- @zhangkai950121
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,
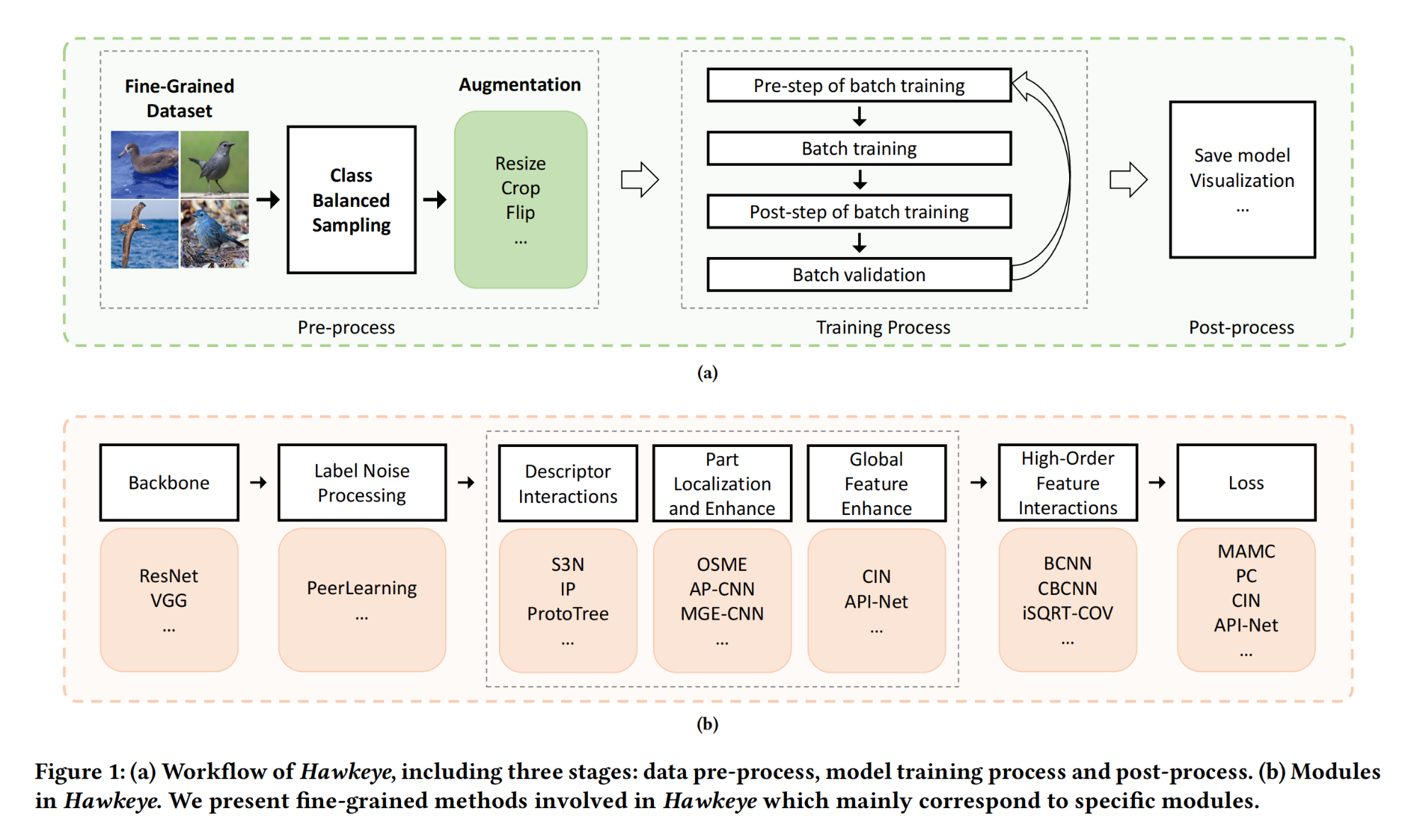
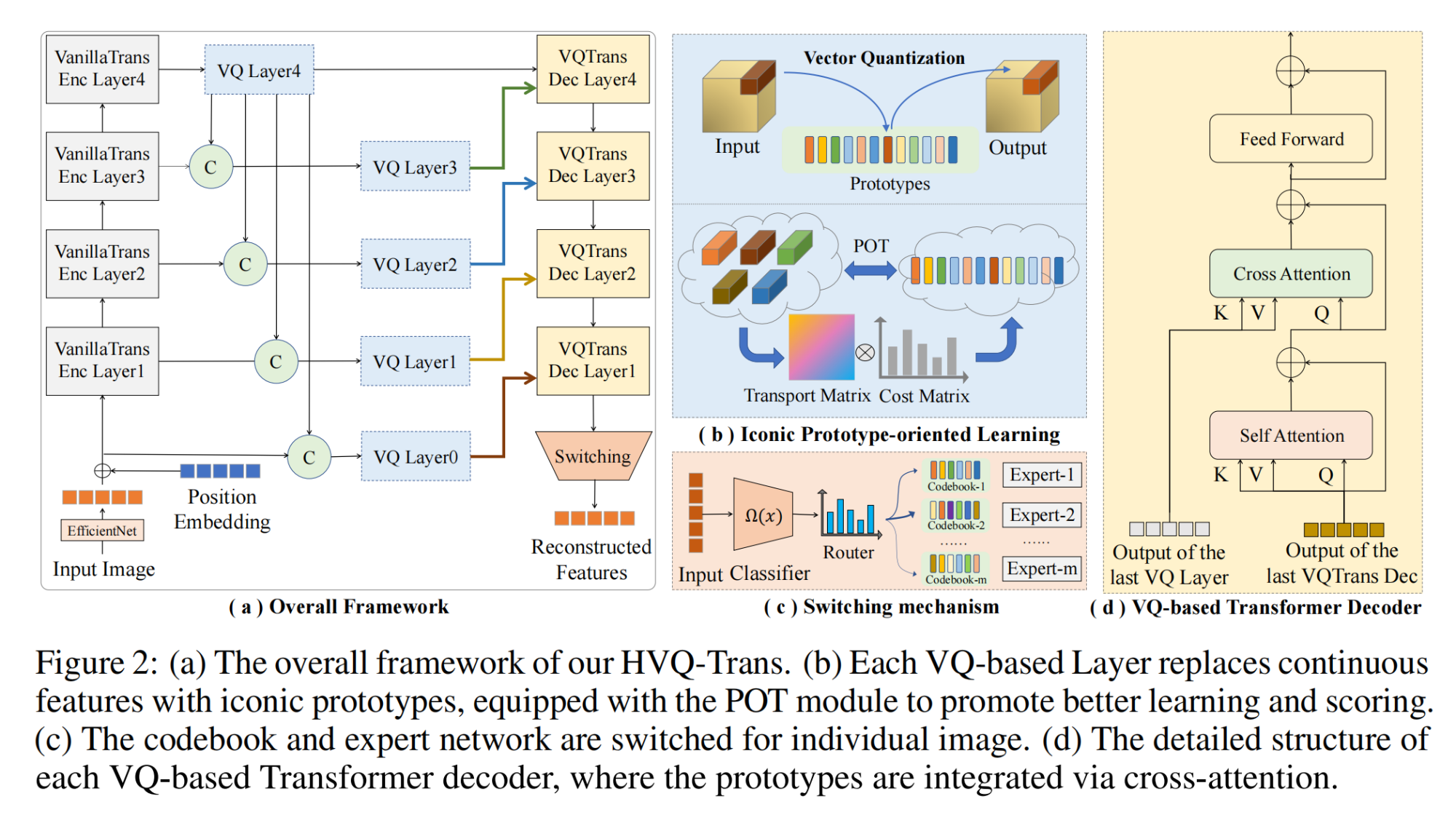
8.【自动驾驶:多任务】LeTFuser: Light-weight End-to-end Transformer-Based Sensor Fusion for Autonomous Driving with Multi-Task Learning。7.【自动驾驶:BEV】EarlyBird: Early-Fusion for Multi-View Tracking in the Bird's

