
Transformer 算法全面解析!从原理到实战,一篇搞定大模型核心技术与收藏必备指南!
本文系统解析了Transformer架构的技术演进、核心原理与实现细节,涵盖自注意力机制、位置编码等关键技术,并提供完整PyTorch代码实现。同时介绍了Transformer在机器翻译、文本生成、计算机视觉等领域的生产级应用案例,以及模型压缩、推理优化等扩展技术,为学习大模型技术提供全面指导。
一、引言与技术背景
1.1 序列建模的技术挑战
在深度学习的发展历程中,序列数据处理一直是核心挑战之一。自然语言、时间序列、音频信号等都具有序列特征,传统的处理方法面临诸多技术瓶颈。在 Transformer 架构出现之前,序列建模主要依赖于循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU)。
传统 RNN 架构存在根本性的缺陷:序列计算的固有顺序性。在 RNN 中,当前时刻的状态计算必须依赖于前一时刻的状态,这种串行依赖关系导致了三个核心问题:
首先是无法并行化的问题。RNN 必须按时间步顺序计算,严重限制了训练效率,特别是在处理长序列时,这种限制变得尤为突出。其次是内存限制,长序列处理时内存约束限制了批处理大小。第三是计算效率低下,尽管有因子化技巧和条件计算等改进,但顺序计算的根本约束仍然存在。
编码器 - 解码器架构的出现试图解决这些问题,但也带来了新的挑战。传统的编码器 - 解码器结构使用一个固定长度的上下文向量来表示整个源序列,这在 Bahdanau 等人(2014)的工作中被明确指出是性能瓶颈。编码器需要将整个输入序列的信息压缩到一个固定长度的向量中,导致长序列时信息损失严重,性能下降。
1.2 注意力机制的发展历程
注意力机制的发展为解决序列建模问题提供了新的思路。2014 年,Bahdanau 等人在机器翻译中首次引入编码器 - 解码器注意力机制,解决 RNN 处理长文本的缺陷。Bahdanau 注意力机制通过动态关注编码器的不同位置,允许解码器软性地搜索与当前目标词最相关的源词位置,显著提升了翻译质量,如英法翻译 BLEU 分数提升 30%+。
随后,Luong 等人在 2015 年提出了 “有效的基于注意力的神经机器翻译方法”,进一步改进了注意力机制的实现方式。这些早期的注意力机制虽然取得了显著效果,但仍然依赖于 RNN 基础架构,没有完全发挥注意力机制的潜力。
2017 年,Google 团队提出了革命性的 Transformer 架构,基于自注意力(Self-Attention)实现并行计算,彻底改变了 NLP 范式。Transformer 的出现标志着注意力机制从辅助组件转变为主导架构,开启了深度学习的新纪元。
1.3 Transformer 的革命性突破
2017 年,Google 的 8 名研究人员联合发表了名为《Attention is All You Need》的论文,提出了 Transformer 架构,这一创新真正解决了 RNN 和 CNN 在处理序列数据时存在的问题。
Transformer 的核心突破在于其完全基于注意力机制,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构。这一架构设计带来了多重革命性变化:
并行化突破:自注意力机制允许同时计算所有位置的关系,彻底解决了 RNN 的序列依赖问题,实现了高度并行化计算。
长程依赖建模:自注意力机制不受距离限制,能够直接连接序列中任意两个位置,有效捕获长距离依赖关系。
架构简化:相比复杂的递归结构,Transformer 采用了相对简单的网络架构,由编码器和解码器两个主要部分组成,每个部分都由多层相同的模块堆叠而成。
性能提升:在 WMT 2014 英德翻译任务中,Transformer 大模型达到 28.4 BLEU,比现有最佳结果提高 2 个以上 BLEU;在英法翻译任务中达到 41.0 BLEU 的单模型最佳成绩,且仅用 8 个 GPU 训练 3.5 天,远低于文献中最佳模型的训练成本。
Transformer 的出现不仅提升了机器翻译的性能,更重要的是为后续 BERT、GPT 等大模型奠定了理论基础,开启了预训练语言模型的新时代,真正体现了 “Attention is All You Need” 的核心思想。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

二、理论基础与架构解析
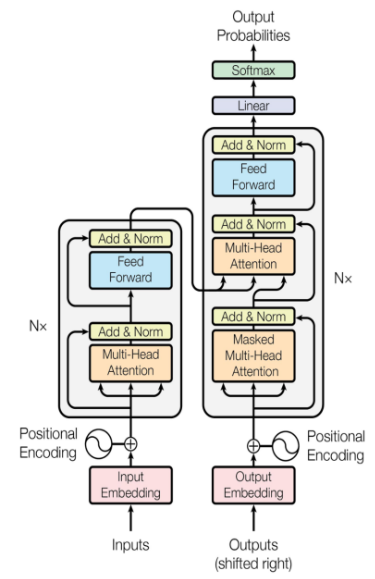
2.1 《Attention is All You Need》核心思想
《Attention is All You Need》这篇具有里程碑意义的论文于 2017 年发表在 NeurIPS 会议上,作者为 Ashish Vaswani 等来自 Google Brain 和 Google Research 的研究人员。论文提出了一种新的简单网络架构 Transformer,它完全基于注意力机制,完全摒弃了递归和卷积。
论文的核心思想可以概括为 “Attention is All You Need”—— 仅用注意力机制就足够了。这一思想彻底改变了 NLP 领域的建模范式,提出的 Transformer 架构完全摒弃了传统的 RNN/CNN,仅靠自注意力就能完成高质量序列建模,成为 GPT、BERT、ChatGPT 等大模型的根基。
论文的主要贡献包括:
-
提出了完全基于注意力机制的 Transformer 架构,摒弃了循环和卷积结构
-
引入了自注意力机制和多头注意力机制,实现了高效的并行计算
-
设计了位置编码机制,为模型提供序列中的位置信息
-
在机器翻译任务上取得了当时的最佳性能,同时大幅提高了训练效率
论文中提出的架构在两个机器翻译任务上进行了实验,结果显示这些模型在质量上更优,同时更易于并行化,训练时间显著减少。
2.2 编码器 - 解码器架构设计
Transformer 采用经典的编码器 - 解码器架构,但每个部分都由多层相同的模块堆叠而成。这种设计具有高度的模块化特征,便于模型的扩展和优化。
2.2.1 整体架构概览
Transformer 模型的整体架构由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责处理输入序列,解码器负责生成输出序列,两者通过注意力机制进行信息交互。
编码器由 N 个相同层堆叠而成,每个层包含两个子层:多头自注意力(Multi-Head Self-Attention)和前馈神经网络(Feed Forward Network),每个子层后都采用残差连接和层归一化。
解码器同样由 N 个相同层堆叠,但相比编码器多了一个子层:掩码多头自注意力(Masked Multi-Head Attention),用于防止当前位置看到未来位置的信息,此外还有编码器 - 解码器注意力(Encoder-Decoder Attention),用于关注编码器输出。
2.2.2 编码器结构详解
编码器的每一层结构可以表示为:
LayerNorm(x + MultiHeadSelfAttention(x))
LayerNorm(y + FeedForward(y))
其中 x 是输入,y 是多头自注意力的输出。编码器的信息流如下:输入序列首先通过嵌入层和位置编码层,得到初始表示;初始表示通过多个编码器层的处理,每一层都应用多头自注意力机制,然后通过前馈神经网络进行变换,在每一步都应用残差连接和层归一化。
编码器的核心创新在于自注意力机制,它允许模型直接计算序列中任意两个单词之间的依赖关系,而不考虑它们之间的距离。这使得模型能够捕获长距离的上下文信息。
2.2.3 解码器结构详解
解码器层比编码器层多了一个子层,形成了三部分结构:
LayerNorm(x + MaskedMultiHeadSelfAttention(x))
LayerNorm(y + MultiHeadAttention(y, encoder_outputs))
LayerNorm(z + FeedForward(z))
解码器的第一个子层是掩码多头自注意力,用于自回归生成过程中防止看到未来的信息。第二个子层是编码器 - 解码器注意力,将编码器的输出作为键(Key)和值(Value),解码器的当前状态作为查询(Query),实现了编码器和解码器之间的信息交互。
解码器的掩码注意力机制是生成式任务的关键,它确保在生成第 i 个位置的输出时,模型只能看到前 i-1 个位置的信息,而不能看到未来的信息,这对于自回归生成(如机器翻译、文本生成)至关重要。
2.3 自注意力机制原理与实现
自注意力机制是 Transformer 架构的核心创新,它允许模型直接计算序列中任意两个单词之间的依赖关系,而不考虑它们之间的距离。
2.3.1 缩放点积注意力机制
自注意力机制的基础是缩放点积注意力(Scaled Dot-Product Attention),其计算过程可以用以下公式表示: 其中 Q 表示查询(Query),K 表示键(Key),V 表示值(Value),d_k是键向量的维度,用于缩放点积结果以避免梯度消失。
这一机制的核心思想是:将一个查询和一组键 - 值对映射到一个输出,输出是值的加权求和,其中每个值的权重通过查询与相应键的兼容函数来计算。当两个向量做内积时,如果它们的维度相同,向量内积越大,余弦值越大,相似度越高;如果内积值为 0,它们是正交的,相似度也为 0。
2.3.2 多头注意力机制设计
多头注意力机制是自注意力机制的重要扩展,它通过多个 “头” 来并行计算不同子空间的注意力,然后将结果拼接起来。多头注意力的设计公式如下: 其中每个头的计算为: 多头注意力机制的核心优势在于能够从不同子空间捕捉信息。具体实现中,输入的信息会先被映射到多个不同的子空间,每个头算出自己的 “讨论结果” 后,再将所有头的结果拼接起来,经过一次线性变换,得到综合各个角度的信息。
多头注意力机制将查询、键和值矩阵分成多个头(即多个子空间),每个头具有不同的线性变换参数。在查询、键和值的每个映射版本上,并行执行注意力功能,然后将它们拼接起来再次映射,生成一个最终值。
2.3.3 自注意力与传统 RNN 的对比优势
相比传统的 RNN 架构,自注意力机制具有多重优势:
并行计算能力:自注意力机制的计算过程可拆解为三步矩阵运算,而矩阵乘法天然支持并行计算,打破了序列时序依赖,将整个序列的计算转化为矩阵运算,从而充分利用 GPU/TPU 的并行处理能力。
长程依赖建模能力:自注意力机制能够建模词序(通过位置编码),能够建模上下文依赖(直接连接所有位置),支持不定长输入(动态计算注意力权重),支持输入输出不等长(通过编码器 - 解码器结构)。
可解释性增强:Transformer 中的自注意力机制为每个位置的输出都分配了一个权重,这些权重表明了输入序列中不同位置对于输出的贡献,使得模型具有更好的可解释性。
模型容量扩展:Transformer 可以很容易地堆叠多层,从而增加模型容量,而 RNN 在堆叠多层时容易出现梯度消失问题。
2.4 位置编码机制
由于 Transformer 模型不包含循环或卷积,为了让模型利用序列的顺序信息,必须加入序列中关于字符相对或者绝对位置的一些信息。位置编码就是为了解决这一问题而设计的关键机制。
2.4.1 绝对位置编码
绝对位置编码是最常见的一种位置编码方法,其思想是在每个输入序列的元素上添加一个位置向量,以表示该元素在序列中的具体位置。这个位置向量通常通过固定的函数生成,与输入数据无关。
Transformer 论文中使用的是正弦和余弦函数生成的位置编码,其公式为: 其中 pos 是位置,i 是维度索引, 是模型维度。这种位置编码的设计基于一个假设,即位置之间的相对关系可以通过三角函数来表达,波长形成了从 2π 到 10000・2π 的几何数列。
选择正弦曲线的原因在于它允许模型扩展到比训练中遇到的序列长度更长的序列,并且对任意确定的偏移 k, 可以表示为 的线性函数,这使得模型能够很容易地通过相对位置来学习。
2.4.2 相对位置编码与旋转位置编码
除了绝对位置编码,还有相对位置编码和旋转位置编码(RoPE)等改进方法。
相对位置编码关注 token 间的相对距离,适合 Transformer-XL 和 DeBERTa 等长序列模型。相对位置编码不需要为每个绝对位置学习或计算一个嵌入向量,而是直接对相对距离进行建模。
