- @yxn4065
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了双网卡双网关服务器配置中非对称路由问题的解决方案。通过Linux策略路由技术,实现"谁接收请求就从谁返回响应"的路径对称原则。文章提供了生产级配置步骤,包括创建自定义路由表、配置策略路由规则、设置主路由表等核心操作,并给出两种持久化方案(rc.local和NetworkManager dispatcher)的对比与实现方法。该方案能有效解决跨网段访问异常问题,确保网络高可用性和流量分

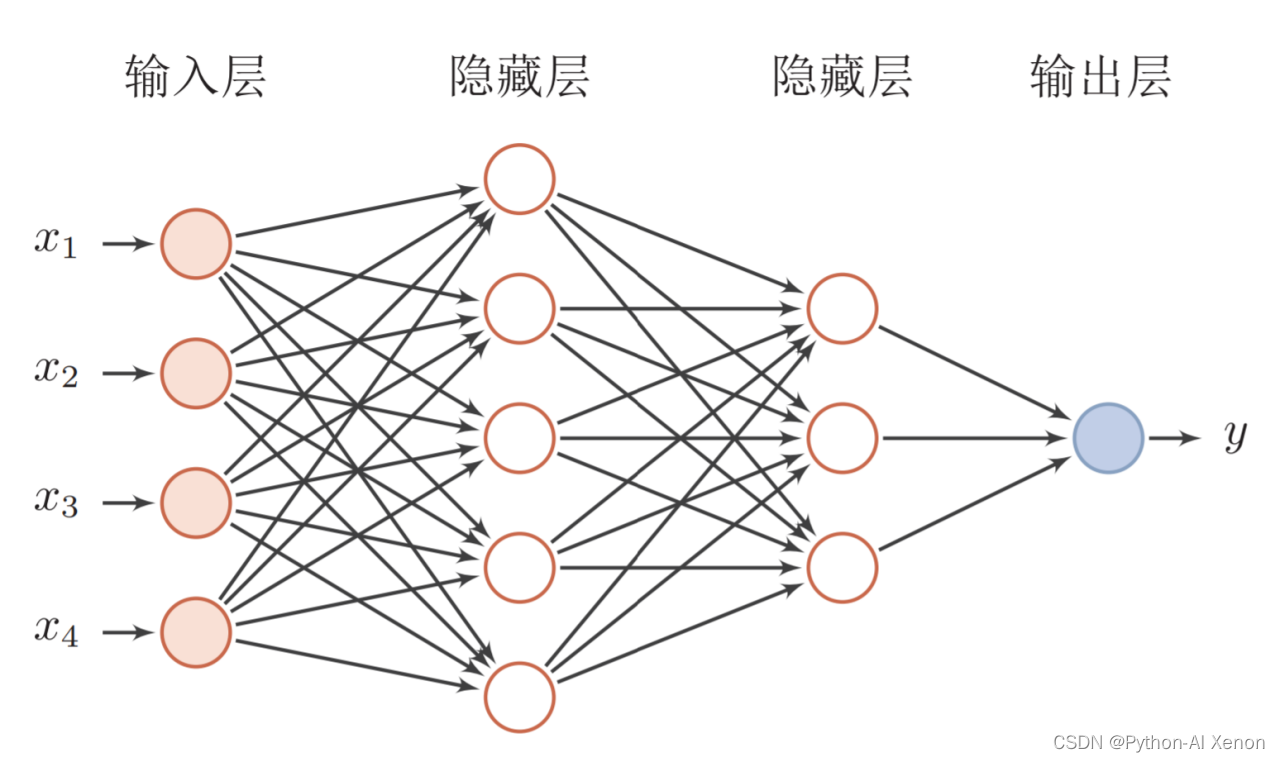