群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,
最近准备推出一系列Python入门、Pytorch深度学习框架入门的文章,主要面向计算机视觉小白。为了给非计算机专业的读者、或者刚入门计算机视觉的读者打好基础,前几天特意写了一篇入门文章,介绍了计算机视觉中一些最基础的概念和名词:Here is yuque doc card, click on the link to view:https://www.yuque.com/zhangkai-bazw

群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,
今天和大家分享一篇ECCV2020中关于目标检测失效分析工具的文章。文章标题:TIDE: A General Toolbox for Identifying Object Detection Errors文章下载地址:https://arxiv.org/abs/2008.08115代码下载地址:https://dbolya.github.io/tide/动机在目标检测和实例分割任务中,通常以mAP
3.【基础网络架构:CNN】UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition。11.【行人重识别】(TIFS2023)Video-based Visible-Infrared Person Re-Ident
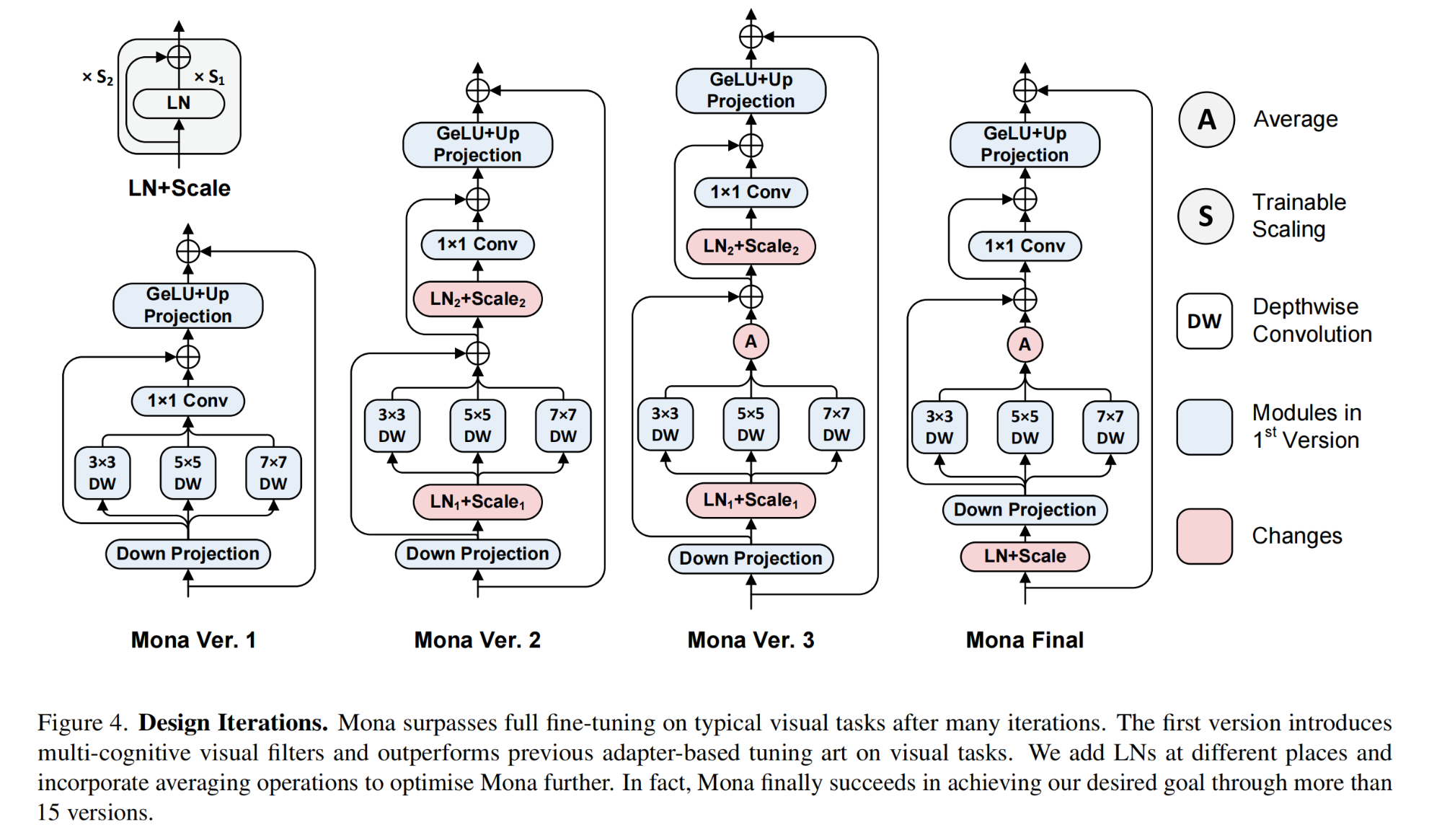