旋转位置编码(RoPE) 结合了绝对位置编码与相对位置编码的优势,高效且可扩展。RoPE 的核心思想是,不再通过向量相加的方式注入位置信息,而是根据词元的绝对位置,对其查询(Query)和键(Key)向量进行旋转。这个旋转操作通过一个旋转矩阵 实现。
2.4.3 位置编码的实现方式
在实际实现中,位置编码有多种方式:
固定位置编码:如上述的正弦余弦位置编码,具有简洁高效且无需额外训练参数的特性,成为 Transformer 模型的标准配置之一。
可学习位置编码:每一个位置都分配一个可训练的向量,直接加入输入 token 的 embedding 中。GPT 系列采用了这种方式,通过模型训练学习得到位置编码。
位置编码的添加方式:位置编码的本质是为序列中每个「位置(pos)」生成一个和「词嵌入(Embedding)维度相同」的向量(论文中是 512 维),然后把这个 “位置向量” 和 “词嵌入向量” 直接相加,这样每个 token 就同时包含了 “语义信息(词嵌入)” 和 “位置信息(位置编码)”。
2.5 前馈网络与残差连接
Transformer 的编码器和解码器中的每个层还包含一个全连接的前馈网络,该网络分别单独应用于每一个位置。
2.5.1 前馈神经网络设计
前馈神经网络由两个线性变换和中间的一个 ReLU 激活函数组成,其数学表示为: 其中 和 是权重矩阵, 和 是偏置向量。尽管线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。另一种描述方式是将其比作两个内核大小为 1 的卷积。
在标准的 Transformer 实现中,输入和输出的维度为 ,内部层的维度 。这种设计使得模型能够在低维空间中进行高效的信息交互,同时在高维空间中进行复杂的非线性变换。
2.5.2 残差连接机制
残差连接(Residual Connection)用于解决深度神经网络中的梯度消失问题。在 Transformer 中,每个子层的输出都与输入相加,然后再进行层归一化: 其中 表示子层的输出。这种设计允许梯度直接通过残差路径传播,从而使训练非常深的网络成为可能。
残差连接的具体实现包括:
-
在多头自注意力子层后:
-
在前馈神经网络子层后:
每个子层后都应用残差连接和层归一化,有助于缓解梯度消失问题,提高模型的训练稳定性。
2.5.3 层归一化技术
层归一化(Layer Normalization)是 Transformer 中用于稳定训练的重要技术。与批归一化不同,层归一化是对每个样本的每个层进行归一化,而不是对每个批次的每个通道进行归一化。这使得层归一化在处理变长序列时更加有效。
层归一化的计算如下: 其中 是均值, 是方差, 和 是可学习的参数, 是一个小的常数,用于防止除零错误。
层归一化的优势在于:
-
适用于处理变长序列,不需要固定的批大小
-
能够对每个样本单独进行归一化,更好地适应不同样本的分布差异
-
在深层网络中能够有效防止梯度消失和梯度爆炸问题
2.6 掩码机制原理
掩码机制是 Transformer 解码器中的关键组件,特别是在自回归生成任务中起到至关重要的作用。
2.6.1 掩码自注意力机制
掩码注意力(Causal Attention 或 Masked Attention)确保在生成第 i 个位置的输出时,模型只能看到前 i-1 个位置的信息,而不能看到未来的信息。这对于自回归生成(如机器翻译、文本生成)至关重要。
掩码是一个上三角矩阵,对角线以上的元素都被设置为负无穷大,这样在应用 softmax 后,这些位置的权重将趋近于 0。具体实现中,掩码矩阵的生成可以通过以下方式: 其中triu函数生成上三角矩阵,diagonal=1表示对角线及以下为 0,以上为 1,然后转换为布尔类型。
2.6.2 填充掩码机制
除了自注意力掩码,Transformer 还使用填充掩码(Padding Mask)来处理变长序列中的填充 token。填充掩码用于在注意力计算中忽略序列中的填充部分,避免无效信息的干扰。
填充掩码的生成通常基于序列中的填充索引(如 0): 其中seq是输入序列,等于 0 的位置表示填充,需要被忽略。这个掩码在多头注意力计算时作为参数传入,确保注意力机制不会关注到填充位置。
掩码机制的应用确保了:
-
解码器在生成过程中不会看到未来的信息,保证了生成的因果性
-
填充 token 不会参与注意力计算,提高了模型的效率和准确性
三、PyTorch 代码实现详解
3.1 PyTorch 官方 API 与基础组件
PyTorch 提供了完整的 Transformer 相关 API,主要集中在torch.nn模块中。了解这些官方 API 是实现自定义 Transformer 的基础。
3.1.1 官方 Transformer 模块
PyTorch 的nn.Transformer模块提供了完整的 Transformer 实现,其定义如下:
class torch.nn.Transformer(
d_model=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6,
dim_feedforward=2048,
dropout=0.1,
activation="relu",
custom_encoder=None,
custom_decoder=None,
layer_norm_eps=1e-5,
batch_first=False,
norm_first=False,
device=None,
dtype=None
))
其中主要参数包括:
-
d_model:编码器 / 解码器输入的特征维度(默认 512)
-
nhead:多头注意力模型中的头数(默认 8)
-
num_encoder_layers:编码器中的子编码器层数(默认 6)
-
num_decoder_layers:解码器中的子解码器层数(默认 6)
-
dim_feedforward:前馈网络模型的维度(默认 2048)
-
dropout:Dropout 概率(默认 0.1)
-
activation:中间层的激活函数(默认 “relu”)
-
batch_first:如果为 True,输入输出张量格式为 (batch, seq, feature)(默认 False)
-
norm_first:如果为 True,在注意力和前馈操作前进行层归一化(默认 False)
3.1.2 编码器和解码器层
PyTorch 还提供了单独的编码器层和解码器层:
TransformerEncoderLayer:
class torch.nn.TransformerEncoderLayer(
d_model,
nhead,
dim_feedforward=2048,
dropout=0.1,
activation="relu",
layer_norm_eps=1e-5,
batch_first=False,
norm_first=False,
device=None,
dtype=None
)
TransformerDecoderLayer:
class torch.nn.TransformerDecoderLayer(
d_model,
nhead,
dim_feedforward=2048,
dropout=0.1,
activation="relu",
layer_norm_eps=1e-5,
batch_first=False,
norm_first=False,
device=None,
dtype=None
)
这些层的参数与整体 Transformer 类似,但只实现了单层的功能,可以通过TransformerEncoder和TransformerDecoder进行堆叠。
3.1.3 多头注意力机制
PyTorch 的nn.MultiheadAttention模块实现了多头注意力机制:
class torch.nn.MultiheadAttention(
embed_dim,
num_heads,
dropout=0.0,
bias=True,
add_bias_kv=False,
add_zero_attn=False,
kdim=None,
vdim=None,
batch_first=False,
device=None,
dtype=None
)
其中embed_dim是嵌入维度,num_heads是头数,其他参数控制注意力机制的具体行为。
3.2 基础组件实现详解
为了深入理解 Transformer 的工作原理,我们将从零开始实现关键组件。
3.2.1 位置编码实现
位置编码层的实现需要生成正弦和余弦编码:
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""位置编码层:为输入序列添加位置信息"""
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建位置编码矩阵 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
# 位置索引 (max_len, 1)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 除数项:计算频率
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
)
# 正弦波编码偶数位置
pe[:, 0::2] = torch.sin(position * div_term)
# 余弦波编码奇数位置
pe[:, 1::2] = torch.cos(position * div_term)
# 增加batch维度 (1, max_len, d_model)
pe = pe.unsqueeze(0)
# 注册为缓冲区,不参与梯度更新
self.register_buffer('pe', pe)
def forward(self, x):
"""
前向传播
参数:
- x: 输入张量 (batch_size, seq_len, d_model)
返回:
- 添加位置编码后的张量
"""
return x + self.pe[:, :x.size(1)]
这个实现中,register_buffer方法将位置编码注册为缓冲区,不会参与梯度更新。位置编码的生成基于正弦和余弦函数,确保了不同位置具有唯一的编码表示。
3.2.2 缩放点积注意力实现
缩放点积注意力是多头注意力的基础:
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力机制"""
def __init__(self, dropout=0.1):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
"""
前向传播
参数:
- q: 查询张量 (batch_size, num_heads, seq_len, d_k)
- k: 键张量 (batch_size, num_heads, seq_len, d_k)
- v: 值张量 (batch_size, num_heads, seq_len, d_v)
- mask: 掩码张量 (batch_size, 1, 1, seq_len)
返回:
- 注意力输出 (batch_size, num_heads, seq_len, d_v)
- 注意力权重 (batch_size, num_heads, seq_len, seq_len)
"""
# 计算点积相似度
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.size(-1))
# 应用掩码
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attn_weights = self.dropout(F.softmax(scores, dim=-1))
# 计算加权和
output = torch.matmul(attn_weights, v)
return output, attn_weights
这个实现中,首先计算查询和键的点积,然后除以键维度的平方根进行缩放。如果存在掩码,则将掩码位置的分数设置为负无穷大。最后通过 softmax 计算注意力权重,并与值张量相乘得到输出。
3.2.3 多头注意力机制实现
多头注意力将输入分成多个头并行计算:
