
大数据毕业设计Hadoop+Spark电影推荐系统 电影评论情感分析 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影数据分析 计算机毕业设计 深度学习 机器学习 人工智能 知识图谱
大数据毕业设计Hadoop+Spark电影推荐系统 电影评论情感分析 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影数据分析 计算机毕业设计 深度学习 机器学习 人工智能 知识图谱
| 基于Spark的电影推荐系统 | |||
| 角色 | 功能模块 | 具体功能 | 描述 |
| 用户 | 个人信息模块 | 注册 | 用户输入个人信息进行注册 |
| 登录 | 用户通过输入账号和密码完成系统登录 | ||
| 修改密码 | 用户通过获取短信验证码来修改密码 | ||
| 修改个人信息 | 用户能修改如昵称、生日等个人信息 | ||
| 修改喜好信息 | 用户能修改自己的电影分类喜好信息 | ||
| 电影信息模块 | 电影搜索 | 用户能通过输入电影名、电影分类、评分区间、导演名、演员名等来搜索相关影片 | |
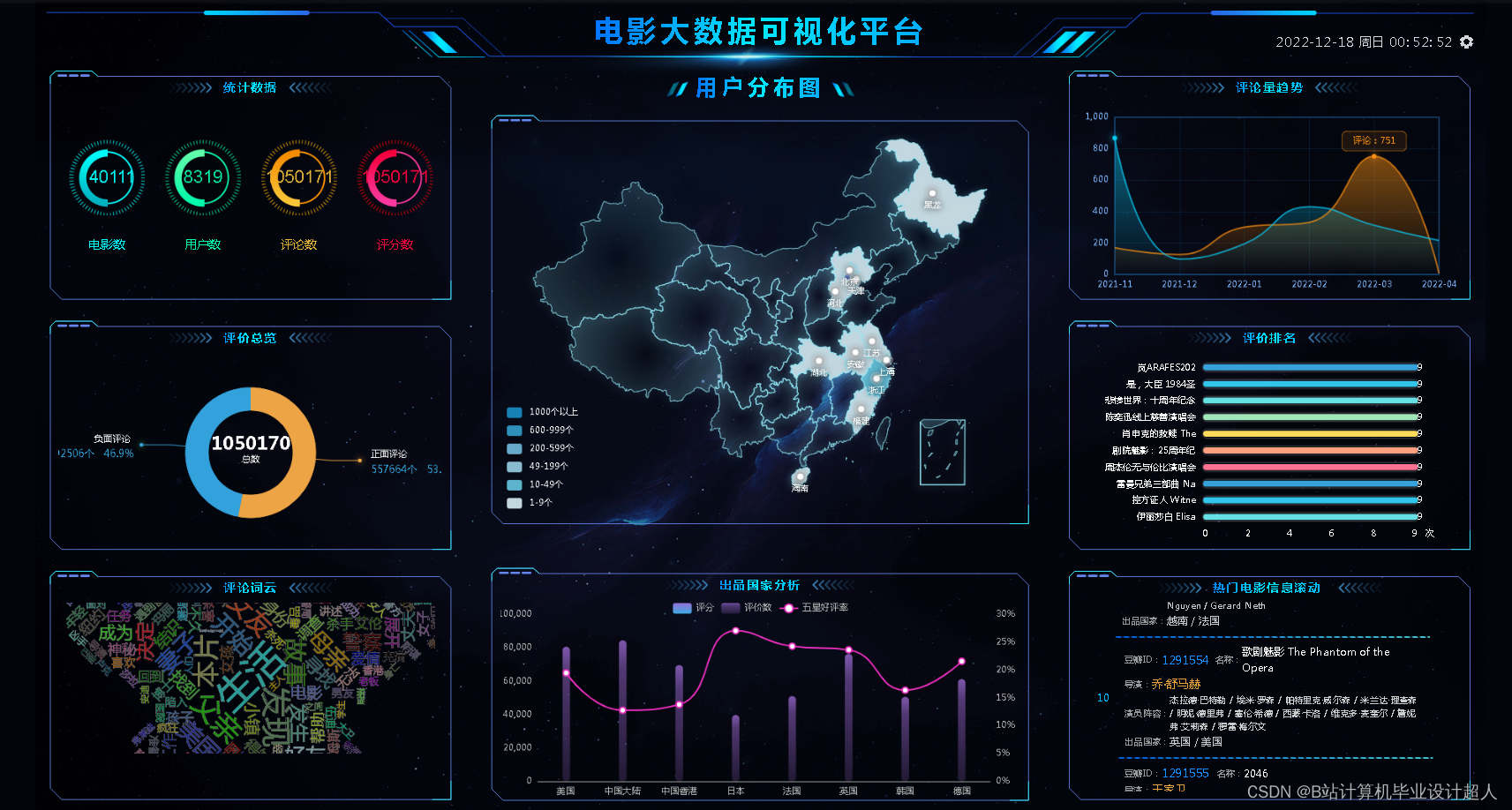
