- @zxc18344522713
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
产品经理让你在页面加一个 AI 助手对话窗,你说要能流式返回、能处理多轮对话、能优雅地处理报错。结果你发现 Node.js 后端要自己解析 SSE 流、写工具调用逻辑、管多轮上下文。前端写界面只要半小时,自己搭后端花了两天。开始用了 OpenAI,老板说成本太高要切换成 Anthropic Claude,后来又说要把部分简单请求切到通义千问。每个模型的 SDK 接口、Token 统计、消息格式都不

产品经理让你在页面加一个 AI 助手对话窗,你说要能流式返回、能处理多轮对话、能优雅地处理报错。结果你发现 Node.js 后端要自己解析 SSE 流、写工具调用逻辑、管多轮上下文。前端写界面只要半小时,自己搭后端花了两天。开始用了 OpenAI,老板说成本太高要切换成 Anthropic Claude,后来又说要把部分简单请求切到通义千问。每个模型的 SDK 接口、Token 统计、消息格式都不
浏览器插件开发,对 AI 编程新手来说,是一个很好的练习方向。它足够小,容易开始。它又足够真实,可以上架或者直接发压缩包让别人安装使用。

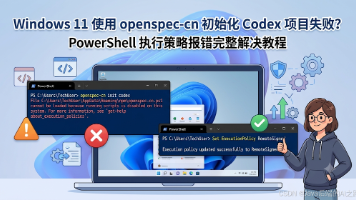
最近在 Windows 11 上使用初始化项目时,很多人会遇到一个非常典型的问题:命令明明已经安装好了,但一执行就报红,而且错误信息里出现了无法加载文件等字样。openspec-cn : 无法加载文件 C:\Users\evan\AppData\Roaming\npm\openspec-cn.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https://go.microsoft.com
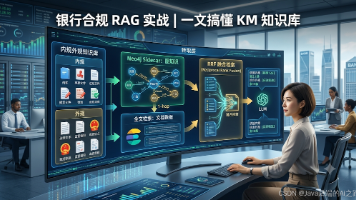
做过银行合规 / 监管科技项目的同学,大概率踩过这个坑:向量检索明明命中了《反洗钱管理办法》,却漏掉了外规里点名引用的《客户尽职调查实施细则》——不是文档没入库,是**「谁引用谁、谁约束谁」这条链,系统里根本没有**。我们团队在做AI 合规审查平台的 KM(Knowledge Management)模块演进时,从「能存能搜」走向「能连能溯」,中间一堆术语——内规外规、Phase 1、1-hop、N
当大模型在2024-2026年席卷整个AI行业时,一个被忽视的问题正在悄然浮现:大模型“幻觉”依然是企业级AI应用的最大拦路虎。据相关研究显示,传统ChatGPT-4在临床问答上的准确率仅为37%,即使是最先进的DeepSeek-R1也仅能达到52%。但当引入基于知识图谱的GraphRAG框架后,准确率飙升至98%,幻觉率从63%骤降至1.7%。这组数据揭示了一个关键事实:知识图谱正在从“技术冷门

当大模型在2024-2026年席卷整个AI行业时,一个被忽视的问题正在悄然浮现:大模型“幻觉”依然是企业级AI应用的最大拦路虎。据相关研究显示,传统ChatGPT-4在临床问答上的准确率仅为37%,即使是最先进的DeepSeek-R1也仅能达到52%。但当引入基于知识图谱的GraphRAG框架后,准确率飙升至98%,幻觉率从63%骤降至1.7%。这组数据揭示了一个关键事实:知识图谱正在从“技术冷门
当大模型在2024-2026年席卷整个AI行业时,一个被忽视的问题正在悄然浮现:大模型“幻觉”依然是企业级AI应用的最大拦路虎。据相关研究显示,传统ChatGPT-4在临床问答上的准确率仅为37%,即使是最先进的DeepSeek-R1也仅能达到52%。但当引入基于知识图谱的GraphRAG框架后,准确率飙升至98%,幻觉率从63%骤降至1.7%。这组数据揭示了一个关键事实:知识图谱正在从“技术冷门
浏览器插件开发,对 AI 编程新手来说,是一个很好的练习方向。它足够小,容易开始。它又足够真实,可以上架或者直接发压缩包让别人安装使用。
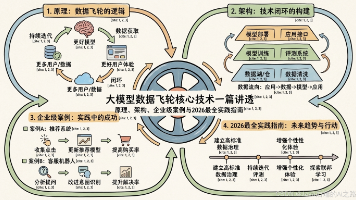
大模型数据飞轮核心技术解析与实践指南 本文系统剖析了大模型时代的数据飞轮技术体系,通过四大典型场景揭示了当前AI应用面临的核心困境:模型性能衰退、迭代周期过长、场景适配性差和成本失控问题。数据飞轮作为解决方案,通过"数据-模型-用户-反馈"的正向循环机制实现自我增强。 文章详细阐述了数据飞轮的四大构建层次(业务闭环、数据采集、模型训练和在线推理)和MAPE控制循环(监控、分析、