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, num_heads, d_model, dropout=0.1):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.d_k = d_model // num_heads
# 线性变换层
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
"""
前向传播
参数:
- q: 查询张量 (batch_size, seq_len, d_model)
- k: 键张量 (batch_size, seq_len, d_model)
- v: 值张量 (batch_size, seq_len, d_model)
- mask: 掩码张量 (batch_size, 1, seq_len)
返回:
- 多头注意力输出 (batch_size, seq_len, d_model)
- 注意力权重 (batch_size, num_heads, seq_len, seq_len)
"""
batch_size = q.size(0)
# 线性变换并分割头
q = self.w_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.w_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.w_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 如果掩码存在,扩展维度
if mask is not None:
mask = mask.unsqueeze(1) # (batch_size, 1, 1, seq_len)
# 缩放点积注意力
x, attn_weights = self.attention(q, k, v, mask)
# 拼接多头结果
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
# 最终线性变换
x = self.out_proj(x)
return x, attn_weights
这个实现中,首先通过线性变换将输入投影到新的空间,然后将其分割成多个头。在每个头上并行执行缩放点积注意力,最后将结果拼接并通过线性变换得到最终输出。
3.3 编码器与解码器实现
基于基础组件,我们可以构建完整的编码器和解码器。
3.3.1 编码器层实现
编码器层包含多头自注意力和前馈网络:
class EncoderLayer(nn.Module):
"""编码器层"""
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(nhead, d_model, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, dim_feedforward, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src, src_mask=None):
"""
前向传播
参数:
- src: 输入序列 (batch_size, seq_len, d_model)
- src_mask: 源序列掩码 (batch_size, 1, seq_len)
返回:
- 编码器层输出 (batch_size, seq_len, d_model)
"""
# 多头自注意力子层
src2, _ = self.self_attn(src, src, src, src_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
# 前馈神经网络子层
src2 = self.feed_forward(src)
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
编码器层的实现遵循标准的 Transformer 架构,每个子层后都应用残差连接和层归一化。第一个子层是多头自注意力,第二个子层是前馈网络。
3.3.2 解码器层实现
解码器层比编码器层多了一个编码器 - 解码器注意力子层:
class DecoderLayer(nn.Module):
"""解码器层"""
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(nhead, d_model, dropout)
self.multihead_attn = MultiHeadAttention(nhead, d_model, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, dim_feedforward, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
"""
前向传播
参数:
- tgt: 目标序列 (batch_size, seq_len, d_model)
- memory: 编码器输出 (batch_size, src_len, d_model)
- tgt_mask: 目标序列掩码 (batch_size, 1, seq_len)
- memory_mask: 编码器输出掩码 (batch_size, 1, src_len)
返回:
- 解码器层输出 (batch_size, seq_len, d_model)
"""
# 掩码多头自注意力子层
tgt2, _ = self.self_attn(tgt, tgt, tgt, tgt_mask)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# 多头跨注意力子层
tgt2, _ = self.multihead_attn(tgt, memory, memory, memory_mask)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
# 前馈神经网络子层
tgt2 = self.feed_forward(tgt)
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
解码器层的第一个子层是掩码多头自注意力,用于自回归生成过程中防止看到未来信息。第二个子层是编码器 - 解码器注意力,将编码器的输出作为键和值,解码器的当前状态作为查询。
3.3.3 前馈网络实现
前馈网络对每个位置独立应用相同的变换:
class PositionwiseFeedForward(nn.Module):
"""位置前馈神经网络"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
前向传播
参数:
- x: 输入张量 (batch_size, seq_len, d_model)
返回:
- 前馈网络输出 (batch_size, seq_len, d_model)
"""
return self.w_2(self.dropout(F.relu(self.w_1(x))))
前馈网络由两个线性层组成,中间使用 ReLU 激活函数。输入和输出维度为 512,内部层维度为 2048,符合 Transformer 论文中的配置。
3.4 完整 Transformer 模型构建
基于上述组件,我们可以构建完整的 Transformer 模型。
3.4.1 完整模型实现
class Transformer(nn.Module):
"""完整Transformer模型"""
def __init__(
self,
src_vocab_size,
tgt_vocab_size,
d_model=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6,
dim_feedforward=2048,
dropout=0.1,
max_len=5000
):
super(Transformer, self).__init__()
# 嵌入层
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
# 位置编码
self.positional_encoding = PositionalEncoding(d_model, max_len)
# 编码器
encoder_layer = EncoderLayer(d_model, nhead, dim_feedforward, dropout)
self.encoder = nn.TransformerEncoder(encoder_layer, num_encoder_layers)
# 解码器
decoder_layer = DecoderLayer(d_model, nhead, dim_feedforward, dropout)
self.decoder = nn.TransformerDecoder(decoder_layer, num_decoder_layers)
# 输出层
self.out = nn.Linear(d_model, tgt_vocab_size)
# 初始化参数
self._init_weights()
def _init_weights(self):
"""参数初始化"""
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""
前向传播
参数:
- src: 源序列 (batch_size, src_len)
- tgt: 目标序列 (batch_size, tgt_len)
- src_mask: 源序列掩码 (batch_size, 1, src_len)
- tgt_mask: 目标序列掩码 (batch_size, 1, tgt_len)
返回:
- 模型输出 (batch_size, tgt_len, tgt_vocab_size)
"""
# 嵌入和位置编码
src = self.src_embedding(src) * math.sqrt(self.src_embedding.embedding_dim)
tgt = self.tgt_embedding(tgt) * math.sqrt(self.tgt_embedding.embedding_dim)
src = self.positional_encoding(src)
tgt = self.positional_encoding(tgt)
# 编码器
memory = self.encoder(src, src_mask)
# 解码器
output = self.decoder(tgt, memory, tgt_mask, memory_mask=src_mask)
# 输出层
output = self.out(output)
return output
def generate_square_subsequent_mask(self, sz):
"""生成后续位置掩码"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
这个实现中,模型包含了完整的编码器 - 解码器架构。嵌入层将输入序列转换为向量表示,位置编码添加位置信息。编码器处理源序列生成记忆张量,解码器根据记忆张量和目标序列生成输出。输出层将解码器输出转换为词汇表大小的概率分布。
3.4.2 掩码生成函数
Transformer 模型还需要实现掩码生成功能,特别是用于解码器的后续位置掩码:
def generate_square_subsequent_mask(sz):
"""生成后续位置掩码"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
这个函数生成一个上三角矩阵,对角线以上的元素(未来位置)被设置为负无穷大,确保解码器在生成过程中无法看到未来的信息。
3.5 训练循环与优化设置
构建好模型后,需要实现训练循环和优化设置。
3.5.1 训练循环实现
def train_model(model, train_loader, optimizer, criterion, num_epochs, device):
"""训练模型"""
model.train()
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (src, tgt) in enumerate(train_loader):
