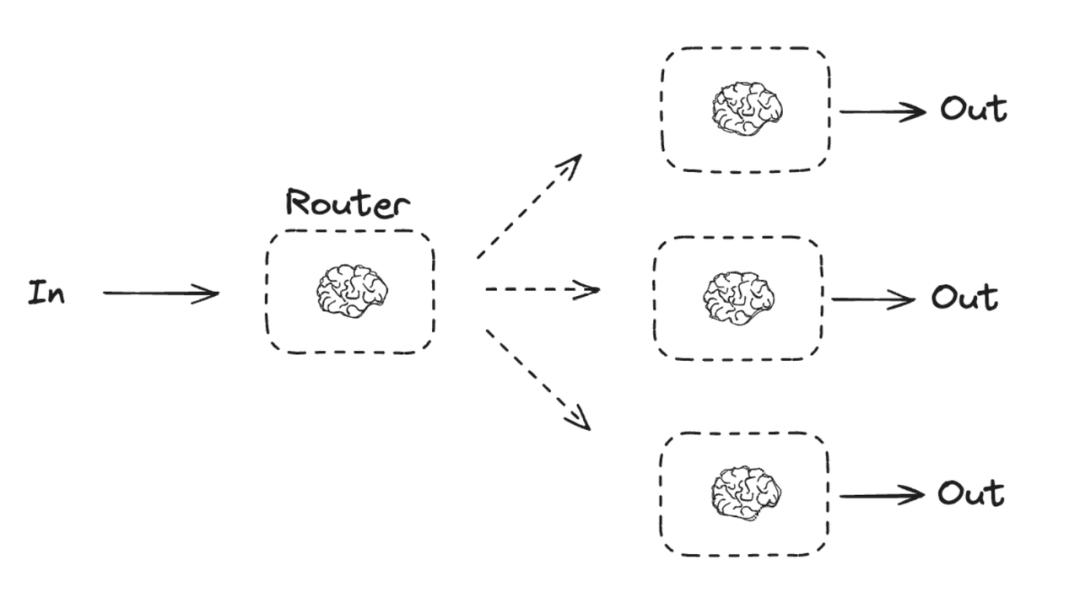
路由工作流(Routing)(o3 的早期工作原理)
- 数据流: 输入 -> 路由器选择 => -> 输出
- 工作原理: 一个充当“路由器”的 LLM 调用,其唯一任务就是决策。它会分析输入数据,然后输出一个指令,告诉编排系统接下来应该调用哪个具体的业务模块。
- 实现方式: LangGraph 使用 Conditional Edges 来实现这种逻辑,即一个节点的输出决定了图的下一跳走向何方。
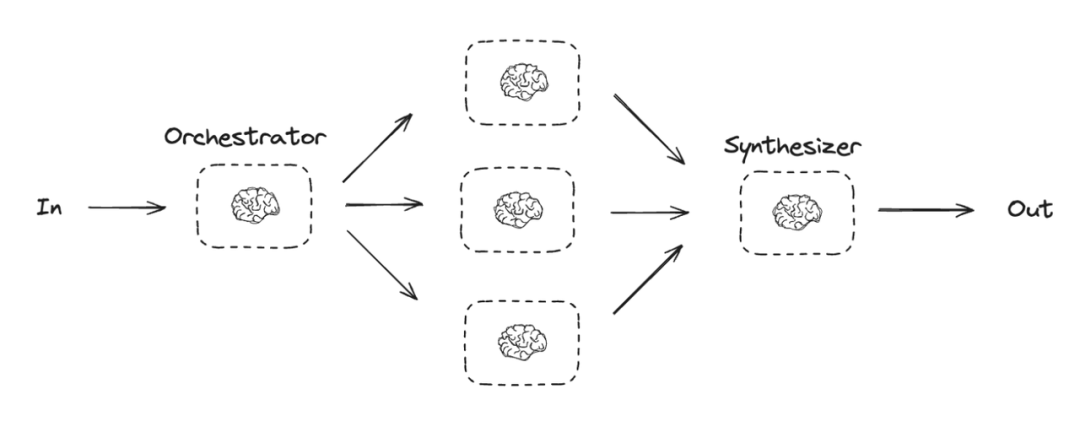
编排器-工作者模式(Orchestrator-Workers)
- 对于极其复杂的任务,可以采用多智能体(Multi-agent)架构,也称为 Orchestrator-Workers 模式。一个中心 Orchestrator 智能体负责分解任务,并将子任务分配给多个专职的 Workers 智能体。
- 数据流:这是一个分层、协作的流动模式。 总任务 -> Orchestrator => -> 结果汇总 -> 最终输出
- 工作原理:每个工作者智能体都有自己独立的上下文和专用工具,专注于解决特定领域的问题。
决策与数据选择机制
在上述架构中,智能体(或其模块)如何决定“需要什么数据”以及“下一步做什么”?这依赖于其内部的规划和推理能力。
ReAct 框架
ReAct(Reasoning and Acting)是一个基础且强大的框架,它通过模拟人类的“Reasoning-Acting”模式,使LLM能够动态地决定数据需求。
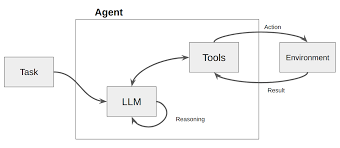
其核心是一个循环:
-
思考(Thought):LLM 首先进行内部推理。它分析当前任务和已有信息,判断是否缺少完成任务所需的知识,并制定下一步的行动计划。
例如:“用户问我今天旧金山的天气,但我不知道。我需要调用天气查询工具。”
-
行动(Action): LLM 决定调用一个具体的工具,并生成调用该工具所需的参数。
例如:Action: search_weather(location=“San Francisco”)。
-
观察(Observation):系统执行该行动(调用外部 API),并将返回的结果作为“观察”数据提供给LLM。
例如:Observation: “旧金山今天晴,22摄氏度。”
-
再次思考: LLM 接收到新的观察数据,再次进入思考环节,判断任务是否完成,或是否需要进一步的行动。
例如:“我已经获得了天气信息,现在可以回答用户的问题了。”
在这个循环中,数据流是根据 LLM 的“思考”结果动态生成的。当LLM判断需要外部数据时,它会主动触发一个“行动”来获取数据,然后将获取到的“观察”数据整合进自己的上下文中,用于下一步的决策。
Planning 和任务分解
对于更复杂的任务,智能体通常会先进行规划(Planning)。一个高阶的规划模块会将用户的宏大目标分解成一系列更小、更具体、可执行的子任务。
数据流向: 规划模块的输出是一份“计划清单”(Planning List),这份清单定义了后续一系列模块的调用顺序和数据依赖关系。
(前一阵子流行的 Claude Code,刚更新的 Cursor v1.2,以及上个版本流行的 Gemini/GPT DeepResearch 就属于这个架构)
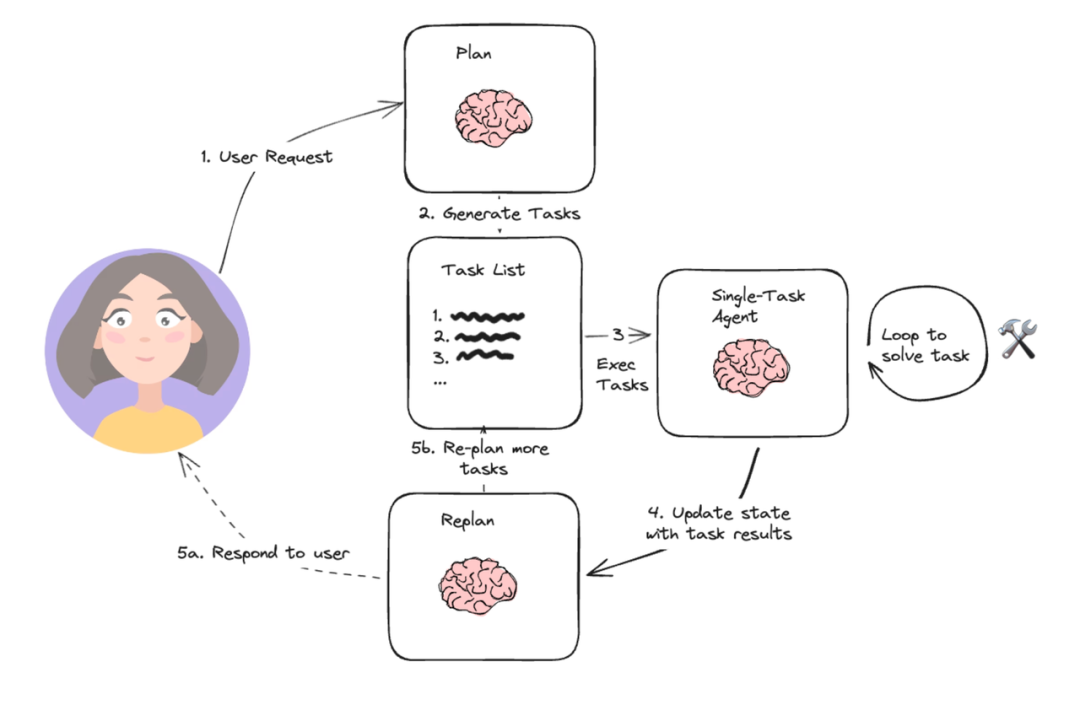
例如,对于“帮我策划一次巴黎三人五日游”的请求,规划模块可能会生成如下计划,并定义了每个步骤所需的数据输入和输出:
- [获取用户预算和偏好] -> [搜索往返机票]
- [机票信息] -> [根据旅行日期和预算搜索酒店]
- [酒店信息] -> [规划每日行程]
