




- @yetzi1975
简介
叶梓,长期负责城市信息化智能平台的建设工作,牵头多个省级、市级智能化信息系统的建设,主持设计并搭建多个行业省级、市级大数据平台。提供人工智能相关的培训和咨询
擅长的技术栈
可提供的服务
人工智能,大数据方向的培训及咨询
人工智能咨询培训老师叶梓 转载标明出处多模态图像生成是内容创作领域的热点技术,尤其在媒体、艺术和元宇宙等领域。该技术旨在模拟人类的想象力,将视觉、文本和音频等多种模态属性相关联,以生成图像。早期的方法主要侧重于单一模态输入的图像生成,例如基于图像、文本或音频的生成。这些方法在处理现实世界中更复杂的模态输入时受到限制。香港科技大学(广州)的研究团队提出了一种名为ImgAny的新型多模态图像生成框架。

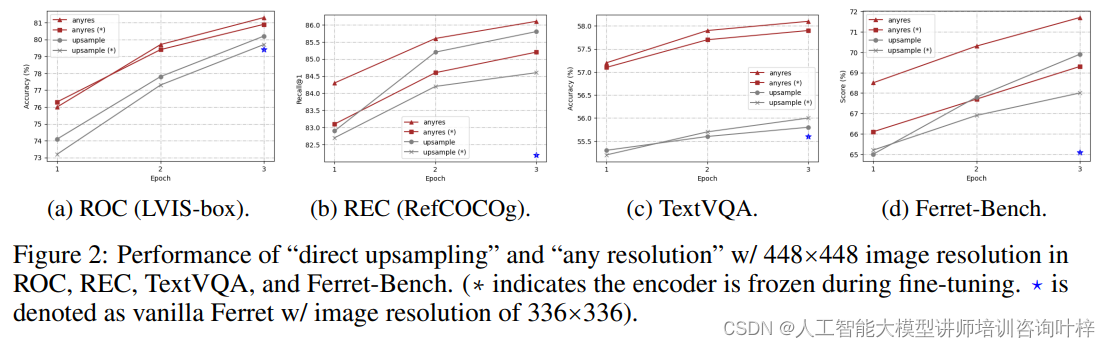
在多模态大模型(MLLMs)的研究中,如何将视觉理解能力与语言模型相结合,以实现更精细的区域描述和推理,是一个重要的研究方向。先前的工作如Ferret模型,通过整合区域理解能力,提升了模型在对话中的指代能力。然而,这些方法通常基于粗糙的图像级对齐,缺乏对细节的精细理解。为了解决这一问题,研究者们开始探索如何提升MLLMs在详细视觉理解任务中的表现。
OpenCLAW 是一款开源的AI智能体,由彼得·斯坦伯格开发,核心定位是“可执行、可定制的数字助理”,区别于传统仅能对话的AI,它能真正落地执行各类任务,是企业降本增效、个人提升效率的实用工具。
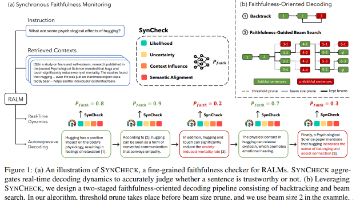
摘要:加州大学洛杉矶分校研究人员提出SYNCHECK框架,用于实时检测大模型生成内容中的不忠实信息。该系统通过分析似然性、不确定性、上下文影响和语义对齐四个关键信号,结合轻量级聚合器评估文本忠实度。在此基础上开发的FOD解码算法,利用贪婪搜索和回溯机制动态优化生成质量。实验在问答、摘要等任务中验证了该方法的有效性,SYNCHECK-MLP版本在六项任务中平均表现最优,AUROC指标显著优于基线模型
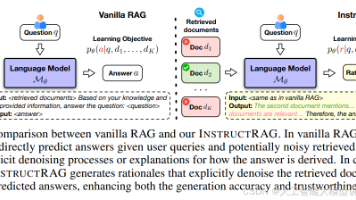