src = src.to(device)
tgt = tgt.to(device)
# 生成掩码
tgt_mask = model.generate_square_subsequent_mask(tgt.size(1)).to(device)
# 前向传播
output = model(src, tgt[:, :-1], src_mask=None, tgt_mask=tgt_mask)
# 计算损失
loss = criterion(output.reshape(-1, output.size(-1)), tgt[:, 1:].reshape(-1))
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if batch_idx % 100 == 0:
print(f'Epoch: {epoch+1}, Batch: {batch_idx}, Loss: {loss.item():.4f}')
print(f'Epoch {epoch+1} completed, Average Loss: {total_loss/len(train_loader):.4f}')
训练循环中,每个批次的数据经过模型处理,生成输出。损失函数使用交叉熵损失,计算输出与目标序列的差异。通过反向传播更新模型参数。
3.5.2 优化器与学习率调度
Transformer 使用 Adam 优化器,并设置特定的学习率调度策略:
def get_optimizer_and_scheduler(model, lr=0.0001, betas=(0.9, 0.98), eps=1e-9, warmup_steps=4000):
"""获取优化器和学习率调度器"""
optimizer = torch.optim.Adam(
model.parameters(),
lr=lr,
betas=betas,
eps=eps
)
# 学习率调度:线性预热 + 平方根衰减
def lr_lambda(step):
if step < warmup_steps:
return float(step) / float(max(1, warmup_steps))
else:
return 0.5 * (1.0 + math.cos(math.pi * (step - warmup_steps) / (total_steps - warmup_steps)))
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
return optimizer, scheduler
这个实现中,Adam 优化器的参数设置为 β1=0.9,β2=0.98,ϵ=1e-9,符合 Transformer 论文的建议。学习率调度采用线性预热加余弦衰减的策略,预热步数设置为 4000 步。
3.5.3 数据加载与预处理
数据预处理是训练的重要环节,需要实现数据加载器和预处理函数:
class TranslationDataset(Dataset):
"""翻译数据集"""
def __init__(self, src_sentences, tgt_sentences, src_tokenizer, tgt_tokenizer, max_len):
self.src_sentences = src_sentences
self.tgt_sentences = tgt_sentences
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
self.max_len = max_len
def __len__(self):
return len(self.src_sentences)
def __getitem__(self, idx):
src_tokens = self.src_tokenizer.tokenize(self.src_sentences[idx])
tgt_tokens = self.tgt_tokenizer.tokenize(self.tgt_sentences[idx])
# 添加起始和结束标记
src_tokens = [self.src_tokenizer.bos_token] + src_tokens + [self.src_tokenizer.eos_token]
tgt_tokens = [self.tgt_tokenizer.bos_token] + tgt_tokens + [self.tgt_tokenizer.eos_token]
# 截断或填充到固定长度
src_tokens = src_tokens[:self.max_len-1] + [self.src_tokenizer.pad_token] * max(0, self.max_len-1-len(src_tokens))
tgt_tokens = tgt_tokens[:self.max_len-1] + [self.tgt_tokenizer.pad_token] * max(0, self.max_len-1-len(tgt_tokens))
src_ids = self.src_tokenizer.convert_tokens_to_ids(src_tokens)
tgt_ids = self.tgt_tokenizer.convert_tokens_to_ids(tgt_tokens)
return torch.tensor(src_ids), torch.tensor(tgt_ids)
数据加载器需要处理变长序列,添加起始和结束标记,并进行截断和填充。在实际应用中,可以使用更复杂的分词器,如 BPE(Byte-Pair Encoding)分词器。
四、生产级应用案例
4.1 机器翻译系统
机器翻译是 Transformer 的原生应用场景,也是其最成功的应用之一。
4.1.1 多语言翻译平台
现代多语言翻译平台广泛采用基于 Transformer 的模型。以 Google Translate 为例,其在 2018 年全面采用基于 Transformer 的神经翻译引擎后,实现了三大突破:
长句处理能力跃升:支持最长 1000 词的长文本翻译,对 “复句嵌套”" 代词指代 " 等复杂语法结构的处理准确率提升 30% 以上。
语义连贯性增强:通过捕捉上下文语义关联,避免了 “逐词翻译” 导致的生硬感。比如将 “春风又绿江南岸” 翻译成英文时,能准确传递 “春风使江南岸变绿” 的动态语义,而非简单拆解为 “spring wind again green jiangnan bank”。
多语言适配效率提升:基于 Transformer 的 “多语言共享模型”,可同时支持 100 + 语言的翻译,新增一种语言的训练成本较此前降低 60%,这也是 Google Translate 能覆盖 133 种语言的核心技术支撑。
4.1.2 行业定制翻译系统
不同行业对翻译质量有特殊要求,基于 Transformer 的定制化翻译系统能够满足这些需求:
学术文献翻译系统:某大学图书馆的在线文献翻译系统使用基于 Transformer 的模型,能够将英文文献翻译成中文、西班牙语等多种语言。系统针对学术领域进行了专门优化,准确翻译专业术语和复杂句式。
新闻多语言翻译系统:某新闻机构的多语言新闻翻译系统使用基于 Transformer 的模型,能够将英文新闻报道翻译成多种语言。系统特别注重新闻语言的时效性和准确性,确保翻译质量满足新闻发布的要求。
视频字幕生成系统:某视频平台的多语言字幕生成系统使用基于 Transformer 的模型,能够将英文视频字幕翻译成多种语言。系统结合了语音识别和机器翻译技术,实现了从语音到多语言字幕的端到端处理。
4.1.3 跨境电商客服系统
某跨国电商公司利用 Transformer 跨语言迁移技术开发多语言客服系统,支持英语、法语、德语等实时翻译。系统在高资源语言语料上预训练后,迁移至低资源语言,处理效率提高 30%,客户满意度提升 15%,显著降低人工成本。
系统的技术特点包括:
-
支持 10 + 语言的实时翻译
-
针对电商领域的专业术语进行了优化
-
能够理解客户的复杂查询意图
-
支持多轮对话和上下文理解
4.2 文本生成与创作
基于 Transformer 的文本生成模型在内容创作领域展现出强大能力。
4.2.1 自动化写作工具
GPT 模型,尤其是 GPT-3 和 GPT-4,能够根据给定的输入生成连贯且高质量的文本,这使得它在文本创作、内容生成、摘要撰写等多个场景中都有了广泛的应用。
代码生成:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
# 初始化GPT-2模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
# 设置生成参数
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 提示文本
prompt = "def add_numbers(a, b):\n # 计算两个数字的和\n return"
# 编码提示文本
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
# 生成代码
output = model.generate(
input_ids,
max_length=100,
num_return_sequences=1,
temperature=0.7,
top_p=0.9
)
# 解码生成的代码
generated_code = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_code)
这段代码通过调用 GPT-2 模型,根据函数定义的提示生成了完整的 Python 函数实现。模型能够理解代码的上下文,并生成符合逻辑的代码片段。
4.2.2 创意内容生成
GPT 模型在创意内容生成方面表现出色,包括故事创作、诗歌写作、剧本编写等:
故事创作示例:
# 生成科幻故事开头
prompt = "在2045年的地球上,人类已经建立了与外星文明的联系。一天,一位年轻的宇航员"
output = model.generate(
tokenizer.encode(prompt, return_tensors="pt").to(device),
max_length=500,
num_return_sequences=3,
temperature=1.0,
top_k=50
)
for i, generated_text in enumerate(output):
print(f"故事{i+1}:\n{tokenizer.decode(generated_text, skip_special_tokens=True)}\n")
模型能够根据给定的开头生成连贯的故事内容,包括情节发展、人物描写和环境描述。
4.2.3 智能问答系统
基于 Transformer 的问答系统能够理解复杂的问题并提供准确的答案:
from transformers import pipeline
# 初始化问答管道
qa_pipeline = pipeline("question-answering")
# 上下文文本
context = "The Transformer architecture was proposed in 2017 by Google researchers in the paper 'Attention is All You Need'. It revolutionized natural language processing by introducing self-attention mechanisms that allow for parallel computation."
# 问题
questions = [
"When was the Transformer architecture proposed?",
"Who proposed the Transformer architecture?",
"What is the key innovation of Transformer?",
"What paper introduced the Transformer?"