- [机票、酒店、行程信息] -> [生成最终行程单和预算报告]
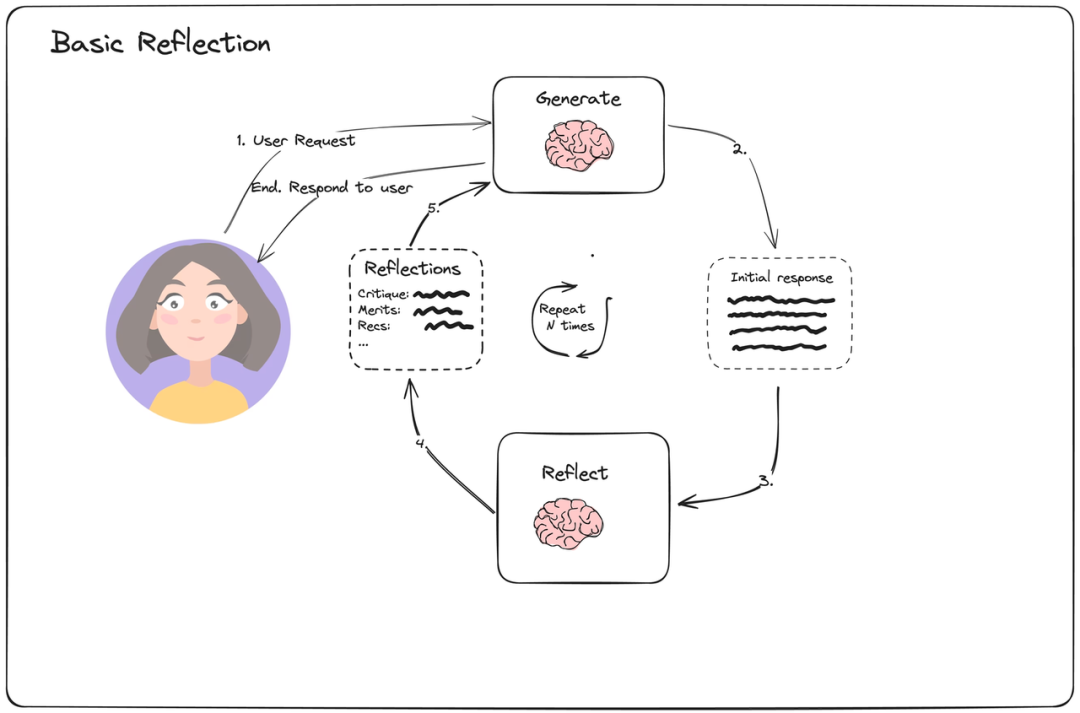
Reflection 机制
先进的智能体架构还包含反思(Reflection)机制 。智能体在执行完一个动作或完成一个子任务后,会评估其结果的质量和正确性。如果发现问题,它可以自我修正,重新规划路径。
(这是截止撰文时,各大主流 deep research 平台使用的核心技术方案) 数据流向: 这是一个反馈循环。模块的输出不仅流向下一个任务模块,还会流向一个“评估器”模块。评估器的输出(如“成功”、“失败”、“信息不足”)会反过来影响规划模块,从而调整后续的数据流向。
框架与工具
上述的架构和机制并非凭空存在,而是通过具体的开发框架实现的。其中,LangGraph 作为 LangChain 的扩展,为构建具有显式数据流的智能体系统提供了强大的工具集。
LangGraph:用图(Graph)定义工作流(Workflow)
LangGraph 的核心思想是将智能体应用构建成一个状态图(State Graph)。这个图由节点和边组成,清晰地定义了数据如何在不同模块间流动
- 状态(State):这是整个图的核心,一个所有节点共享的中央数据对象。你可以把它想象成一个“数据总线”或共享内存。开发者需要预先定义 State 的结构,每个节点在执行时都可以读取和更新这个 State 对象 。
- 节点(Nodes):代表工作流中的一个计算单元或一个步骤。每个节点通常是一个 Python 函数,它接收当前的 State 作为输入,执行特定任务(如调用 LLM、执行工具、处理数据),然后返回对 State 的更新。
- 边(Edges):连接节点,定义了工作流的路径,即数据在 State 更新后应该流向哪个节点。
- 简单边(Simple Edges):定义了固定的、无条件的流向,用于实现链式工作流。
- 条件边(Conditional Edges): 用于实现路由逻辑。它会根据一个函数的输出来决定接下来应该走向哪个节点,从而实现流程的分支 。
- 检查点(Checkpointer): LangGraph 提供了持久化机制,可以在每一步执行后自动保存 State 的状态。这对于构建需要长期记忆、可中断和恢复、或需要 Human-in-the-Loop 的复杂业务流程至关重要。
复杂业务流程的 AI 智能体,其核心挑战已从单纯优化信息检索(如 RAG)或提示词,转向了对内部工作流和数据流的精心设计与编排。
Context Engineering 的未来
- Graph RAG 的兴起:标准的基于向量的 RAG 在处理高度互联的数据时存在局限。而利用知识图谱的图 RAG 不仅能检索离散的信息块,还能检索它们之间的显式关系。这使得模型能够进行更复杂的多跳推理,并提供上下文更准确的回答 。
- 智能体自主性的增强:像 Self-RAG 和 Agentic RAG 这样更自主的系统将成为趋势,LLM 将承担更多管理自身上下文的责任。这将模糊 Context Engineering 系统与 LLM 本身之间的界限。
- 超越固定上下文窗口:针对 Lost in the Middle 问题的研究正在进行中,包括探索新的模型架构(如改进的位置编码)和训练技术。这些研究的突破可能会从根本上改变当今 Context Engineering 师所面临的约束。
- 终极目标:Context Engineering 本质上是一座桥梁,它是一套复杂的补偿机制,用以弥补 LLM “don’t read minds—they read tokens”的现实。人工智能研究的长期目标是创造出具有更强大内部世界模型的 AI,从而减少对此类庞大外部上下文支架的依赖。 Context Engineering 的演进,将是衡量我们朝此目标迈进的关键指标。