前馈神经网络(feedforward neural network,FNN),是一种最简单的神经网络,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈,信号从输入层向输出层单向传播。前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出
现在 jupyter 就部署好了,打开任意浏览器输入。进入编辑模式,编辑完成后按Esc,键入。5. 启动jupyter 挂到后台运行。注:vim的编辑,键入。

解决pycharm连接服务器时执行python文件出错问题
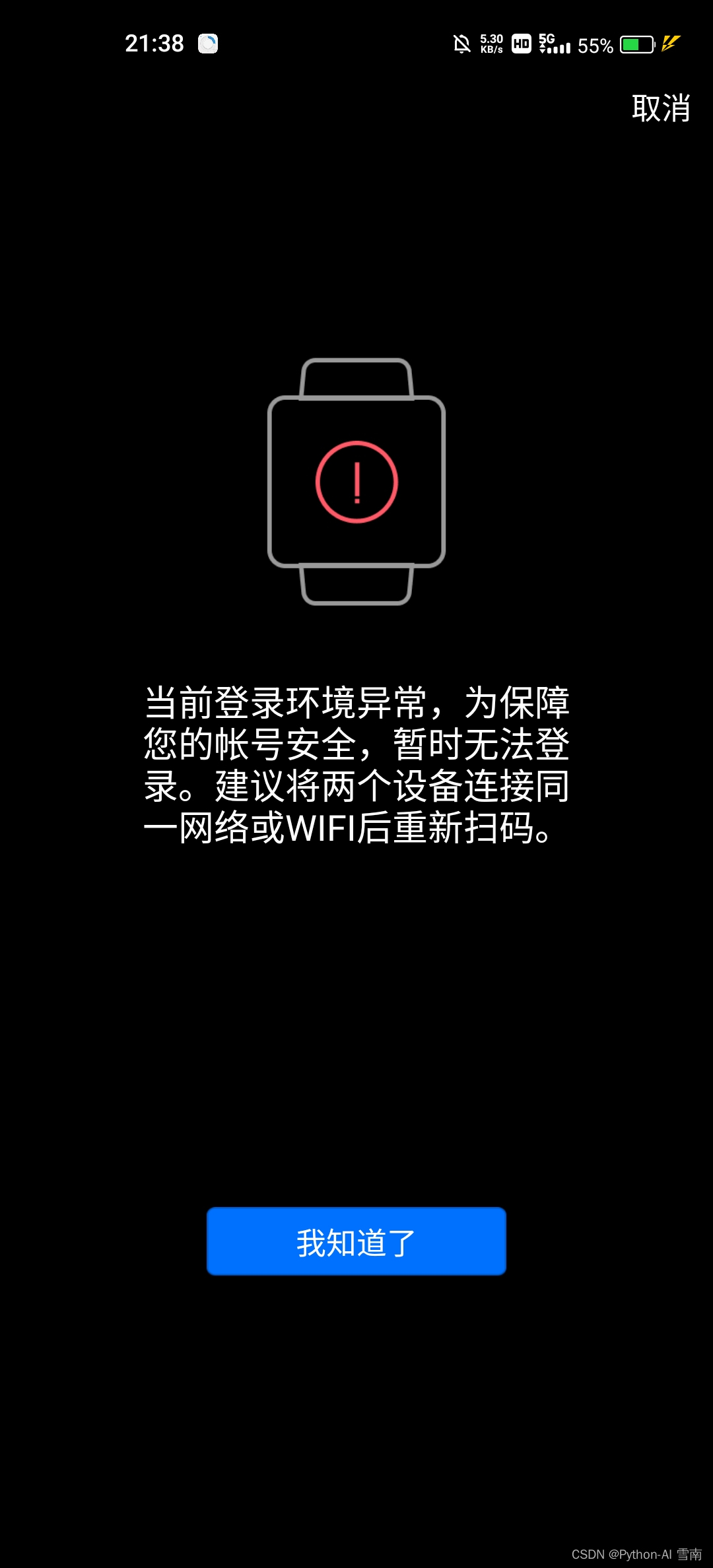