]
# 进行问答
for question in questions:
result = qa_pipeline({
"context": context,
"question": question
})
print(f"问题: {question}")
print(f"答案: {result['answer']} (置信度: {result['score']:.4f})\n")
这个问答系统基于 BERT 等双向 Transformer 模型,能够准确理解问题意图并从上下文中提取相关信息。
4.3 计算机视觉应用
Vision Transformer(ViT)将 Transformer 架构成功应用于计算机视觉领域。
4.3.1 图像分类系统
ViT 模型已成为计算机视觉领域的基础模型,广泛应用于图像分类任务。以下是使用预训练 ViT 模型进行图像分类的示例:
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
# 初始化特征提取器和模型
feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
# 加载图像
image = Image.open("example_image.jpg").convert("RGB")
# 预处理图像
inputs = feature_extractor(images=image, return_tensors="pt")
# 推理
outputs = model(**inputs)
logits = outputs.logits
# 获取预测标签
predicted_class_idx = logits.argmax(-1).item()
predicted_label = model.config.id2label[predicted_class_idx]
print(f"预测类别: {predicted_label}")
print(f"置信度: {torch.softmax(logits, dim=-1)[0][predicted_class_idx].item():.4f}")
ViT 模型在 ImageNet 数据集上的准确率达到 88.5%,超过当时最优的 CNN 模型(ResNet-50)约 3 个百分点,且训练速度快 2 倍。
4.3.2 目标检测与分割
基于 Transformer 的目标检测模型 DETR(Detection Transformer)无需依赖传统的 “锚框”(Anchor),直接通过 Transformer 的注意力机制定位目标,对小目标(如图像中的小鸟)的检测准确率提升 25%。
在图像分割任务中,ViT 衍生出的 SegViT 模型能实现像素级的语义分割,如区分图像中的 “道路”" 行人 "“车辆”,在城市自动驾驶场景中表现优异。
4.3.3 医疗影像分析
ViT 在医疗影像分析领域展现出巨大潜力:
疾病自动诊断:利用 ViT 对 X 光片、CT 扫描等医学影像进行自动诊断,医生判读效率提升 40%,微小病灶检出率提高 18.7%,已通过 FDA 认证用于三家顶级医院的临床辅助诊断系统。
病理切片分类:通过对病理切片图像进行分类,帮助病理学家更快地识别疾病类型,提高诊断效率和准确性。
医学影像标记:自动识别和标记医学影像中的关键结构和异常区域,为医生提供诊断辅助。
4.3.4 工业质量检测
在工业质检领域,ViT 被应用于产品缺陷检测、生产线质量监控和零部件分类:
某工厂将 ViT_base_patch16_224 模型应用于工业视觉检测任务。通过对生产线上拍摄的图像进行实时分类,模型能够迅速识别出不合格产品。
系统的技术优势包括:
-
实时检测速度达到毫秒级
-
对微小缺陷的检测准确率超过 99%
-
能够识别多种类型的缺陷
-
支持多品种产品的混合检测
4.4 语音识别与音频处理
基于 Transformer 的语音识别系统在多个方面取得了突破性进展。
4.4.1 多语言语音识别系统
Whisper 是 OpenAI 开发的基于 Transformer 架构的自动语音识别(ASR)系统,具有以下特点:
多语言支持:支持 99 种语言的语音转录,包括中文、日语、阿拉伯语等小语种,对低资源语言(如斯瓦希里语)的转录准确率较传统模型提升 40%。
嘈杂环境鲁棒性:在地铁、菜市场等嘈杂环境中,Whisper 的转录准确率仍能保持 85% 以上,而传统模型的准确率会降至 50% 以下。
低资源适配:仅需少量标注数据(如 10 小时语音),就能通过微调适配特定场景,如医疗领域的专业术语转录、客服电话的对话转录。
以下是使用 Whisper 进行语音识别的示例:
import whisper
# 加载模型
model = whisper.load_model("base")
# 转录音频
result = model.transcribe("example_audio.wav", language="zh")
print("转录文本:")
print(result["text"])
print("\n详细结果:")
for segment in result["segments"]:
print(f"时间: {segment['start']:.2f} - {segment['end']:.2f}s")
print(f"内容: {segment['text']}")
print(f"置信度: {segment['avg_logprob']:.4f}\n")
4.4.2 语音翻译与语言检测
Whisper 的多任务统一架构能够同时处理语音识别、翻译、语言检测等多种任务:
语音翻译示例:
# 从英语语音翻译到中文
result = model.transcribe("example_audio_en.wav", task="translate", language="zh")
print("翻译结果:")
print(result["text"])
模型能够直接将英语语音翻译成中文文本,无需先转录再翻译的两步过程,大大提高了效率。
4.4.3 实时语音交互系统
基于 Transformer 的实时语音交互系统在多个场景中得到应用:
智能语音助手:小米的小爱同学等智能语音助手采用了基于 Transformer 的语音识别技术,能够理解用户的语音指令并提供相应的服务。
视频会议系统:Zoom 等视频会议平台的实时转录功能使用了 Whisper 技术,能够为会议提供实时的语音转文字服务,支持多种语言。
语音转写服务:YouTube 等视频平台的自动字幕功能利用 Whisper 技术,能够为视频自动生成准确的字幕,支持 99 种语言。
4.5 推荐系统与多模态应用
Transformer 在推荐系统和多模态融合方面展现出独特优势。
4.5.1 个性化推荐系统
推荐系统依据用户的历史行为和偏好,为用户推荐相关的产品、内容等。Transformer 模型能够捕捉用户与商品间复杂的交互模式,提供个性化推荐服务,提升用户购物体验和平台销售业绩。
基于 Transformer 的推荐系统架构:
用户行为序列 → 位置编码 → Transformer编码器 → 用户表示
商品特征 → 嵌入层 → Transformer编码器 → 商品表示
相似度计算 → 推荐列表生成
系统的核心优势包括:
-
能够建模用户行为的长期依赖关系
-
支持实时推荐和个性化排序
-
能够处理多模态信息(文本、图像、视频)
-
支持冷启动问题的解决
4.5.2 多模态内容理解
多模态学习指的是同时处理多种数据模态(如文本、图像、视频、音频等)的任务。在多模态任务中,Transformer 通过将不同模态的数据映射到共享的潜在空间中,从而实现多模态信息的融合。
CLIP 模型(图像 - 文本匹配):
CLIP 模型能够关联图像和文本,判断图像和文本是否匹配,常用于图像搜索、推荐系统等场景。以下是使用 CLIP 进行图像 - 文本匹配的示例:
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
# 初始化模型和处理器
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 图像和文本
image = Image.open("example_image.jpg").convert("RGB")
texts = ["一只猫在草地上玩耍", "一只狗在公园跑步", "风景照片"]
# 处理输入
inputs = processor(images=image, text=texts, return_tensors="pt", padding=True)
# 计算相似度
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像与文本的相似度得分
probs = logits_per_image.softmax(dim=1)
print("图像与各文本的匹配概率:")
for i, (text, prob) in enumerate(zip(texts, probs[0])):
print(f"{text}: {prob.item():.4f}")
4.5.3 视频理解与生成
基于 Transformer 的视频理解系统能够处理视频内容并生成相应的描述:
视频描述生成:
from transformers import VideoMAEFeatureExtractor, VideoMAEModel
import torch
# 初始化特征提取器和模型
feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
# 假设有一个视频张量 (num_frames, height, width, channels)
video_frames = torch.randn(16, 224, 224, 3) # 16帧视频
# 预处理
inputs = feature_extractor(video=video_frames, return_tensors="pt")
# 提取视频特征
outputs = model(**inputs)
video_features = outputs.pooler_output
# 可以将视频特征用于分类或生成描述
print(f"视频特征维度: {video_features.shape}")
4.5.4 科学计算与研究应用
Transformer 在科学计算领域也展现出巨大潜力:
蛋白质结构预测:DeepMind 的 AlphaFold2 基于 Transformer 架构,能够基于蛋白质的氨基酸序列预测其三维结构。在 CASP14 竞赛中,AlphaFold2 对 25 个蛋白质结构的预测准确率达到 92.4 分(满分 100),远超第二名的 65 分。
流体力学模拟:Google 的 SimNet 模型基于 Transformer 能精准模拟流体的流动状态,预测精度较传统数值方法提升 3 倍,计算时间从数天缩短至数小时,为天气预报、航空航天设计提供支持。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
五、 技术优化与扩展
5.1 计算复杂度分析与优化
Transformer 的标准自注意力机制存在计算复杂度高的问题,需要通过多种技术进行优化。
5.1.1 自注意力复杂度分析
Transformer 模型中的标准自注意力机制需要计算输入序列中每个 token 与其他所有 token 之间的关联,其计算和内存复杂度随序列长度呈平方级增长(O (n²))。
具体的复杂度分析如下:
-
自注意力的计算复杂度是 O (n²),长序列下矩阵乘法(QKV 计算)耗时占比超 70%
-
对于序列长度 n=4096,标准注意力需要约 1600 万次计算
-
内存需求同样是 O (n²),限制了可处理的序列长度
5.1.2 稀疏注意力机制
为了解决 O (n²) 复杂度问题,稀疏注意力机制应运而生。稀疏注意力通过有选择地关注关键位置,将计算复杂度降至线性或亚线性级别,同时保持模型性能。
稀疏注意力的类型:
固定稀疏模式:
-
局部窗口注意力:每个位置只关注固定大小窗口内的位置
-
分层注意力:将序列分成块,块内全连接,块间稀疏连接
可学习稀疏模式:
-
基于重要性的稀疏:动态选择最重要的位置进行关注
-
基于哈希的稀疏:通过局部敏感哈希将相似位置分组
混合模式:
-
BigBird:结合全局、局部和随机注意力
-
Longformer:滑动窗口 + 全局注意力
稀疏注意力的复杂度优势:
-
窗口大小为 k 的稀疏注意力:复杂度 O (n×k),当 k 为常数时,复杂度降至线性 O (n)
-
分层稀疏注意力:复杂度 O (n√n),显著优于 O (n²)
-
假设序列长度 n=4096,k=32:稀疏注意力只需要约 13 万次计算,计算量减少至约 0.8%,且实验表明模型性能几乎无损
5.1.3 线性注意力机制
线性注意力机制通过将 softmax 操作转换为线性操作,实现了真正的线性复杂度: 其中 ,
这种方法非常适合超长序列甚至无限长序列的处理。
5.1.4 Flash Attention 技术
Flash Attention 通过避免实例化巨大的注意力矩阵,利用 GPU 内存层次结构进行 IO 感知的精确计算,极大加速了标准注意力并降低了内存占用。