参考链接:
- www.microsoftpressstore.com, https://www.microsoftpressstore.com/articles/article.aspx?p=3192408&seqNum=2#:~:text=Prompt%20engineering%20involves%20understanding%20the,as%20additional%20context%20or%20knowledge).
- Core prompt learning techniques | Microsoft Press Store, https://www.microsoftpressstore.com/articles/article.aspx?p=3192408&seqNum=2
- Prompt Engineering for AI Guide | Google Cloud, https://cloud.google.com/discover/what-is-prompt-engineering
- arXiv:2402.07927v2 [cs.AI] 16 Mar 2025, https://arxiv.org/pdf/2402.07927
- What is Prompt Engineering? - AI Prompt Engineering Explained - AWS, https://aws.amazon.com/what-is/prompt-engineering/
- Which Prompting Technique Should I Use? An Empirical Investigation of Prompting Techniques for Software Engineering Tasks - arXiv, https://arxiv.org/html/2506.05614v1
- The rise of “context engineering” - LangChain Blog, https://blog.langchain.com/the-rise-of-context-engineering/
- Context Engineering - LangChain Blog, https://blog.langchain.com/context-engineering-for-agents/
- A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications - arXiv, https://arxiv.org/html/2402.07927v2
- Unleashing the potential of prompt engineering for large language models - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC12191768/
- Retrieval Augmented Generation (RAG) for LLMs - Prompt Engineering Guide, https://www.promptingguide.ai/research/rag
- What Is Retrieval-Augmented Generation aka RAG - NVIDIA Blog, https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training - arXiv, https://arxiv.org/html/2311.09198v2
