- @xhtchina
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统总结了计算机视觉领域中常用的直线检测算法及其应用。首先介绍了直线检测在智慧交通、车道线检测等场景的重要性,然后详细分析了多种经典算法:1. 基于霍夫变换的Hough_line算法;2. LSD快速直线检测算法;3. FLD直线特征检测算法;4. EDlines高效检测算法;5. LSWMS实时检测算法;6. CannyLines鲁棒检测算法;7. 基于概率模型的MCMLSD算法;8. 具有

本文系统综述了人工智能(AI)在科研领域的应用(AI4Research),提出了涵盖科学理解、学术调研、科学发现、学术写作和同行评审五大任务的新分类体系。研究梳理了AI在跨学科科研中的核心能力,包括文本/图表理解、文献检索、假设生成、实验自动化、论文撰写与评审等关键环节。文章不仅整合了相关多学科应用和资源(如数据集、工具库),还指出了未来六大研究方向:跨学科AI模型开发、科研伦理治理、协作研究系统
本文介绍了MATLAB中数据导入、输出显示、曲线拟合、姿态表示和图形绘制等实用功能。主要包括:1)使用importdata导入图像、文本和剪切板数据;2)disp和fprintf函数的输出显示方法,后者支持格式化输出;3)polyfit函数进行多项式曲线拟合;4)四元数与旋转矩阵、欧拉角的相互转换函数;5)plot函数的基本绘图参数设置。这些内容涵盖了MATLAB数据处理与可视化的基础操作,适用于
本文介绍了三维空间旋转的数学表示方法及其相互转换关系。主要内容包括:1) 欧拉角与旋转矩阵的相互转换,指出固定轴旋转与运动轴旋转顺序的等价性,并提供了避免欧拉角跳变的自定义转换代码;2) 轴角表示与旋转矩阵的转换关系,说明旋转轴对应特征值为1的特征向量;3) 四元数与欧拉角、旋转矩阵的转换公式;4) 方向余弦矩阵的概念。文章综合了多个参考来源,系统阐述了不同旋转表示方法之间的数学联系与实用转换技巧
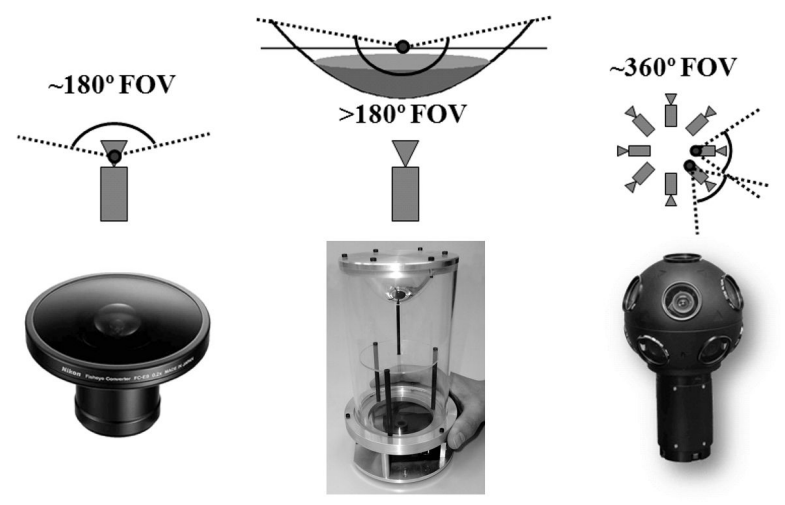
全向相机分三类:鱼眼(180-270°)、折反射(抛物面+相机,360° 但体积大)、多相机背靠背拼接。模型:Geyer 用球面统一折反射,Scaramuzza 用 3-4 阶泰勒多项式统一鱼眼+折反射(更鲁棒)。标定:平面棋盘多角度拍照求内参+畸变,OcamCalib/OpenCV fisheye 都可用。工程:正向投影(世界→像素)、反投影(像素→射线)、生成 LUT 展开为针孔/柱面/Per