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,
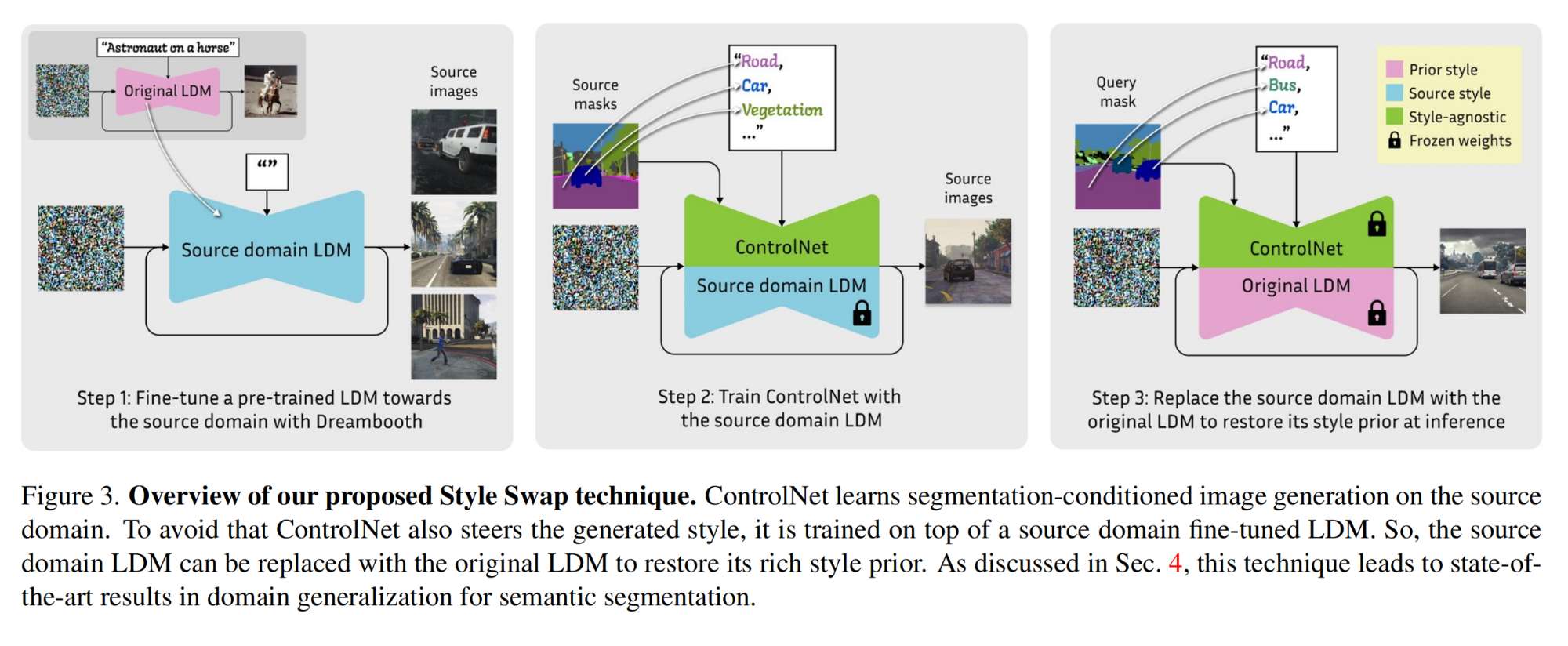
3.【医学图像分割:3D】Assessing Test-time Variability for Interactive 3D Medical Image Segmentation with Diverse Point Prompts。8.【多模态】One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Ge
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,11.【多模态】Hall