




- @zj_18706809267
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
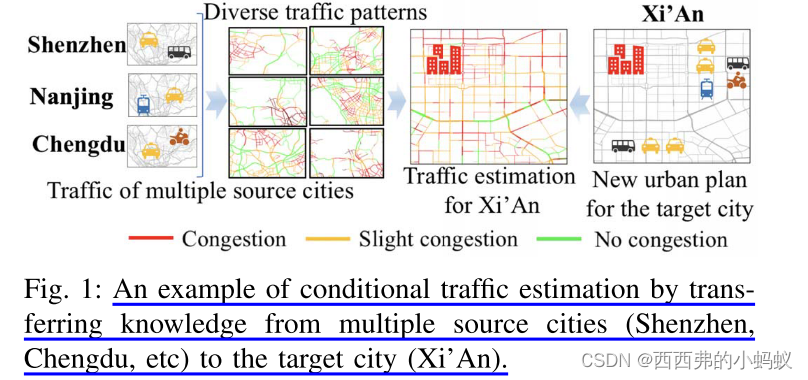
What is the Human Mobility in a New City: Transfer Mobility Knowledge Across Cities随着物联网的发展,车辆、共享单车和移动设备的GPS轨迹反映了人们的出行模式和偏好,这对城市规划、企业选址等城市应用尤为重要。然而,由于隐私和商业方面的考虑,以及部署传感器的高成本和收集数据的长时间等因素,收集大量的人类移动数据并不容易
此外,提出了一种高效的分治算法来推导两个语义轨迹之间的空间相似度边界和文本相似度边界,使我们能够在不计算空间-文本相似度精确值的情况下剪枝不相似的轨迹对。其次,与传统的使用昂贵的黎曼梯度的双曲嵌入方法相比,该方法可以以更高效的方式进行优化。具体地,针对τi和τj中的不足,提出了轨迹对剪枝策略,剪枝"不合格"的轨迹对,而不需要计算每个对象对之间的相似度。然而,之前基于图的方法将GNN应用于构建的连通
具体而言,首先设计了一个空间依赖模块来建模交通流内部的各种空间相关性,其中首先构建了多关系图来从多个角度考虑相关性,然后提出了一个多图卷积神经网络来捕获交通流的综合空间依赖并充分传播观测到的交通值,以缓解空间域数据稀疏问题。同时,为了解决时间连续数据缺失问题,采用改进的双向循环神经网络同时考虑历史和未来信息来捕获交通流的时间依赖关系,并采用时间衰减机制来控制相邻时间片之间信息的不规则传递。在真实数
直观地说,一条边的特征依赖于它的属性,如道路的连通性和节点之间的距离。为了对全市交通进行建模,受对交通缺失模式和先验知识的观察启发,提出了一种神经记忆和泛化方法来推断缺失的速度和流量,主要由一个用于速度推理的记忆模块和一个用于流量推理的泛化模块组成。基于三个真实的数据集进行了广泛的实验,以说明ST-MetaNetþ超越几种最先进的方法的有效性。城市交通预测对智能交通系统和公共安全具有重要意义,但具
具体而言,首先设计了一个空间依赖模块来建模交通流内部的各种空间相关性,其中首先构建了多关系图来从多个角度考虑相关性,然后提出了一个多图卷积神经网络来捕获交通流的综合空间依赖并充分传播观测到的交通值,以缓解空间域数据稀疏问题。同时,为了解决时间连续数据缺失问题,采用改进的双向循环神经网络同时考虑历史和未来信息来捕获交通流的时间依赖关系,并采用时间衰减机制来控制相邻时间片之间信息的不规则传递。在真实数
这样,我们的方法只需要对所有区域对之间的𝑀2相关性进行建模1,其中通常𝑀≪𝑁。此外,提出一种基于矩阵分解的元学习器,使细胞对随时间变化的外部因素产生特异性响应。实验结果表明,与目前最先进的方法相比,STRN在使用更少参数的情况下,误差降低了7.1% ~ 11.5%。此外,我们还部署了一个名为UrbanFlow 3.0的云系统,以展示该方法的实用性。本文将城市流量预测的视野扩展到细粒度,提出了
直观地说,一条边的特征依赖于它的属性,如道路的连通性和节点之间的距离。为了对全市交通进行建模,受对交通缺失模式和先验知识的观察启发,提出了一种神经记忆和泛化方法来推断缺失的速度和流量,主要由一个用于速度推理的记忆模块和一个用于流量推理的泛化模块组成。基于三个真实的数据集进行了广泛的实验,以说明ST-MetaNetþ超越几种最先进的方法的有效性。城市交通预测对智能交通系统和公共安全具有重要意义,但具
由此产生的模型名为FLASH3,与改进的transformer在短(512)和长(8K)上下文长度上的困惑度相匹配,在自回归语言建模方面,在Wiki-40B上实现了高达4.9倍的训练加速,在PG-19上实现了12.1倍的训练加速,在掩码语言建模方面在C4上实现了4.8倍的训练加速。结果表明,所提出方法可以以最小的微调成本实现更高的压缩比,并产生出色的和有竞争力的性能。值得注意的是,具有特征集成的N
基本思想我们尝试了RL中最经典的Qlearning和DQN模型,但这两种方法都未能解决高维空间(数据库状态,knobs组合)和连续动作(连续knobs)的问题。此外,作为RL的灵魂,奖励函数(rewardfunction,RF)的设计至关重要,直接影响模型的效率和质量。接下来,我们将展示如何调整蒙特卡洛树搜索(MCTS),这是一种流行的RL技术,不需要显式地表示整个状态/动作空间[14],以解决可
强化学习概述 其中网络根据 输入选择不同的网络结构 CNN ,RNN ,或者transformer在return最大的约束下,找到Actor中network的参数,满足这个约束,使得R越大越好。但是network训练过程中存在大量的随机性,导致训练困难。RL类似GAN,可以将Actor看成GAN中的Generater;把Reward和环境 看成discriminater。RL只能通过梯度法优化Ac