Flash Attention 的技术特点:
-
内存复杂度从 O (n²) 降至 O (n)
-
计算速度提升 2-4 倍
-
支持更大的序列长度
-
特别适合训练大模型时的注意力计算
5.2 模型压缩与推理优化
模型压缩技术旨在减小模型大小、降低计算复杂度,同时保持模型性能。
5.2.1 模型剪枝技术
剪枝是一种旨在降低神经网络计算冗余度的模型优化方法,其通过系统性剔除神经网络中的低效连接或冗余节点来实现架构精简。
剪枝类型:
结构化剪枝:
-
剪掉整个神经元、注意力头、甚至网络层
-
对硬件加速友好,能够直接减少计算单元
-
例如:移除不重要的注意力头,保留关键头
非结构化剪枝:
-
剪掉单个权重,产生稀疏矩阵
-
可以减少计算开销但不改变网络拓扑结构
-
需要专门的稀疏矩阵计算库支持
剪枝的核心原理:神经网络中 60% 以上连接权重接近 0,移除后精度损失 < 3%。
剪枝实现示例:
import torch
from torch.nn.utils import prune
# 假设有一个线性层
linear_layer = torch.nn.Linear(512, 512)
# 对权重进行L1范数剪枝,剪掉30%的权重
prune.l1_unstructured(linear_layer, name="weight", amount=0.3)
# 应用剪枝
prune.remove(linear_layer, "weight")
# 检查稀疏度
sparsity = (linear_layer.weight == 0).float().mean().item()
print(f"剪枝后稀疏度: {sparsity:.2%}")
5.2.2 量化技术
量化是通过降低数值精度来减少模型存储和计算需求的技术:
量化类型:
-
静态量化:在训练后进行量化,不需要重新训练
-
动态量化:在推理时动态进行量化
-
混合精度训练:在训练时使用混合精度,减少内存需求
量化的优势:
-
模型大小减少 2-4 倍
-
推理速度提升 2-4 倍
-
内存占用显著降低
-
可以与剪枝结合使用,获得 10-20 倍压缩率
PyTorch 量化示例:
import torch
from torch.quantization import quantize_dynamic
# 假设有一个模型
model = torch.nn.Sequential(
torch.nn.Linear(512, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 10)
)
# 动态量化模型
quantized_model = quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
# 测试量化模型
input_tensor = torch.randn(16, 512)
output = quantized_model(input_tensor)
print(f"量化模型输出形状: {output.shape}")
5.2.3 知识蒸馏
知识蒸馏是将大模型的知识迁移到小模型上的技术:
蒸馏过程:
-
使用预训练的大模型(教师模型)生成软标签
-
训练小模型(学生模型)同时拟合硬标签和软标签
-
软标签包含了大模型的知识,如类别之间的相似度
蒸馏的优势:
-
可以显著减少模型大小,同时保留原模型的性能
-
学生模型可以是更小的架构或相同架构的精简版本
-
能够提升小模型在某些任务上的性能
5.2.4 推理优化策略
推理优化的目标是提高模型的推理速度和效率:
推理优化技术:
-
图优化:通过优化计算图结构,消除冗余计算
-
批处理优化:提高批大小,充分利用硬件并行能力
-
内存优化:减少内存访问,使用更高效的数据结构
-
硬件加速:利用 GPU/TPU 的专用指令集
推理优化示例:
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
# 假设有一个模型
model = torch.nn.Sequential(...)
# 优化模型用于移动设备
optimized_model = optimize_for_mobile(model)
# 保存优化后的模型
torch.jit.save(optimized_model, "optimized_model.pt")
# 加载并测试
loaded_model = torch.jit.load("optimized_model.pt")
loaded_model.eval()
# 推理测试
input_tensor = torch.randn(1, 3, 224, 224)
with torch.no_grad():
output = loaded_model(input_tensor)
print(f"优化后模型推理时间: {time_taken:.4f}s")
5.3 训练技巧与超参数调优
成功的 Transformer 模型训练需要掌握各种训练技巧和超参数调优方法。
5.3.1 学习率调度策略
Transformer 采用 “线性预热 + 平方根衰减” 的学习率调度策略,公式为: 其中 是学习率的初始缩放因子,确保模型维度越大,初始学习率越小(避免维度大时参数更新幅度过大)。
学习率调度实现(完整代码)
def get_learning_rate(step, warmup_steps=4000, d_model=512):
"""计算学习率"""
if step < warmup_steps:
return (d_model ** -0.5) * (step / warmup_steps)
else:
return (d_model ** -0.5) * (step ** -0.5)
# 示例使用:生成学习率曲线并可视化
import matplotlib.pyplot as plt
total_steps = 20000 # 总训练步数
warmup_steps = 4000 # 预热步数
d_model = 512 # 模型维度
steps = list(range(1, total_steps + 1))
learning_rates = [get_learning_rate(step, warmup_steps, d_model) for step in steps]
# 绘制学习率曲线
plt.figure(figsize=(10, 6))
plt.plot(steps, learning_rates, label=f'warmup_steps={warmup_steps}, d_model={d_model}')
plt.axvline(x=warmup_steps, color='red', linestyle='--', label='End of Warmup')
plt.xlabel('Training Step')
plt.ylabel('Learning Rate')
plt.title('Transformer Learning Rate Schedule (Linear Warmup + Square Root Decay)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 实际训练中集成到优化器调度
class CustomLRScheduler(torch.optim.lr_scheduler.LambdaLR):
def __init__(self, optimizer, warmup_steps=4000, d_model=512, last_epoch=-1):
self.warmup_steps = warmup_steps
self.d_model = d_model
super().__init__(optimizer, self.lr_lambda, last_epoch=last_epoch)
def lr_lambda(self, step):
step += 1 # 避免step=0时计算错误
if step < self.warmup_steps:
return (self.d_model ** -0.5) * (step / self.warmup_steps)
else:
return (self.d_model ** -0.5) * (step ** -0.5)
# 初始化优化器和调度器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, betas=(0.9, 0.98), eps=1e-9)
lr_scheduler = CustomLRScheduler(optimizer, warmup_steps=4000, d_model=512)
# 训练循环中更新学习率
for epoch in range(num_epochs):
for batch in train_loader:
# 前向传播、计算损失、反向传播
loss.backward()
optimizer.step()
lr_scheduler.step() # 每步更新学习率
optimizer.zero_grad()
学习率调度的关键原理
-
线性预热阶段:在训练初期(前warmup_steps步),学习率从 0 线性增长到峰值。此阶段可避免模型在参数随机初始化时因高学习率导致的训练不稳定,给模型一个适应过程。例如,当warmup_steps=4000时,第 4000 步的学习率达到峰值(若基础学习率设为 1)。
-
平方根衰减阶段:预热结束后,学习率随步数的平方根反比例下降。这种衰减方式能确保训练后期学习率缓慢降低,让模型在收敛阶段仍能精细调整参数,避免因学习率骤降导致的收敛停滞。
-
模型维度适配:的引入体现了 Transformer 对模型维度的适配性 —— 当模型维度从 512 提升到 1024 时,初始学习率峰值会从约 0.044 降至 0.031,避免高维度模型参数更新幅度过大。
5.3.2 批次大小选择与梯度累积
批次大小(Batch Size)是影响 Transformer 训练效率和效果的核心超参数,需结合硬件资源和训练稳定性综合选择。
批次大小的核心影响
-
训练效率:更大的批次大小能充分利用 GPU 并行计算能力,减少训练轮次(Epoch)数。例如,在 8 张 V100 GPU 上,将批次大小从 32 提升到 128,单轮训练时间可从 2 小时缩短至 45 分钟(需确保 GPU 内存足够)。
-
训练稳定性:过小的批次(如 Batch Size=8)会导致梯度估计方差大,训练损失波动剧烈;过大的批次(如 Batch Size=256)可能导致梯度更新平滑但泛化能力下降,且易触发 GPU 内存溢出。
-
最佳实践范围:对于基础 Transformer 模型(如 Encoder-Decoder 结构,d_model=512),单 GPU 批次大小建议在 16-64 之间;若使用多 GPU 分布式训练,总批次大小(单 GPU 批次 ×GPU 数量)建议控制在 128-512,以平衡效率与稳定性。
梯度累积:解决小批次泛化问题
当硬件资源限制无法使用大批次时,可通过梯度累积(Gradient Accumulation) 模拟大批次训练效果:
def train_with_gradient_accumulation(model, train_loader, optimizer, criterion,
num_epochs, device, accum_steps=4):
"""带梯度累积的训练循环"""
model.train()
total_loss = 0.0
for epoch in range(num_epochs):
for batch_idx, (src, tgt) in enumerate(train_loader):
src, tgt = src.to(device), tgt.to(device)
# 前向传播
output = model(src, tgt[:, :-1])
loss = criterion(output.reshape(-1, output.size(-1)), tgt[:, 1:].reshape(-1))
# 梯度缩放(避免梯度爆炸)
loss = loss / accum_steps # 按累积步数均分损失
loss.backward() # 累积梯度,不立即更新参数
# 每accum_steps步更新一次参数
if (batch_idx + 1) % accum_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 梯度裁剪
optimizer.step()
optimizer.zero_grad() # 重置梯度
total_loss += loss.item() * accum_steps # 恢复真实损失值
# 打印日志
if (batch_idx + 1) % (accum_steps * 100) == 0:
avg_loss = total_loss / (batch_idx + 1)
print(f'Epoch {epoch+1}, Batch {batch_idx+1}, Avg Loss: {avg_loss:.4f}')
梯度累积的关键原理
-
核心逻辑:每accum_steps个小批次计算一次梯度并累积,累积完成后统一更新参数。例如,accum_steps=4且单批次大小 = 16 时,等效于批次大小 = 64 的训练效果。