- Mastering Chunking Strategies for RAG: Best Practices & Code Examples - Databricks Community, https://community.databricks.com/t5/technical-blog/the-ultimate-guide-to-chunking-strategies-for-rag-applications/ba-p/113089
- How to do retrieval with contextual compression - Python LangChain, https://python.langchain.com/docs/how_to/contextual_compression/
- How do I choose between Pinecone, Weaviate, Milvus, and other vector databases?, https://milvus.io/ai-quick-reference/how-do-i-choose-between-pinecone-weaviate-milvus-and-other-vector-databases
- Retrieve & Re-Rank — Sentence Transformers documentation, https://www.sbert.net/examples/sentence_transformer/applications/retrieve_rerank/README.html
- arXiv:2406.14673v2 [cs.CL] 4 Oct 2024, https://arxiv.org/pdf/2406.14673?
- Lost in the Middle: How Language Models Use Long Contexts - Stanford Computer Science, https://cs.stanford.edu/~nfliu/papers/lost-in-the-middle.arxiv2023.pdf
- LLMs Get Lost In Multi-Turn Conversation - arXiv, https://arxiv.org/pdf/2505.06120
- How to do retrieval with contextual compression - LangChain.js, https://js.langchain.com/docs/how_to/contextual_compression/
- Building Effective AI Agents \ Anthropic, https://www.anthropic.com/research/building-effective-agents
- What is LLM Orchestration? - IBM, https://www.ibm.com/think/topics/llm-orchestration
- Agent architectures, https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
- What is a ReAct Agent? | IBM, https://www.ibm.com/think/topics/react-agent
- LLM Agents - Prompt Engineering Guide, https://www.promptingguide.ai/research/llm-agents

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)