




- @yaohaishen
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统研究了大型语言模型同策略蒸馏(OPD)的成功条件与失效机制。研究发现:1)OPD成功需要思维模式一致性(初始高令牌重叠率)和教师提供新知识;2)学习主要发生在师生高概率重叠令牌上,呈现渐进对齐特征;3)长轨迹会导致奖励信号退化,建议3-7K最佳长度窗口;4)单令牌采样训练已足够,无需全词汇优化。实验覆盖多个模型家族和数学基准,提出了离策略冷启动和提示对齐等实用解决方案。这项工作为高效模型蒸
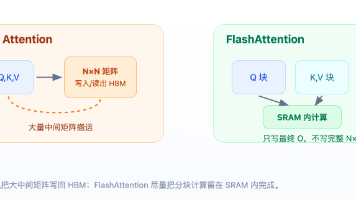
FlashAttention是一种通过优化内存访问而非减少计算量来加速Transformer模型的技术。其核心思想是将Q、K、V矩阵分块计算,利用GPU高速SRAM缓存进行局部运算,并通过OnlineSoftmax算法保证分块计算结果与标准Attention数学等价。该方法避免了显式生成N×N注意力矩阵,使训练显存复杂度从O(N²)降至O(N),同时显著减少HBM读写操作。FlashAttenti
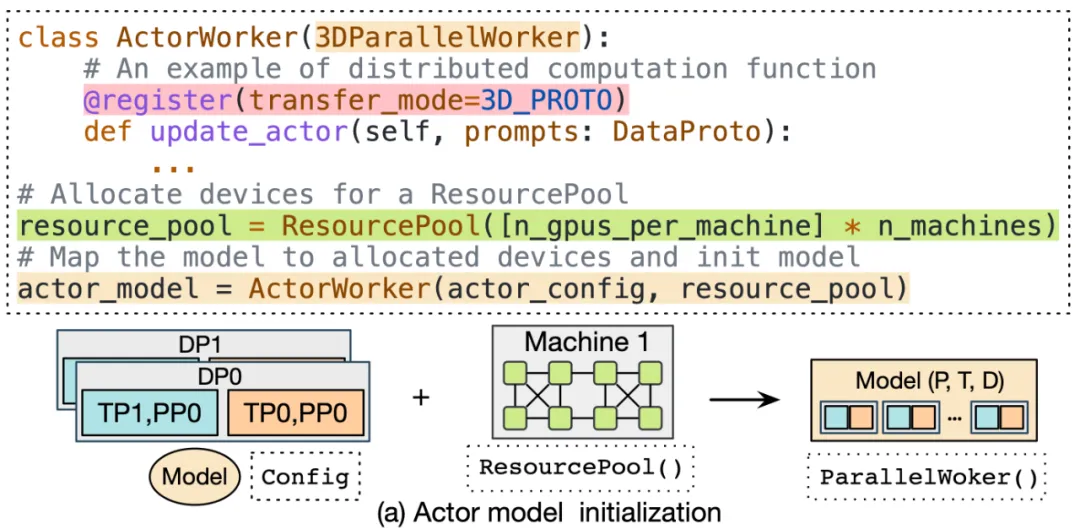
在训练和生成阶段,3D-HybridEngine 使用不同的三维并行配置,包括:流水线并行(PP)、张量并行(TP)和数据并行(DP)的大小。训练阶段的并行配置为 𝑝-𝑡-𝑑。在生成阶段,我们新增一个新的微数据并行组(Micro DP Group,𝑑𝑔),用于处理 Actor 模型参数和数据的重组。生成阶段的并行配置为 𝑝𝑔-𝑡𝑔-𝑑𝑔-𝑑。
背景在传统的NLP单模态领域,表示学习的发展已经较为完善,而在多模态领域,由于高质量有标注多模态数据较少,因此人们希望能使用少样本学习甚至零样本学习。最近两年出现了基于Transformer结构的多模态预训练模型,通过海量无标注数据进行预训练,然后使用少量有标注数据进行微调即可。多模态预训练模型能够通过大规模数据上的预训练学到不同模态之间的语义对应关系。在图像-文本中,我们期望模型能够学会将文本中
文本生成是NLP中较难的点,应用场景多且广泛。本篇笔记录一下文本生成的应用场景和主流方案,主要是基础的学习汇总和解决方案的梳理,相关学习资料在文中有链接或者文末有参考文献(我人工筛选的)都是相对经典的。文本生成的应用领域信息抽取:生成式阅读理解一篇长篇新闻中根据抽取的事件,生成简短概述对话系统:闲聊回复|知识型问答回复用户:我今天失恋了chatbot:抱抱,不哭用户:章子怡现在的老公是谁呀?cha
当遇到新的物品推荐时,计算物品嵌入与用户请求和偏好的嵌入之间的相似性,然后根据相似性检索最相关的物品信息,并构建一个提示输入到 ChatGPT 进行推荐,如图 3 的下半部分所示。除了一个领域的目标产品,如电影,LLMs 不仅对许多其他领域的产品有广泛的了解,如音乐和书籍,而且还了解上述各领域的产品之间的关系。左边的对话显示,当用户询问为什么推荐这部电影时,LLM 可以根据用户的喜好和推荐电影的。

论文简介:对偶对比学习:如何将对比学习用于有监督文本分类论文标题:Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation论文链接:https://arxiv.org/abs/2201.08702代码链接:https://github.com/hiyouga/dual-contrastive-l
机器之心专栏作者:李永彬、惠彬原、黄非团队:达摩院-自然语言-对话智能团队SPACE-1:注入对话策略知识,AAAI 2022 长文录用;SPACE-2:注入对话理解知识,COLING 2022 长文录用,并获 best paper award 推荐;SPACE-3:集对话理解 + 对话策略 + 对话生成于一体的模型, SIGIR 2022 长文录用。达摩院对话大模型 SPACE-1/2/3 在
主要从以下几个方面进行总结:分布式训练的基本原理TensorFlow的分布式训练PyTorch的分布式训练框架Horovod分布式训练无论哪种机器学习框架,分布式训练的基本原理都是相同的。本文主要从 并行模式、架构模式、同步范式、物理架构、通信技术 等五个不同的角度来分类。分布式训练的目的在于将原本巨大的训练任务拆解开撑多个子任务,每个子任务在独立的机器上单独执行。大规模深度学习任务的难点在于:训