-
注意事项:梯度累积时需将单次损失除以accum_steps,避免累积后梯度值过大;同时需配合梯度裁剪(Gradient Clipping),防止累积梯度爆炸。
5.3.3 正则化技术:防止过拟合
Transformer 模型参数规模大(基础模型约 60M 参数),易出现过拟合,需通过多重正则化技术提升泛化能力。
1. Dropout:随机失活冗余连接
Transformer 中 Dropout 主要应用于三个位置, dropout 概率建议设为 0.1-0.3:
class TransformerWithDropout(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8,
num_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
# 嵌入层Dropout
self.src_emb = nn.Sequential(
nn.Embedding(src_vocab_size, d_model),
nn.Dropout(dropout)
)
self.tgt_emb = nn.Sequential(
nn.Embedding(tgt_vocab_size, d_model),
nn.Dropout(dropout)
)
# 编码器层(含注意力和前馈网络Dropout)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward,
dropout=dropout, norm_first=True
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 解码器层(同理)
decoder_layer = nn.TransformerDecoderLayer(
d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward,
dropout=dropout, norm_first=True
)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
# 输出层
self.out = nn.Linear(d_model, tgt_vocab_size)
- 标签平滑(Label Smoothing):软化硬标签
传统独热编码标签(如 “猫” 对应 [1,0,0])易导致模型过度自信,标签平滑通过将真实标签概率从 1.0 降至 ,并将剩余概率分配给其他类别,提升泛化能力:
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self, num_classes, epsilon=0.1):
super().__init__()
self.num_classes = num_classes
self.epsilon = epsilon
def forward(self, logits, targets):
# logits: (batch_size*seq_len, num_classes), targets: (batch_size*seq_len)
log_probs = F.log_softmax(logits, dim=-1)
# 计算平滑标签
smooth_label = torch.full_like(log_probs, self.epsilon / (self.num_classes - 1))
smooth_label.scatter_(1, targets.unsqueeze(1), 1 - self.epsilon)
# 计算交叉熵损失
loss = -torch.sum(smooth_label * log_probs, dim=-1).mean()
return loss
# 实例化损失函数
criterion = LabelSmoothingCrossEntropy(num_classes=tgt_vocab_size, epsilon=0.1)
3. 梯度裁剪(Gradient Clipping):防止梯度爆炸
Transformer 训练中,深层网络易出现梯度爆炸,通过梯度裁剪将梯度范数限制在固定阈值内(通常为 1.0-5.0):
# 训练循环中添加梯度裁剪
for batch in train_loader:
# 前向传播与损失计算
loss = criterion(output, targets)
loss.backward()
# 梯度裁剪:将所有参数的梯度范数限制在max_norm内
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
optimizer.zero_grad()
5.3.4 参数初始化:提升训练收敛速度
Transformer 参数初始化需遵循 “避免初始值过大或过小” 原则,核心初始化方法如下:
1. 线性层与注意力层初始化
采用Xavier 均匀初始化(适用于激活函数为线性或 Sigmoid 的层),确保输入和输出的方差一致:
def init_transformer_weights(model):
"""Transformer模型参数初始化"""
for name, param in model.named_parameters():
if param.dim() > 1: # 仅对矩阵参数(如线性层权重)初始化
nn.init.xavier_uniform_(param)
else: # 对偏置项初始化为0
nn.init.constant_(param, 0.0)
# 注意力层特殊初始化:缩小Q/K/V投影层权重,避免点积过大
if 'self_attn' in name or 'multihead_attn' in name:
if 'weight' in name:
param.data *= 0.5 # 注意力层权重缩放因子
- 嵌入层初始化
嵌入层参数需与模型维度适配,建议采用正态分布初始化,标准差设为 :
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000, dropout=0.1):
super().__init__()
# 位置编码初始化
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
# 嵌入层初始化(正态分布)
self.emb_dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.tensor(d_model, dtype=torch.float)) # 嵌入缩放因子
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = x * self.scale # 嵌入缩放,避免初始值过小
x = x + self.pe[:, :x.size(1)] # 添加位置编码
return self.emb_dropout(x)
5.3.5 超参数搜索与调优实践
Transformer 超参数众多,需通过系统性搜索找到最优组合,常用方法如下:
1. 关键超参数及搜索范围
| 超参数 | 作用 | 推荐搜索范围 | 基础模型默认值 |
|---|---|---|---|
| d_model | 模型维度 | 256, 512, 1024 | 512 |
| nhead | 注意力头数 | 4, 8, 16 | 8 |
| num_layers | 编码器 / 解码器层数 | 3, 6, 12 | 6 |
| dim_feedforward | 前馈网络隐藏层维度 | 1024, 2048, 4096 | 2048 |
| dropout | Dropout 概率 | 0.1, 0.2, 0.3 | 0.1 |
| learning_rate | 初始学习率 | 1e-5, 5e-5, 1e-4 | 5e-5 |
| batch_size | 批次大小 | 16, 32, 64 | 32 |
2. 超参数搜索工具:Optuna
Optuna 是一款轻量级、灵活且高效的自动化超参数优化框架,其核心优势在于支持动态搜索空间调整、剪枝低效实验(Pruning)和分布式搜索,能大幅提升 Transformer 超参数搜索的效率与精度,尤其适用于模型训练成本高、超参数组合复杂的场景。
环境依赖与安装
在开展实践前,需先配置基础环境,安装 Optuna 及深度学习框架(以 PyTorch 为例):
# 安装 Optuna 核心库及可视化工具
pip install optuna optuna-dashboard
# 安装 PyTorch 及 Transformer 依赖(根据 CUDA 版本调整)
pip install torch torchvision torchaudio transformers datasets evaluate
机器翻译任务下的 Optuna 实现步骤
以英德机器翻译任务(使用 WMT14 数据集)为例,完整流程分为搜索空间定义、目标函数构建、搜索执行和结果分析四部分。
数据加载与预处理
首先使用 datasets 库加载 WMT14 英德数据集,并通过 transformers 进行 tokenization(以 T5Tokenizer 为例):
from datasets import load_dataset
from transformers import T5Tokenizer
# 加载 WMT14 英德机器翻译数据集(仅用训练集和验证集)
dataset = load_dataset("wmt14", "de-en", split=["train", "validation"])
train_dataset, val_dataset = dataset[0], dataset[1]
# 初始化 Tokenizer(适配 T5 基础模型)
tokenizer = T5Tokenizer.from_pretrained("t5-small")
max_seq_len = 128 # 可作为超参数,此处暂固定
# 数据预处理函数:将文本转换为模型输入格式
def preprocess_function(examples):
# 英德翻译:source 为英文("en"),target 为德文("de")
inputs = tokenizer(
examples["en"], max_length=max_seq_len, truncation=True, padding="max_length"
)
labels = tokenizer(
examples["de"], max_length=max_seq_len, truncation=True, padding="max_length"
)
inputs["labels"] = labels["input_ids"]
return inputs
# 应用预处理并转换为 PyTorch 张量格式
tokenized_train = train_dataset.map(preprocess_function, batched=True).with_format("torch", columns=["input_ids", "attention_mask", "labels"])
tokenized_val = val_dataset.map(preprocess_function, batched=True).with_format("torch", columns=["input_ids", "attention_mask", "labels"])
定义超参数搜索空间
通过 Optuna 的 trial 对象动态定义超参数搜索范围,与前文 “关键超参数及搜索范围” 对应:
def define_search_space(trial):
"""根据 trial 对象定义超参数搜索空间"""
return {
"d_model": trial.suggest_categorical("d_model", [256, 512, 1024]), # 模型维度
"nhead": trial.suggest_categorical("nhead", [4, 8, 16]), # 注意力头数
"num_layers": trial.suggest_categorical("num_layers", [3, 6, 12]),# 编码/解码层数
"dim_feedforward": trial.suggest_categorical("dim_feedforward", [1024, 2048, 4096]),# 前馈网络维度
"dropout": trial.suggest_categorical("dropout", [0.1, 0.2, 0.3]), # Dropout 概率
"learning_rate": trial.suggest_categorical("learning_rate", [1e-5, 5e-5, 1e-4]),# 初始学习率
"batch_size": trial.suggest_categorical("batch_size", [16, 32, 64])# 批次大小
}
构建目标函数(核心)