提示我"当前登录环境异常,为保障您的帐号安全,暂时无法登录。建议将两个设备连接同一网络或WIFI后重新扫码。"苦涩~~这神异常,还要连接同一个网络环境才能登录,(鹅厂这打压外面的机器人可谓手段百出啊)然后网上也搜了很多方法,比较多的靠谱的都是说把config.yml文件的QQ密码置空,但我试了还是没用。苦涩×2
最近需要用新版的python3.9进行处理但是服务器自带的却是3.68,把它给一步步升级了吧
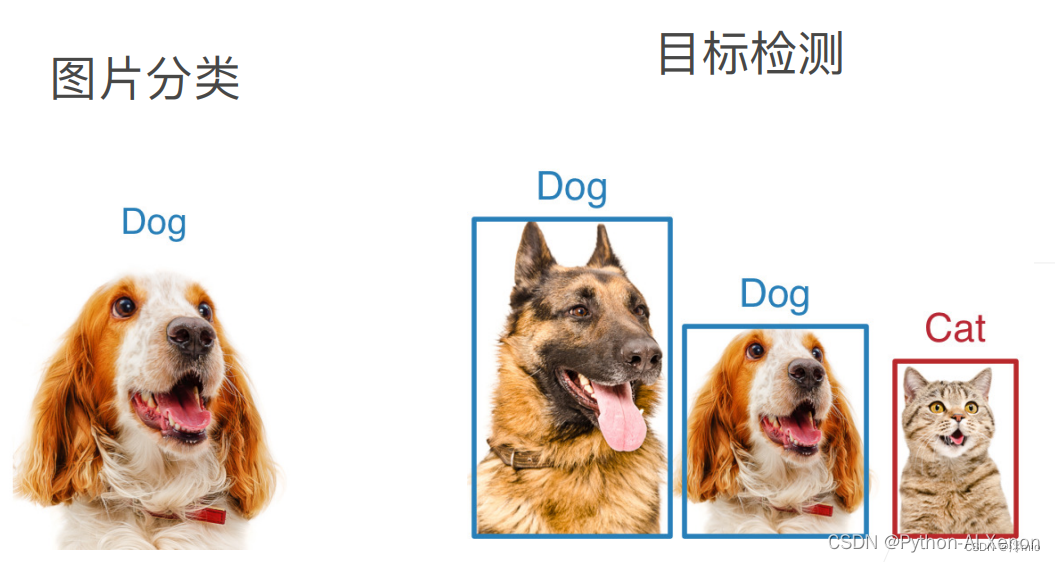
在计算机视觉的广阔领域中,数据标注无疑占据着举足轻重的地位。作为构建和训练视觉模型的基础,数据标注为机器提供了理解和解析图像的关键信息。对于初学者而言,掌握数据标注技能不仅是进入计算机视觉领域的敲门砖,更是提升模型性能、实现精准图像识别的关键所在。