




- @wzm15939943783
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
尽量自己编写一次代码,这样会对深度学习的网络框架有更深理解。操作系统:Ubuntu 18.04 / Windows 10编程语言:Python 3.7+深度学习框架:PyTorch 1.6+编译器:IDE(如PyCharm)或Jupyter Notebook计算机硬件配置:NVIDIA GPU(如CUDA兼容的显卡)推荐,但CPU也可运行相关库:torchvision, numpy, matplo

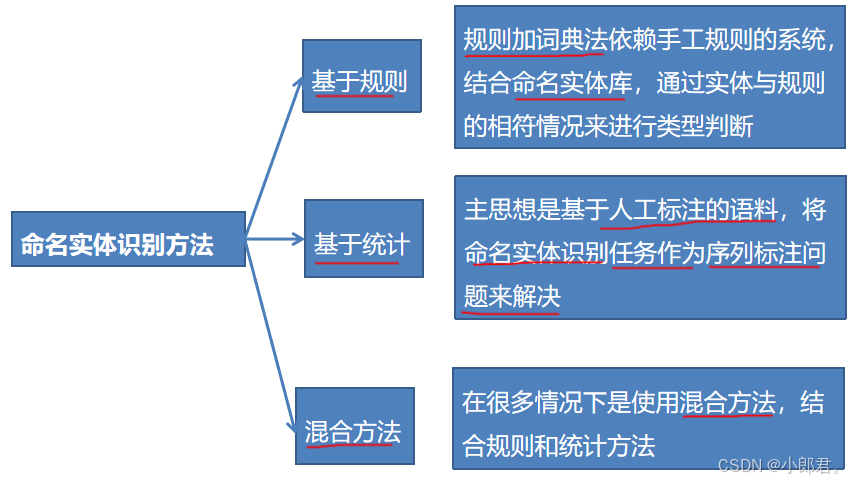
一、概念命名实体识别(Named Entity Recognition,NER)中的“命名实体”一般是指文本中具有特别意义或者指代性非常强的实体,可分为三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)。命名实体识别的任务就是识别出文本中的命名实体,通常分为两个过程:实体边界识别和实体类别的确定。二、问题转化中文命名实体识别的本质就是序列标注。设定3种命名实体
response = query_engine.query("疲乏无力,消瘦,,可伴见腹胀如水状,大便或黑,皮肤燥痒可能是哪些病症?")至此已经完成了RAG的检索->增强->生成。六、使用LlamaIndex存储和读取embedding向量在对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引时,会花费大量的时间,所以如果你保存过这些向量,可以直接给它加载进来继续用。:用于存储
Embedding(嵌入)将高维、离散、非结构化的数据(如文字、图片、音频)转换为低维、连续、结构化的向量表示。这个向量可以被计算机理解和处理。你可以把它想象成一种“翻译”,把人类能理解的概念“翻译”成计算机能理解的数学语言。想象一下,你要把世界上所有的词语都放到一个三维空间里。国王和王后这两个词,含义相近,所以它们在空间中的位置会很接近。男人和女人也是一对相近的词。同时,你会发现国王到王后的向量
DeepSpeed 是一个"魔法工具包",它能让你的小电脑训练超级大的AI模型。DeepSpeed 本质上是一个"内存魔术师":它能让小显卡训练大模型- 通过切分和共享它能让多张显卡协同工作- 像团队合作一样它能在内存不足时借用CPU- 像临时扩展工作台不用买昂贵的专业显卡也能玩大模型现有的硬件能发挥更大价值学习成本相对较低DeepSpeed 就像给你的小书房(GPU)配了一个智能书架系统(内存管
Llama Factory 是一个"AI模型定制工厂",它让普通人也能轻松地定制和训练自己的大语言模型。LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。微调的过程模型微调通过在特定任务的数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调
代表用途: 文本分类、命名实体识别、情感分析特点: 理解文本含义"""自定义训练循环"""# 创建数据加载器# 优化器# 学习率调度器"linear",# 训练设备# 训练循环# 将数据移动到设备# 前向传播# 反向传播# 参数更新# 使用自定义训练循环。
Llama Factory 是一个"AI模型定制工厂",它让普通人也能轻松地定制和训练自己的大语言模型。LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。微调的过程模型微调通过在特定任务的数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调
DeepSpeed 是一个"魔法工具包",它能让你的小电脑训练超级大的AI模型。DeepSpeed 本质上是一个"内存魔术师":它能让小显卡训练大模型- 通过切分和共享它能让多张显卡协同工作- 像团队合作一样它能在内存不足时借用CPU- 像临时扩展工作台不用买昂贵的专业显卡也能玩大模型现有的硬件能发挥更大价值学习成本相对较低DeepSpeed 就像给你的小书房(GPU)配了一个智能书架系统(内存管
它的设计理念是"开箱即用",让普通用户也能轻松在本地运行各种AI模型。请求队列 → 调度器 → 连续批处理器 → PagedAttention引擎 → 模型执行。用户界面/API → Ollama核心引擎 → 模型推理后端 → 硬件资源。:传统部署LLM需要复杂的环境配置,Ollama通过一键安装解决。:自动处理模型量化、内存管理,让大模型能在消费级硬件上运行。:对中文任务使用LMDeploy,对