




- @zengxiaojian2
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
硬件配置方面,夸父人形机器人目前可选 4 代和 4 Pro 版本,拥有 30 自由度,配备双目深度摄像头,可选激光雷达,身高最高 1660mm。关注全球机器人动向,提供最新机器人行业资讯,致力于推动机器人技术及产业蓬勃发展!华为开发者大会 ,搭载华为云盘古具身智能大模型。时隔四个月,该机器人上新了。本文仅用于知识和学术分享,版权属于原作者,若有侵权,请联系删除。三方开发平台接入、开发辅助工具、仿真

系统的核心部分有它的既得利益,没有足够的动力去颠覆自己的利益来创新,而在系统边缘,一个好的想法被尝试,然后经历失败再不断的尝试,不确定性会变低,成功的概率就会变大,如果它足够重要,就会产生颠覆性的创新。今天的波音客机就是根据此原则来设计控制器的,它能对油量的变化造成的飞机重量变化,高空中气流的变化等等都保持有效,这也是民航客机能够安全运行,我们放心坐上去的保证,所以基于模型的控制是十分有效的,只不

我们这支集合工业界老兵和高密度科学家的战队,拥有完整的技术栈,将在具身智能的前沿打造软硬一体的综合解决方案,拓展在先进制造,商超物流及2B服务业等场景中的应用场景,快速实现数据闭环,商业化落地。业切入,以头部客户的高价值场景需求为指引,开发整合技能集,实现商业落地,并快速迭代硬件,算法,数据系统,不断提升具身智能整体解决方案的泛化性,灵巧性和成功率,给出具身领域“不可达三角”的最优解。地的全能团队

他们进一步开发了多 agent 框架 LearnAct,其能够自动从演示中提取知识,从而提高任务完成度,集成了三个专业 agent:用于知识提取的 DemoParser、用于相关知识检索的 KnowSeeker 和用于演示增强任务执行的 ActExecutor。实验结果表明,在离线和在线评估中,模型性能都有显著提高。通过实证分析,来自香港科技大学和蚂蚁集团的研究团队揭示了 LRM 行为的一个重要特
免费计划的v0 用户现在最多可以创建 3 个项目。项目允许你设置自定义指令并将你自己的源代码引入v0.1 版本。,时长00:53这一条挺不错的,至少你可以和Cursor更好联动。你现在可以选择 UI 生成的特定部分进行更改。,时长00:19多文件联合修改(以前是不支持的)v0 现在也可以通过自定义子域部署到 Vercel。,时长00:24v0 可以连接到数据库、API和其他外部服务。,时长01:0
本文提出了Janus框架,通过解耦视觉编码路径来提升多模态理解与生成性能,并超越现有统一模型。论文题目: Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation论文链接: https://arxiv.org/abs/2410.10486PS: 欢迎大家扫码关注公众号^_^,我们一起在
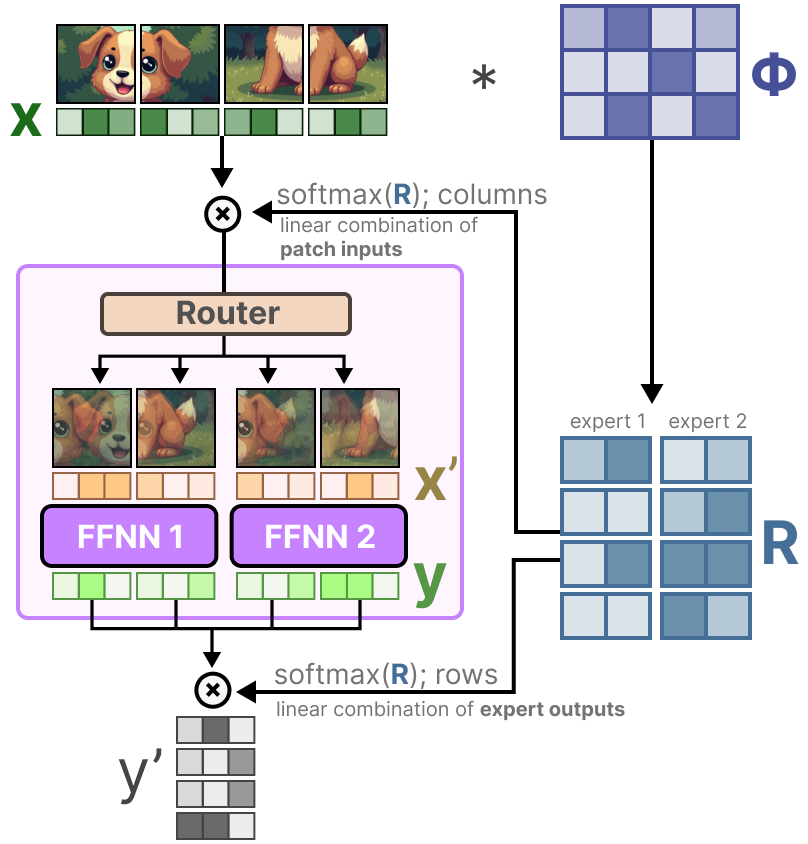
混合专家(MoE)是一种利用多个不同的子模型(或称为“专家”)来提升LLM质量的技术。MoE的两个主要组成部分是:专家:每个前馈神经网络(FFNN)层现在都有一组“专家”,可以选择其中的一部分。这些“专家”通常也是FFNN。路由或门控网络:决定哪些词元发送到哪些专家。在每个具有MoE的模型层中,我们会找到(相对专业化的)专家:需要注意的是,“专家”并不专注于特定领域,如“心理学”或“生物学”。专家
不过 Gemini-exp-1114在被问到是谁创造和自己是谁时,竟然回答Anthropic 和 Claude。网友戏称,最让人感到直观的解释就是使用Claude生成的数据训练的。可惜代码能力逊色了一点,从图中我们可以看到与 o1-mini/preview 还是有一定差距的。目前,Gemini-Exp-1114 可以在谷歌AI Studio 对话体验。图中有多少水果,哪一种最小,哪一种酸性最强,它

VITA-1.5 是一款开源的交互式多模态大型语言模型,实现接近实时的视觉和语音交互体验。相较于之前的VITA-1.0版本,VITA-1.5 在多个方面取得了显著进步。VITA-1.5 还采用了渐进式训练策略,确保在加入语音模态时,对其他多模态性能的影响最小化。该模型。
在插入新弹匣的瞬间,一发流弹几乎擦着TA的头飞过,迫使TA猛地一缩头 (6-7s)。的森林小径渐行渐远,她长发飘逸,乌黑顺直,浅色肌肤在自然光线下更显细腻。中景,跟随女子背影的视角,展现她融入。输入提示词“老虎怒吼后猛然冲向镜头,张口扑咬,巨大的身体掀翻树木,镜头剧烈晃动,模拟第一人称逃跑视角,穿越丛林,狂奔躲避追击,树枝划过镜头,恐惧与速度并存”看电影时,你忘了他是影帝,你沉浸到剧情里,忘了他是