




- @xuehao1997
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文以「AI作文」小程序为例,详细介绍了Taro框架下实现优雅分包的方法。通过集中式路由管理和显式分包声明,将写作功能和素材搜索功能分别放入不同分包,同时自动过滤主包页面。文章强调分包的本质是遵循小程序平台规范,Taro只是提供配置入口。指出了分包的必要性、常见误区及注意事项,如TabBar页面限制、分包间引用限制等。最后总结了通过路由统一管理和自动过滤机制,可以实现清晰可扩展的分包架构,适用于各

本文探讨了在AI辅助编程时代如何平衡快速功能开发(Vibe Coding)与代码质量(优雅重构)的问题。作者提出分层策略:功能阶段允许临时性补丁代码但限制污染范围,稳定后进入重构阶段主动优化结构。给出了四步重构法和五项重构触发标准,建议开发者主导架构设计,让AI负责实现。核心观点是开发者需要在关键节点主动控制重构节奏,避免陷入补丁地狱,使AI成为真正的开发加速器而非技术债务制造者。最终目标是解决当

本文探讨了在AI辅助编程时代如何平衡快速功能开发(Vibe Coding)与代码质量(优雅重构)的问题。作者提出分层策略:功能阶段允许临时性补丁代码但限制污染范围,稳定后进入重构阶段主动优化结构。给出了四步重构法和五项重构触发标准,建议开发者主导架构设计,让AI负责实现。核心观点是开发者需要在关键节点主动控制重构节奏,避免陷入补丁地狱,使AI成为真正的开发加速器而非技术债务制造者。最终目标是解决当
本文以「AI作文」小程序为例,详细介绍了Taro框架下实现优雅分包的方法。通过集中式路由管理和显式分包声明,将写作功能和素材搜索功能分别放入不同分包,同时自动过滤主包页面。文章强调分包的本质是遵循小程序平台规范,Taro只是提供配置入口。指出了分包的必要性、常见误区及注意事项,如TabBar页面限制、分包间引用限制等。最后总结了通过路由统一管理和自动过滤机制,可以实现清晰可扩展的分包架构,适用于各
文章摘要:本文探讨了从传统模型到大模型的技术演进历程。传统模型采用"输入→映射→输出"的数学工具模式,通过固定格式的数据训练,在特定领域表现稳定可靠。随着深度学习发展,大模型凭借多模态输入、通用预训练和万亿级参数等优势,实现了从"专业工匠"到"通才学生"的转变。当前行业正致力于构建大模型开发平台和智能Agent系统,推动AI从被动响应向主

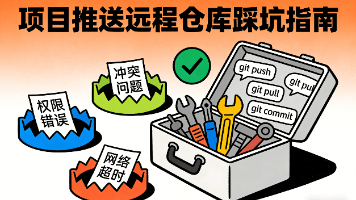
本文记录了将本地 Vue CLI 项目推送到 GitHub 时遇到的常见问题及解决方案。首先遇到"未配置远程仓库"错误,需通过git remote add添加;其次因 GitHub 禁用密码认证,必须改用 SSH 或 Token 方式。详细介绍了 SSH 密钥生成、GitHub 配置和测试流程,并强调了统一使用 SSH 地址的重要性。最后总结了一份踩坑清单,建议新项目统一使用
摘要:基于 @microsoft/fetch-event-source 实现 AI 对话流式响应 本文探讨了使用 SSE(Server-Sent Events)技术实现 AI 对话流式响应的方法,重点介绍了 @microsoft/fetch-event-source 库的封装实践。原生 EventSource 存在无法发送 POST 请求、错误处理薄弱等缺陷,而 @microsoft/fetch-

《前端视角:从点击到AI理解的Transformer全流程》 本文以前端工程师视角解析Transformer架构,用通俗类比揭示AI思考过程:1)输入文本通过分词和嵌入层转为向量;2)位置编码标记词序;3)编码器通过自注意力机制(类似JS的map和权重计算)分析词间关系;4)多头注意力像"阅读时圈重点",前馈网络增强语义表达。Transformer的并行处理和全局感知能力使其成

摘要: 神经网络是一种模仿人脑的数学模型,通过输入数据经多层计算输出结果。它由输入层、隐藏层和输出层组成,通过线性变换和非线性激活函数处理数据,利用反向传播和梯度下降自动调参。前端工程师虽不直接训练模型,但在AI应用中需理解神经网络的输入输出关系,以优化交互设计、提升用户体验。神经网络并非神秘黑盒,而是复杂数学函数的组合,前端作为AI的“眼睛和嘴巴”,需与其协同工作。理解神经网络原理有助于前端开发
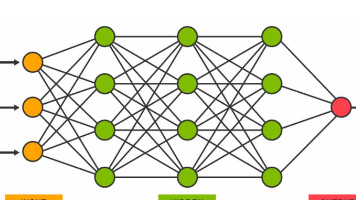
文章摘要:本文探讨了从传统模型到大模型的技术演进历程。传统模型采用"输入→映射→输出"的数学工具模式,通过固定格式的数据训练,在特定领域表现稳定可靠。随着深度学习发展,大模型凭借多模态输入、通用预训练和万亿级参数等优势,实现了从"专业工匠"到"通才学生"的转变。当前行业正致力于构建大模型开发平台和智能Agent系统,推动AI从被动响应向主