本文介绍了Python数据可视化库Plotly的核心功能与应用。Plotly作为开源交互式可视化工具,支持折线图、柱状图、散点图等多种图表类型。文章详细讲解其安装方法、基础绘图流程(包括数据生成、图表创建与布局设置),并提供了柱状图、散点图和饼图的具体实现代码。最佳实践部分涵盖Pandas数据集成、图表保存为HTML文件以及自定义样式等技巧。Plotly的交互特性和跨平台支持使其成为数据分析和展示
本文汇总了全球范围内在SLAM(同时定位与建图)领域具有影响力的研究团队及其代表性成果。涵盖美国、欧洲、亚洲等地的高校和实验室,包括卡耐基梅隆大学机器人研究所、麻省理工学院SPARK实验室、苏黎世联邦理工大学计算机视觉与几何实验室等。重点介绍了各团队的研究方向(如视觉/激光SLAM、语义导航、多机器人协作等)、开源项目(如VINS-Mono、ORB-SLAM2、Kimera等)以及经典论文(如iS
本文介绍了NumCpp库的安装与使用方法,NumCpp是一个提供类似NumPy功能的C++矩阵运算库。主要内容包括:1)通过Git克隆源码并编译安装;2)在CMake项目中配置NumCpp依赖;3)核心数据结构NdArray(二维数组类)和DataCube的基本操作,如创建数组、reshape和类型转换;4)矩阵初始化方法(如linspace、zeros、eye等)和切片/广播操作;5)代码示例展
Python的Validators库简化了数据验证流程,支持邮箱、URL、IP等常见格式校验。通过简洁API实现快速验证,如validators.email("test@example.com")返回True/False。支持自定义规则,适合表单验证、API参数检查等场景。相比其他验证工具更轻量专注,显著提升开发效率。安装简单(pip install validators),是
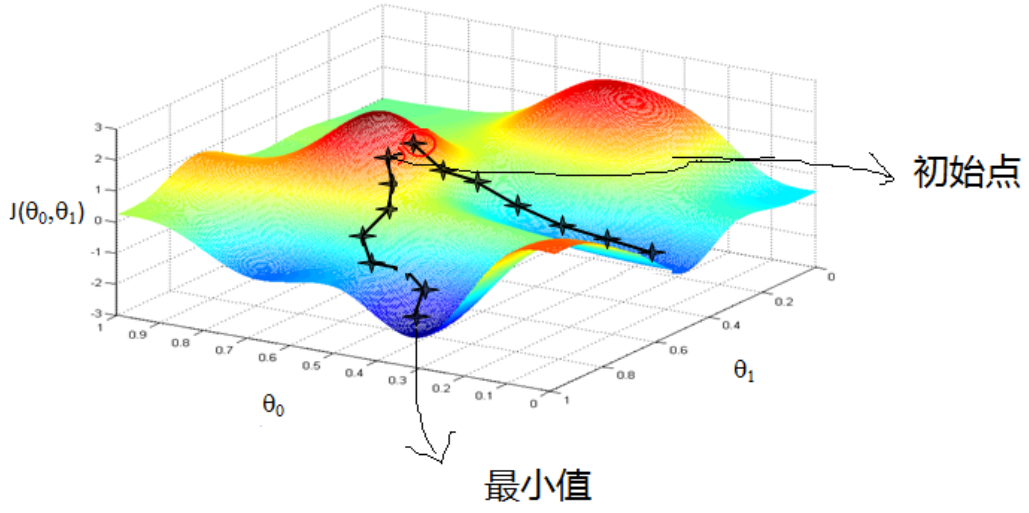
梯度下降是机器学习中常见优化算法之一,梯度下降法有以下几个作用:1)梯度下降是迭代法的一种,可以用于求解最小二乘问题。2)在求解机器学习算法的模型参数,即无约束优化问题时,主要有梯度下降法()和最小二乘法。3)在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。4)如果我们需要求解损失函数的最大值,可通过梯度上升法来迭代。梯度下降法和梯度上升法可相互转