| 电影详情 | 1.用户能获取电影基本信息,如简介、演员列表、上映时间等; 2.用户能获取评分信息和其他用户的评论; 3.用户能获取该影片的剧照信息; | ||
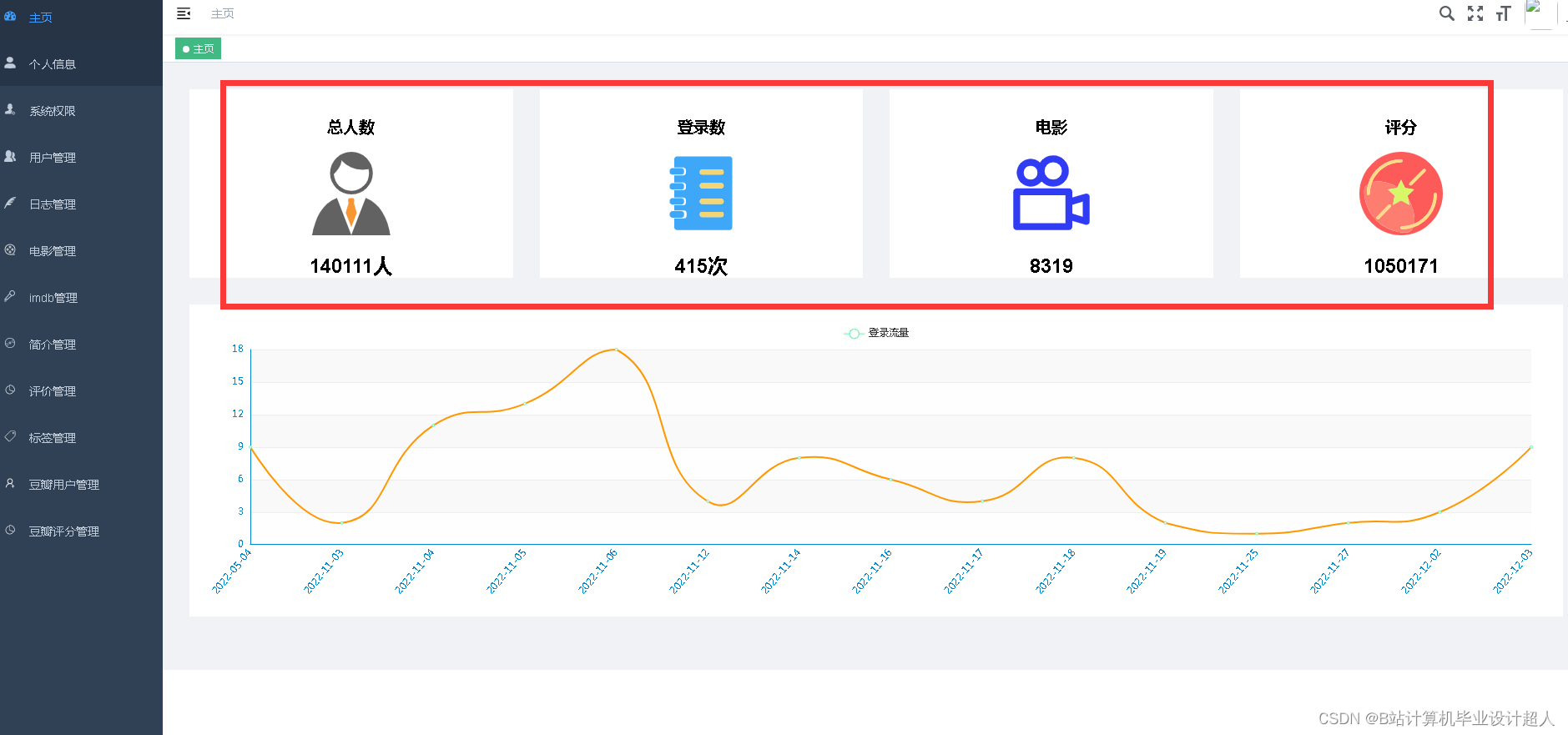
| 用户画像分析 | 用户可以获取对该影片有过评价的其他用户的评分分布图表、性别分布图表、年龄分布图表等 | ||
| 评分评论 | 用户可以对任意影片进行评分和评论、系统会据此作为推荐依据 | ||
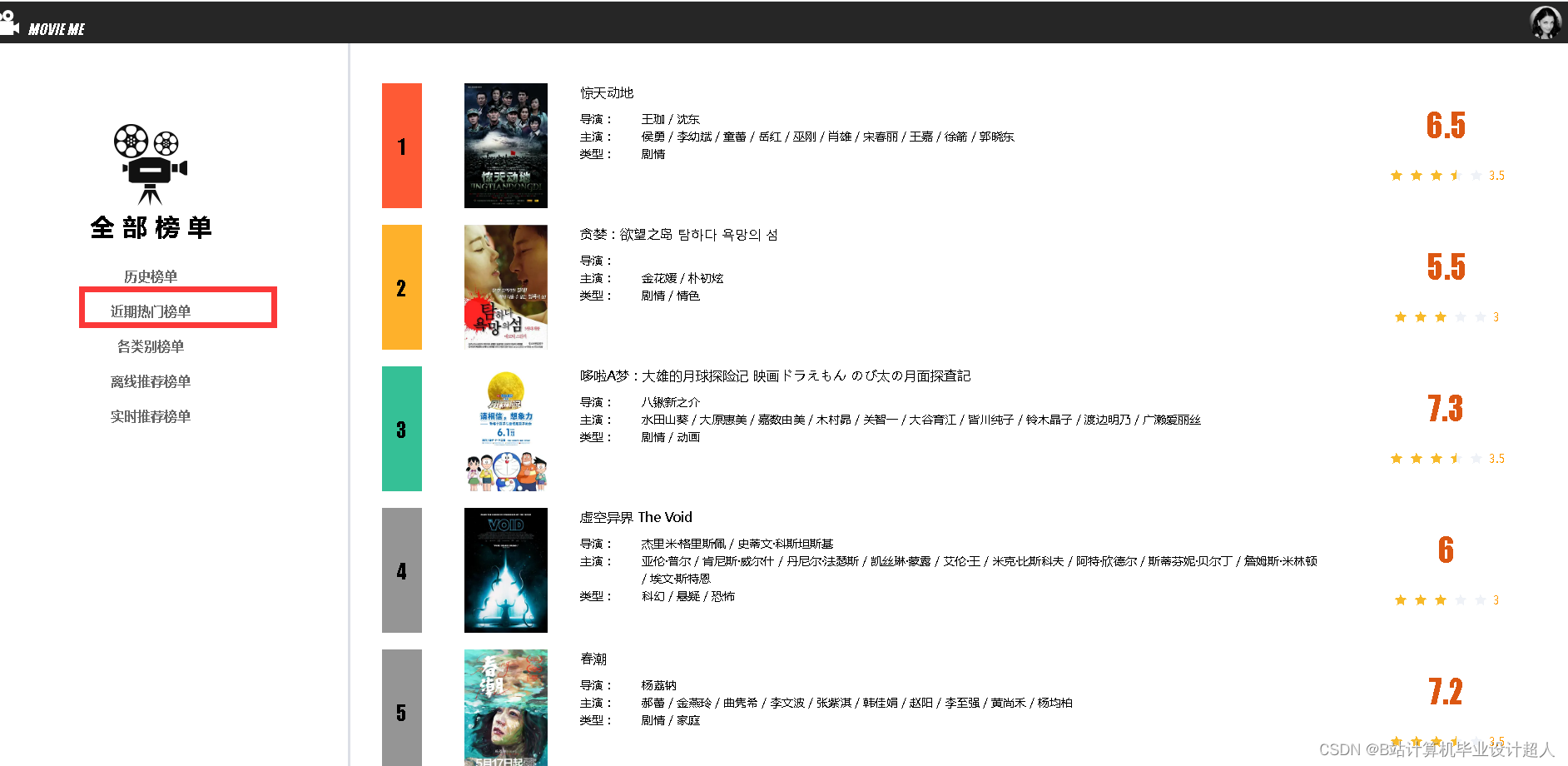
| 电影推荐模块 | 统计推荐 | 1.用户能获取电影历史热门榜单; 2.用户能获取近期的电影热门榜单; 3.用户能获取各个分类电影热门榜单 | |
| 相似电影推荐 | 用户能获取和某一电影内容或分类相似的影片 | ||
| 个性化推荐 | 根据用户之前选择的喜好电影分类标签和历史评论信息,推荐用户感兴趣的电影 | ||
部署环境配置表
| CPU | AMD EPYC 7K62 48-Core Processor |
| 内存 | 8GB |
| 硬盘 | 100GB |
| 操作系统 | CentOS Linux release 7.9.2009 (Core) |


































