




- @yeshang_lady
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
语音识别工具评测怎么选

语音识别软件性价比哪个好
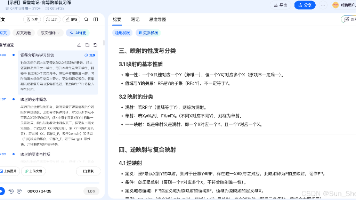
因为最近在计算IV的时候计算出的IV值明显偏高,当时怀疑代码:import pandas as pdimport numpy as npimport warningswarnings.filterwarnings('ignore')def univeral_df(data,feature,target,total_name,good_name,bad_name):"""统计feature不同值对应
本篇主要介绍pyspark.ml.linalg中的向量操作。
AARRR模型是由风险投资人麦克卢尔创造,该模型得名于五个成功创业关键元素的首字母缩写。AARRR模型涉及用户使用产品的整个流程,它可以帮助分析用户行为,为产品运营制定决策,从而实现用户增长。AARRR模型对应产品运营的5个重要环节,具体如下:1.获取用户(Acquisition): 用户如何找到我们? 在互联网行业中,很多创业公司死掉并不是因为业务或产品不行,而是因为获客成本很高,并且没有
本篇博客主要介绍如何在GoLand中引入github.com中的第三方包。
主要整理与零售行业有关的业务知识和常用业务指标 本文所说的零售行业的研究对象是线下实体店,比如全家、耐克实体店等。1.业务流程 目前,实体店主要分为直营实体店和联营实体店。直营实体店是公司自己开的店,而联营实体店是公司和个人一起合作开的店。实体店的主要业务流程如下:订货和发货:根据实体店的销售情况来订货,制定实体店的进货计划,如订货数量、订货金额等。实体店订货后,商品会从总部仓库发货到实体店。
1. 数据库查询2. 数据库连接
lxml中有多种方式可以提取HTML标签中的内容,这篇博客的重点在于各个方法的不同。import lxmlfrom lxml import etreeimport collectionsdoc='''<html><head><base href='http://example.com/' /><title>Example website</
1. Windows下安装pyhanlppip install pyhanlp:报错内容如下error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: https://visualstudio.microsoft.com/visual-cpp-build-tool