数据标注不仅仅是简单的标记工作,它涉及到对图像内容的深入理解、对标注规范的准确把握,以及耐心细致的操作。通过数据标注,我们可以将图像中的目标物体、关键特
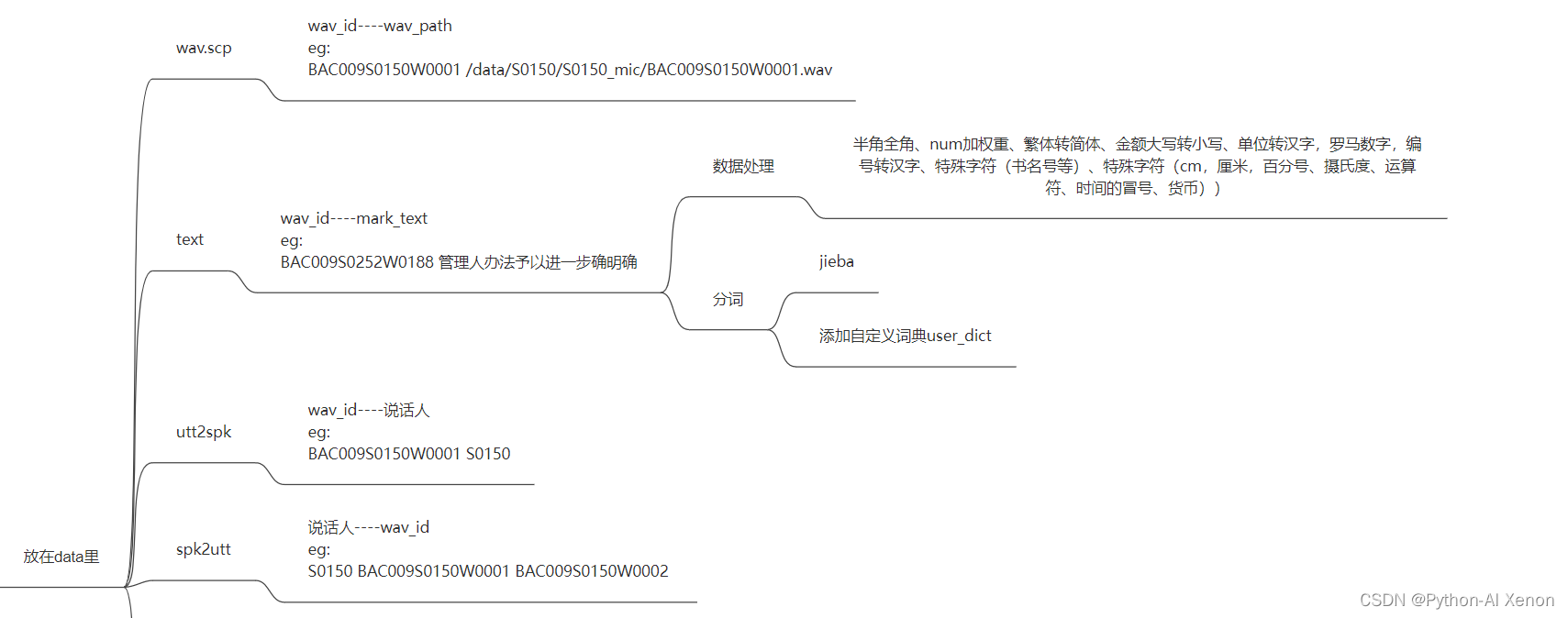
实践主要基于 kaldi里面的 aishell1 示例,所以需要准备以下数据,生成准备四个文件
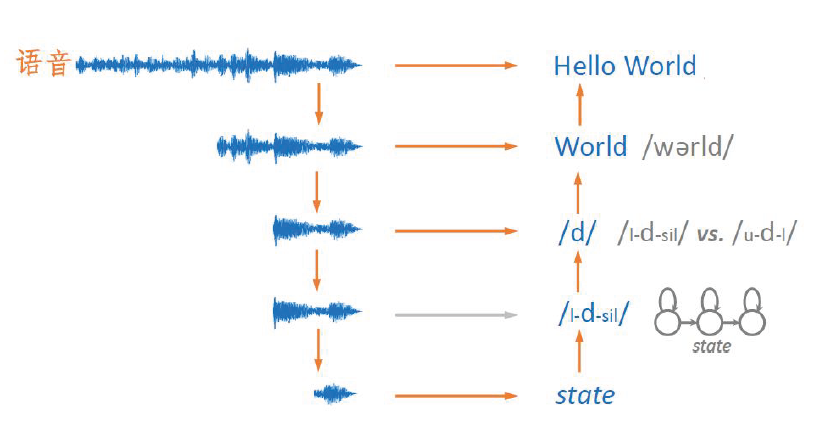
一个完整的Kaldi需要得到下面四个FST识别流程如下:本章节完成以下内容:L.fst的生成
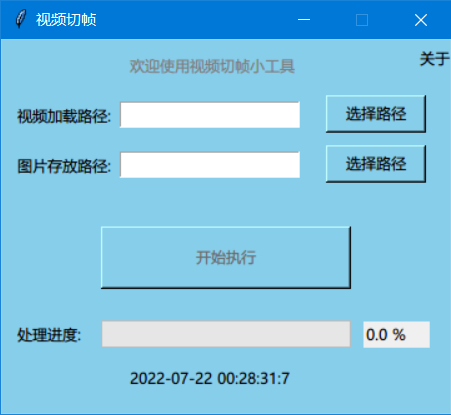
短短100多行代码利用opencv和tkinter写了一个视频切帧的脚本