 以下是一个简单的使用 TensorFlow 的电影推荐系统示例代码,基于协同过滤算法:
以下是一个简单的使用 TensorFlow 的电影推荐系统示例代码,基于协同过滤算法:
import tensorflow as tf
import numpy as np
# 创建示例用户-电影评分数据
ratings = np.array([
[3.0, 1.0, 2.0, 0.0],
[4.0, 0.0, 1.0, 5.0],
[1.0, 0.0, 5.0, 2.0],
[2.0, 5.0, 0.0, 3.0]
])
# 构建协同过滤模型
input_layer = tf.keras.layers.Input(shape=(4,))
embedding_layer = tf.keras.layers.Embedding(input_dim=5, output_dim=3)(input_layer)
flatten_layer = tf.keras.layers.Flatten()(embedding_layer)
dense_layer = tf.keras.layers.Dense(10, activation='relu')(flatten_layer)
output_layer = tf.keras.layers.Dense(4)(dense_layer)
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(ratings, ratings, epochs=50, verbose=0)
# 预测电影评分
user_id = 0
movie_id = 3
user_ratings = np.array([[3.0, 1.0, 2.0, 0.0]])
predicted_ratings = model.predict(user_ratings)
print(f"预测用户 {user_id} 对电影 {movie_id} 的评分为: {predicted_ratings[0][movie_id]}")
在这段代码中,我们首先创建了一个简单的用户-电影评分矩阵作为示例数据。然后,我们使用 TensorFlow 构建了一个基于协同过滤的推荐系统模型,包括嵌入层、全连接层等组件,并使用均方误差作为损失函数进行训练。最后,我们输入一个用户的评分数据,利用训练好的模型预测用户对指定电影的评分。
这只是一个简单的示例,实际的电影推荐系统可能会使用更复杂的算法和模型,同时需要更多的数据和特征工程来提高推荐的准确性和个性化程度。
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)