弗吉尼亚大学研究者提出INSTRUCTRAG框架,解决检索增强生成(RAG)中的噪声问题。该框架通过两个关键步骤:1)使用指令调整模型生成解释性理由,说明如何从检索文档推导答案;2)利用这些理由指导模型明确学习去噪。实验表明,INSTRUCTRAG在多个知识密集型任务中平均提升8.3%准确率,显著优于传统RAG方法。该方法无需额外监督,通过合成高质量去噪理由提升模型性能,为处理检索噪声提供了新思路
OpenCLAW 是一款开源的AI智能体,由彼得·斯坦伯格开发,核心定位是“可执行、可定制的数字助理”,区别于传统仅能对话的AI,它能真正落地执行各类任务,是企业降本增效、个人提升效率的实用工具。
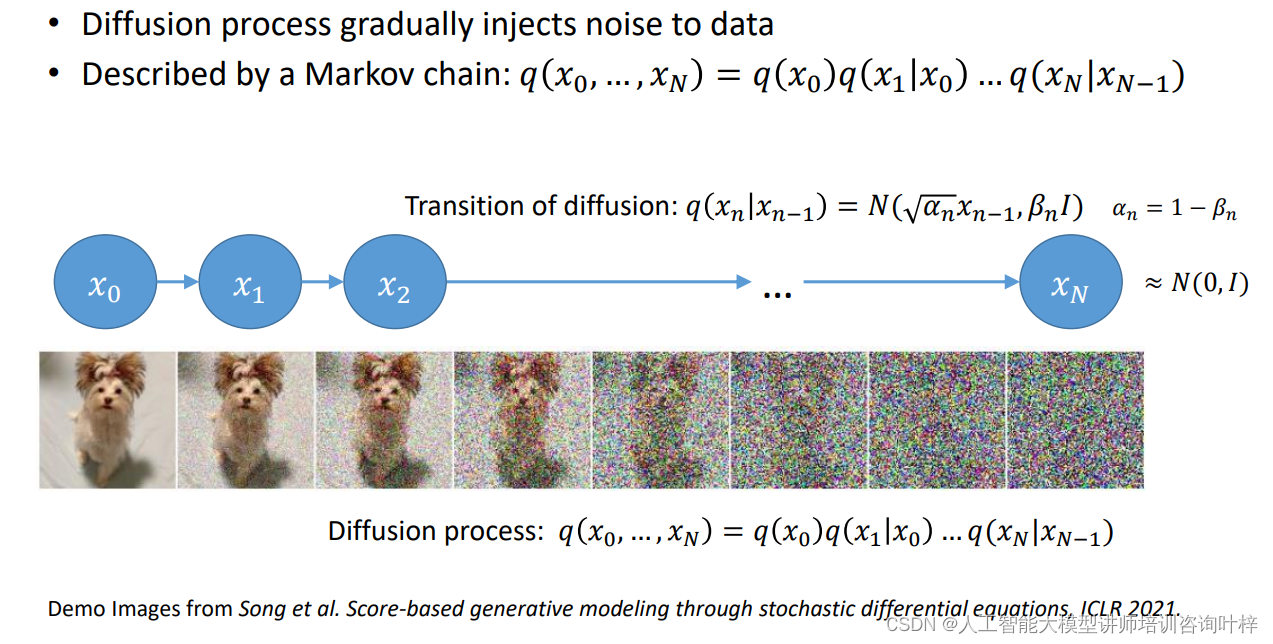
去噪扩散概率模型基于扩散过程的概念,它模拟了数据从原始状态逐渐被噪声污染,然后再通过去噪步骤逐步恢复的过程。这个过程可以被逆向进行,从而生成新的数据样本。数据在扩散过程中的转换,包括公式和噪声注入的示意图。
它的关键在于通过特定的提示语让模型生成思考过程,然后再将生成的理由和问题拼在一起,配合指向答案的提示来激励模型生成答案。同时,随着技术的进步和更多相关研究的出现,我们期待看到更多创新的方法来进一步提升大模型的推理能力。近年来,研究者们提出了多种方法来增强大模型的推理能力,这些方法在不同程度上模拟了人类的思考过程,提高了模型解决问题的准确性和效率。Auto-CoT提出自动构建带有问题和推理链的演示,

灵活的应用部署:Dify支持多种大语言模型,开发者能够根据自己的需求选择最适合的模型来构建AI应用。叶梓老师将带您深入了解Dify的核心优势,从零开始构建高效的AI应用。是一款开源的大模型应用开发平台,旨在简化和加速生成式AI应用的创建和部署。结合实践,叶梓老师带你从零开始,动手操作,快速上手Dify,解锁大模型的无限潜能。1、掌握Dify的核心功能,从大模型接入到应用构建,全方位提升开发效率。3

Dify是一款开源的大模型应用开发平台,旨在简化和加速生成式AI应用的创建和部署。它结合了后端即服务(BaaS)和LLMOps的理念,以其低代码、模块化设计和强大功能组件,为开发者提供了一站式的大模型应用开发解决方案。灵活的应用部署:Dify支持多种大语言模型,开发者能够根据自己的需求选择最适合的模型来构建AI应用。结合实践,叶梓老师带你从零开始,动手操作,快速上手Dify,解锁大模型的无限潜能。
