




- @zhulong1984
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近项目开发涉及了一些AI算法移植到边缘计算盒子上,调研了寒武纪MLU220、比特大陆SM5和华为310的模组,对相关的资料进行整理工作,理论上来说比特大陆SM5的移植还算比较友好一些。
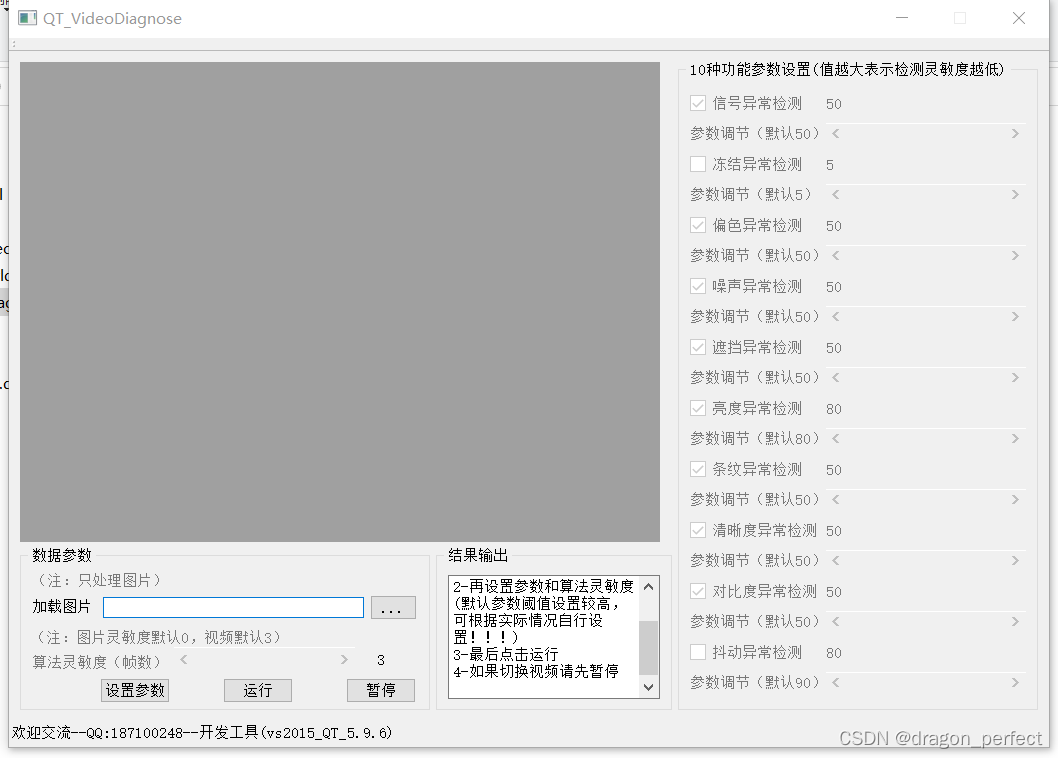
传统的视频质量诊断算法已经满足不了多数项目的需求,需要结合深度学习的方式来综合判断,达到提升精度的目的,深度学习视频诊断。
Yolov8 Opencv C++系列保姆教程,通过一个红绿灯识别的案例,实现了Yolov8 的应用全流程的过程,整个算法最终只依赖了opencv,部署会更加方便、易用。基于Yolov8训练自己的数据集,实现红绿灯识别及红绿灯故障检测 ,红绿灯故障识别。
本文针对无人机在船舶上的自动降落问题,提出了一套完整的算法设计方案。系统采用多线程架构,分别设置 30ms 导引线程、60ms 船位线程与 50ms 状态发布线程,通过共享状态、非阻塞队列及互斥锁机制实现线程间安全通信,保证系统实时性与运行稳定。核心制导算法基于 ZEM/ZEV 原理设计,可实现无人机在有限时间内精准趋近船舶并将相对速度降至零,满足平稳降落要求。为贴合海上实际环境,采用 Ornst

本项目作为一个小科研课题,分析当前电梯禁入电动车和自行车监控情况,搜集市场上的一些关键性,且有用的数据集,并对数据集进行了标注工作,数据集的格式声明:数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)。

Yolov8 Opencv C++系列保姆教程,通过一个红绿灯识别的案例,实现了Yolov8 的应用全流程的过程,整个算法最终只依赖了opencv,部署会更加方便、易用。基于Yolov8训练自己的数据集,实现红绿灯识别及红绿灯故障检测 ,红绿灯故障识别。
安装完系统后,直接ALT+CTRL+F1,进入超级终端模式,之后先安装显卡的驱动,之后再安装cuda,然后所有的应用都可以继续安装了。
传统的视频质量诊断算法已经满足不了多数项目的需求,需要结合深度学习的方式来综合判断,达到提升精度的目的,深度学习视频诊断。
一、采用yolo v3来对火焰进行检测:网址:https://github.com/AlexeyAB/darknet二、yolo v3 训练方式请参考,https://blog.csdn.net/zhulong1984/article/details/82344685;三、训练的部分数据,链接:https://pan.baidu.com/s/1spcwJrK0eMwgHXkslImUg...
将adoc文件转换为markdown的方法:首先安装工具(pandoc和asciidoc),然后分两步转换格式(先转为docbook再转markdown)。可能需处理Unicode编码问题,转换后需手动调整格式。若遇到Python缺少asciidoc模块的错误,可通过系统包管理器或pip安装解决。转换过程会保留大部分文档结构,但最终效果可能需要进一步优化。