
大数据毕业设计Python+Django+Hadoop+Spark中药可视化 中药材可视化 中药资讯可视化 中药知识图谱 中药推荐系统 计算机毕业设计 机器学习 深度学习 知识图谱 人工智能
大数据毕业设计Python+Django+Hadoop+Spark中药可视化 中药材可视化 中药资讯可视化 中药知识图谱 中药推荐系统计算机毕业设计 机器学习 深度学习 知识图谱 人工智能
·
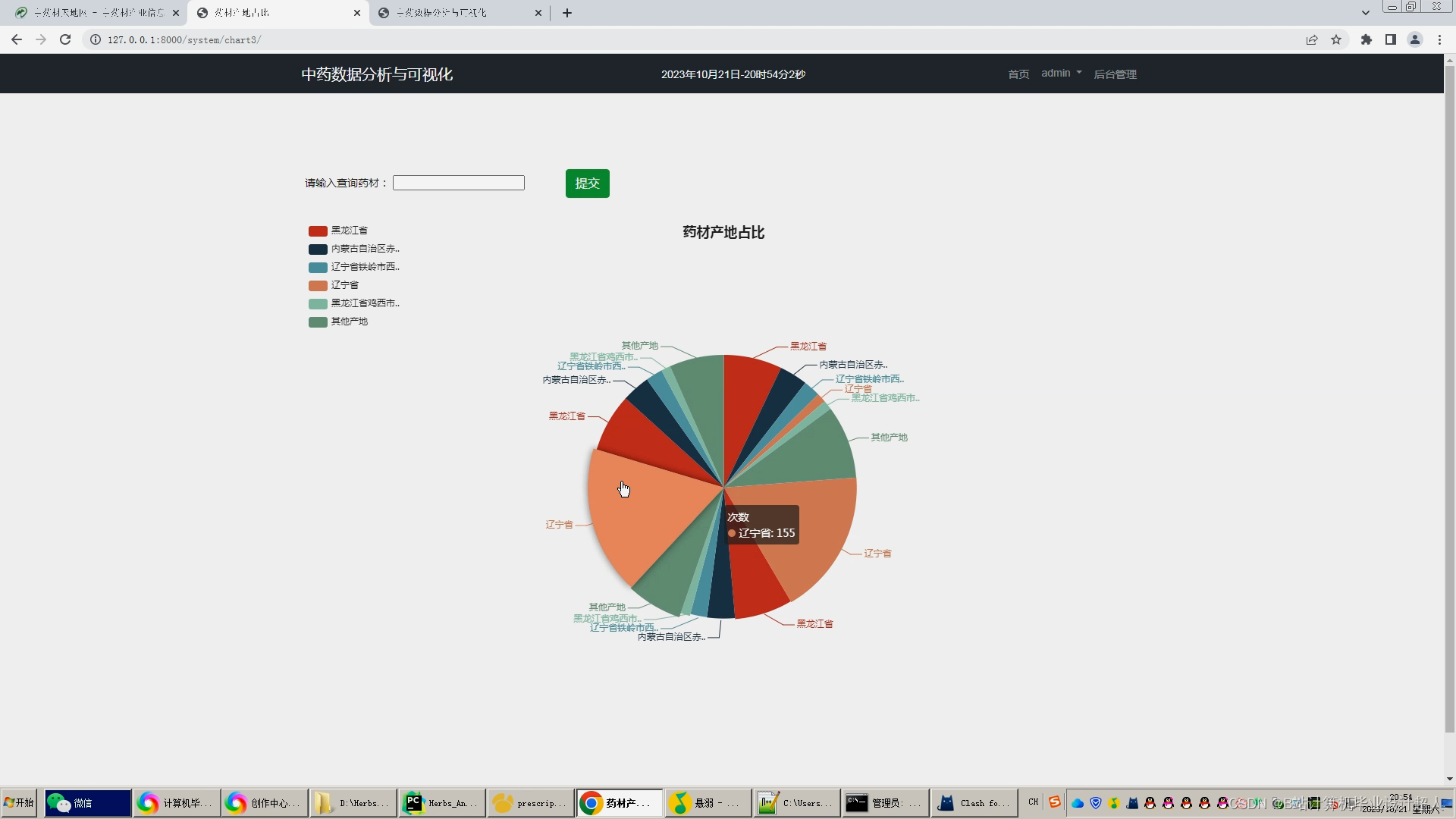
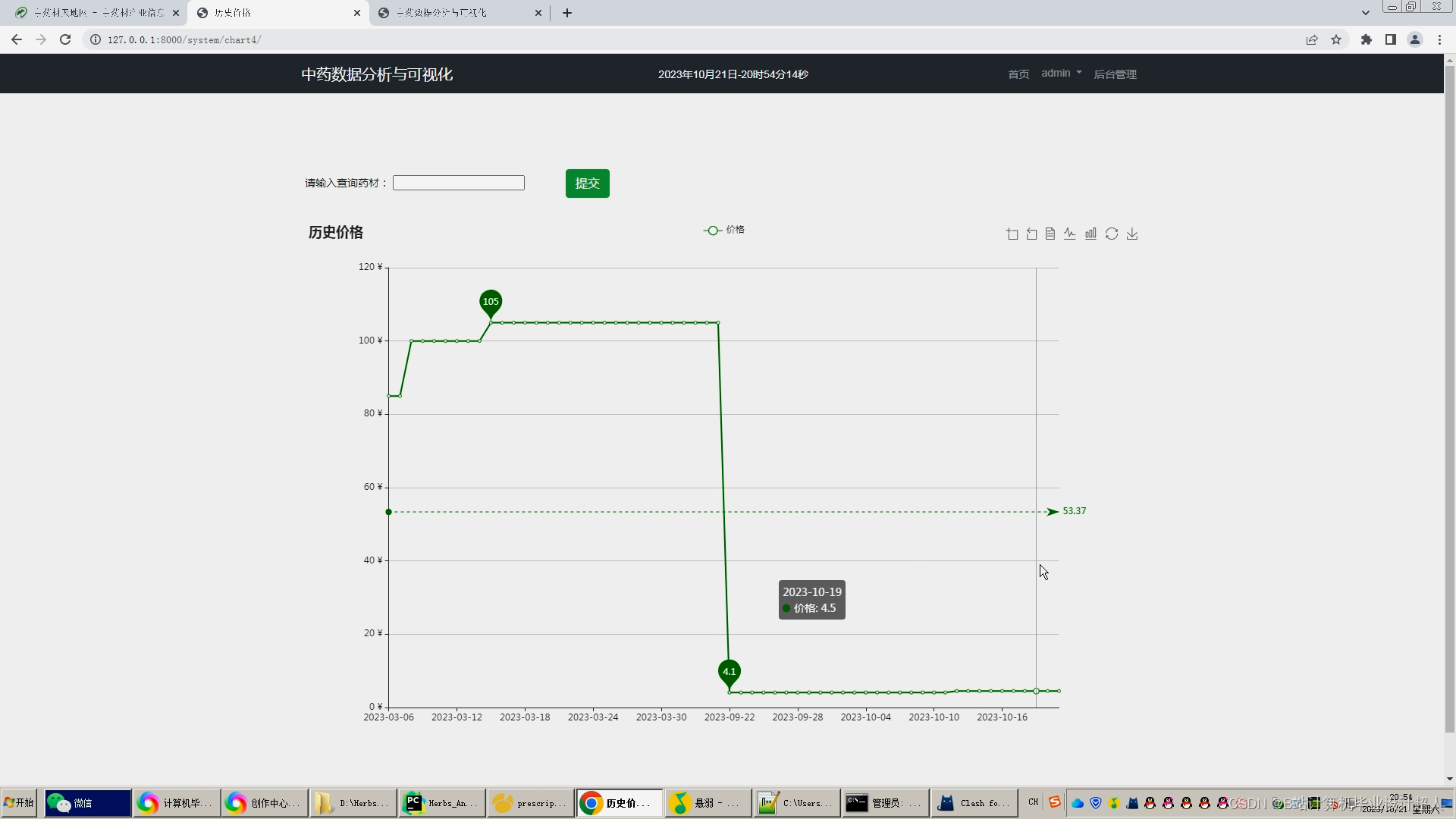
这次分享药材数据可视化系统的设计与实现,主要针对各类药材数据做一个统计分析可视化。
Django+爬虫+Hadoop、Spark数据清洗与可视化
数据库:MySQL
Python版本:3.7
Django版本:4.2.2




import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 加载中药数据集
data = pd.read_csv('chinese_medicine.csv')
# 使用TF-IDF向量化中药功效描述
tfidf = TfidfVectorizer(stop_words='chinese')
tfidf_matrix = tfidf.fit_transform(data['efficacy'])
# 构建推荐系统数据集
X = tfidf_matrix.toarray()
y = data['target_variable']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 使用模型进行预测
predictions = model.predict(X_test)
# 示例输出
print(predictions)
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)