目标函数需完成模型初始化、训练配置、验证评估和剪枝优化,Optuna 通过最小化 / 最大化目标函数值(如验证集 BLEU 分数)筛选最优超参数:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from transformers import T5ForConditionalGeneration, AdamW, get_scheduler
import evaluate
import optuna
from optuna.pruners import MedianPruner
from optuna.samplers import TPESampler
# 加载 BLEU 评估指标(机器翻译任务核心指标)
bleu = evaluate.load("bleu")
def objective(trial):
# 1. 获取当前 trial 的超参数组合
params = define_search_space(trial)
# 2. 初始化 Transformer 模型(以 T5 为例,适配超参数)
model = T5ForConditionalGeneration.from_pretrained(
"t5-small",
d_model=params["d_model"],
nhead=params["nhead"],
num_layers=params["num_layers"],
dim_feedforward=params["dim_feedforward"],
dropout=params["dropout"]
).to("cuda" if torch.cuda.is_available() else "cpu") # 自动适配 GPU/CPU
# 3. 配置数据加载器(根据 batch_size 动态调整)
train_loader = DataLoader(tokenized_train, batch_size=params["batch_size"], shuffle=True)
val_loader = DataLoader(tokenized_val, batch_size=params["batch_size"], shuffle=False)
# 4. 配置优化器与学习率调度器
optimizer = AdamW(model.parameters(), lr=params["learning_rate"])
num_epochs = 3 # 固定训练轮次,也可作为超参数搜索
num_training_steps = num_epochs * len(train_loader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
# 5. 定义剪枝器(提前终止效果差的 trial,节省资源)
trial.set_user_attr("num_epochs", num_epochs)
pruner = MedianPruner(n_warmup_steps=num_training_steps // 5) # 预热后开始剪枝
# 6. 训练与验证循环
best_val_bleu = 0.0
for epoch in range(num_epochs):
# 6.1 模型训练
model.train()
total_loss = 0.0
for batch in train_loader:
batch = {k: v.to(model.device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
total_loss += loss.item() * batch["input_ids"].shape[0]
avg_train_loss = total_loss / len(train_loader.dataset)
trial.report(avg_train_loss, step=epoch) # 向 Optuna 报告训练损失
# 6.2 剪枝检查:若当前 trial 效果差,提前终止
if trial.should_prune():
raise optuna.TrialPruned()
# 6.3 模型验证(计算 BLEU 分数)
model.eval()
val_predictions = []
val_references = []
with torch.no_grad():
for batch in val_loader:
batch = {k: v.to(model.device) for k, v in batch.items()}
# 生成预测结果(使用贪心解码)
outputs = model.generate(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
max_length=max_seq_len
)
# 将 token ID 转换为文本
predictions = tokenizer.batch_decode(outputs, skip_special_tokens=True)
references = tokenizer.batch_decode(batch["labels"], skip_special_tokens=True)
val_predictions.extend(predictions)
val_references.extend([[ref] for ref in references]) # BLEU 要求参考文本为列表嵌套格式
# 计算验证集 BLEU 分数(目标:最大化 BLEU)
val_bleu = bleu.compute(predictions=val_predictions, references=val_references)["bleu"]
trial.report(val_bleu, step=epoch)
# 更新最优 BLEU 分数
if val_bleu > best_val_bleu:
best_val_bleu = val_bleu
return best_val_bleu # Optuna 以该值为目标进行优化(默认最小化,需指定方向)
执行超参数搜索
配置 Optuna 采样器、剪枝器和搜索参数,启动搜索任务,并支持实时可视化监控:
def run_hyperparameter_search():
# 1. 配置 Optuna 研究(Study):指定优化方向为最大化 BLEU
study = optuna.create_study(
study_name="transformer-mt-hp-search", # 研究名称
direction="maximize", # 优化方向(最大化 BLEU)
sampler=TPESampler(n_startup_trials=5),# 采样器(前 5 次随机探索,后续 TPE 采样)
pruner=MedianPruner(n_warmup_steps=10),# 剪枝器(预热 10 步后生效)
storage="sqlite:///transformer_hp.db" # 结果存储(SQLite 数据库,避免丢失)
)
# 2. 启动搜索:指定试验次数(根据资源调整,建议至少 30 次)
study.optimize(
objective,
n_trials=30,
show_progress_bar=True,
gc_after_trial=True # 每次试验后清理内存,避免 OOM
)
# 3. 输出搜索结果
print("\n=== 超参数搜索结果 ===")
print(f"最优试验编号: {study.best_trial.number}")
print(f"最优验证 BLEU: {study.best_value:.4f}")
print("\n最优超参数组合:")
for key, value in study.best_params.items():
print(f" {key}: {value}")
# 4. 保存最优超参数到 JSON 文件(后续模型训练直接调用)
import json
with open("best_hyperparameters.json", "w") as f:
json.dump(study.best_params, f, indent=4)
print("\n最优超参数已保存至 best_hyperparameters.json")
return study
# 启动超参数搜索(若已运行过,可通过 study = optuna.load_study(...) 加载结果)
if __name__ == "__main__":
study = run_hyperparameter_search()
搜索结果可视化与分析
使用 Optuna Dashboard 实时监控搜索过程,或通过内置函数分析结果:
# 启动 Optuna Dashboard,查看搜索进度与细节(浏览器访问 http://localhost:8080)
optuna-dashboard --storage sqlite:///transformer_hp.db
常用分析代码(绘制关键超参数与 BLEU 分数的关系):
import optuna.visualization as vis
# 1. 绘制超参数重要性(显示哪些超参数对 BLEU 影响最大)
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
# 2. 绘制单个超参数与目标函数的关系(如 d_model 与 BLEU)
fig_parallel = vis.plot_parallel_coordinate(study, params=["d_model", "nhead", "learning_rate"])
fig_parallel.show()
# 3. 绘制试验完成情况(包括剪枝的试验)
fig_optimization = vis.plot_optimization_history(study)
fig_optimization.show()
超参数调优进阶策略
两阶段搜索策略
考虑到 Transformer 训练成本高,可分粗搜和精搜两阶段优化:
-
粗搜阶段:使用较大的搜索范围(如增加 d_model=128、learning_rate=3e-5 等候选值)和较少的训练轮次(如 1-2 轮),快速筛选出潜力超参数区间;
-
精搜阶段:在粗搜最优区间内缩小步长(如 learning_rate=[3e-5, 5e-5, 7e-5]),增加训练轮次(如 5-10 轮),提升最优参数精度。
迁移学习与超参数初始化
若基于预训练 Transformer(如 BERT、T5)微调,可:
-
以预训练模型默认超参数(如 T5-base 的 d_model=768、nhead=12)为初始点,缩小搜索范围(如 d_model=[512, 768, 1024]);
-
固定部分对模型结构影响大的超参数(如 d_model、num_layers),仅搜索 dropout、learning_rate、batch_size 等微调敏感参数,降低搜索复杂度。
分布式搜索加速
当单卡训练效率低时,可通过 Optuna 支持的分布式搜索(多 GPU / 多机器)缩短时间:
# 分布式搜索配置(需确保所有节点共享同一数据库存储)
study = optuna.create_study(
storage="postgresql://user:password@host:port/dbname", # 改用 PostgreSQL 支持分布式
... # 其他参数不变
)
# 每个节点独立运行 study.optimize(...),Optuna 自动避免重复试验
实践注意事项
-
资源控制:Transformer 训练耗显存,需根据 GPU 显存调整 batch_size(如 16GB 显存最大支持 batch_size=32),必要时使用梯度累积(Gradient Accumulation);
-
评估稳定性:机器翻译的 BLEU 分数受解码策略(如 beam search vs 贪心解码)影响,建议固定解码参数(如 num_beams=4),避免评估偏差;
-
结果复现性:设置随机种子(torch.manual_seed(42)、optuna.set_seed(42)),确保最优超参数可复现;
-
过拟合检测:若训练损失持续下降但验证 BLEU 停滞,需增大 dropout 或减少 num_layers,避免模型过拟合。
六、如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
01.大模型风口已至:月薪30K+的AI岗正在批量诞生

2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
02.大模型 AI 学习和面试资料
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)






第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐

 15
15 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)