




- @wuling129
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
到此为止,关于VIT模型,我们就介绍完毕了。一顿读下来,你可能有个印象:如果训练数据量不够多的话,看起来VIT也没比CNN好多少呀,VIT的意义是什么呢?这是个很好的问题,因为在工业界,人们的标注数据量和算力都是有限的,因此CNN可能还是首要选择。证明了一个统一框架在不同模态任务上的表现能力。在VIT之前,NLP的SOTA范式被认为是Transformer,而图像的SOTA范式依然是CNN。

DEIMv2模型在实时目标检测领域取得突破性进展,通过创新性地融合DINOv3的语义特征与轻量化设计,实现了从GPU到移动端的全场景部署。该模型采用分场景适配的"双轨制"架构:大模型使用DINOv3预训练ViT与无参数STA模块,超轻量模型则采用剪枝HGNetv2。通过优化Decoder结构、引入动态损失策略等创新,DEIMv2在保持高效率的同时显著提升检测精度,其中轻量版DE
这两天排查代码问题,看到损失具体是如何计算的就看了下。logits 里面保存的是 每个样本 是哪一类的概率,例如第一个样本的预测结果 tensor([ 0.0815,0.1693,0.2274, -0.0068, -0.3081, -0.2758], grad_fn=<SelectBackward0>),分别对应于类别【248135label是样本的类别:4。

【摘要】本研究提出置信深度思考(DeepConf)方法,通过动态过滤低质量推理轨迹显著提升大语言模型的推理效率与性能。该方法创新性地利用局部置信度信号(如最低组置信度、尾部置信度),在生成过程或生成后实时识别低置信度轨迹。实验表明,在AIME2025等数学推理基准测试中,DeepConf@512达到99.9%准确率,相比传统自洽性方法减少84.7%的token消耗。该方法无需额外训练即可适配不同规
在本文中,我们使用YOLOv9+SAM在RF100 Construction-Safety-2 数据集上实现自定义对象检测模型。这种集成不仅提高了在不同图像中检测和分割对象的准确性和粒度,而且还扩大了应用范围——从增强自动驾驶系统到改进医学成像中的诊断过程。通过利用 YOLOv9 的高效检测功能和 SAM 以零样本方式分割对象的能力,这种强大的组合最大限度地减少了对大量再训练或数据注释的需求,使其

注意力是一种在广泛的神经结构中使用的越来越流行的机制。由于这一领域的快速发展,仍然缺乏对注意力的系统概述。在本文中,讨论了以往工作的不同方面,注意力机制的可能用途,并描述了该领域的主要研究工作和公开挑战。

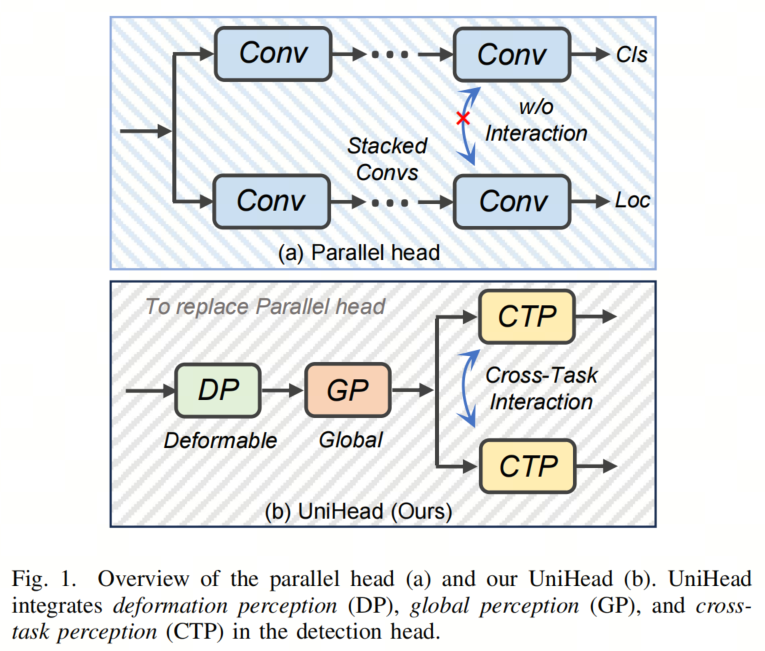
作者开发了一种创新的检测Head,称为UniHead,可以同时统一三种感知能力。更具体地说,作者的方法包含:引入了Deformation感知,使模型能够自适应地采样目标特征;提出了双轴聚合Transformer(DAT),以熟练地建模长距离依赖关系,从而实现全局感知;设计了一个跨任务交互Transformer(CIT),促进了分类和定位分支之间的交互,从而使这两个任务保持一致。
基于这些观察结果,作者更深入地研究了专用OCR模型的必要性,并探讨了充分利用GPT-4V等预训练通用LMM,将其用于OCR下游任务的策略,为今后将LMM用于OCR任务的研究提供了重要的参考。需要特别指出的是,EffOCR还允许简单、高效的样本定制,它包含一个简单的模型训练接口,由于其具有比较高的样本效率,因而只需要较少的标记需求。基于这些基本功能,DocXChain还实现了文档解析的整个流程,即文

实验结果显示,SCSA在不同检测器和模型大小上均优于其他最先进的注意力机制,例如在Faster R-CNN上,使用ResNet-50时,SCSA的平均精度(AP)提高了1.7%,使用ResNet-101时提高了1.3%。在视觉任务中,注意力机制通过增强表示学习,促进了更具区分性的特征学习,并广泛用于重新分配通道关系和空间依赖性。鉴于现有方法在处理复杂场景时的局限性,本文试图探索空间和通道注意力之间

Splicing ViT Features for Semantic Appearance Transfer论文解读
