- @wl1780852311
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
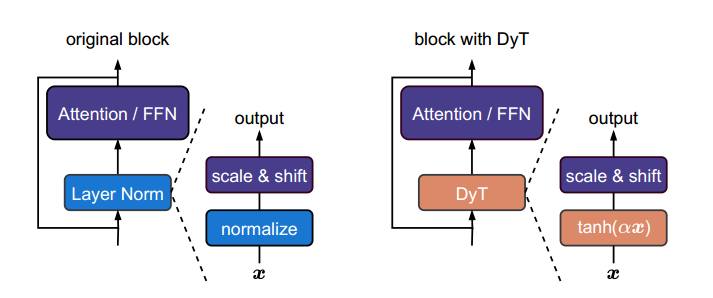
归一化层在现代神经网络中无处不在,并长期被认为是必不可少的。本研究表明,不使用归一化的Transformer可以通过一种极其简单的技术达到甚至超过标准性能。我们提出了Dynamic Tanh(DyT),这是一种逐元素的操作DyTxtanhαxDyTxtanhαx,可以直接替代Transformer中的归一化层。DyT的灵感来自于一个观察:Transformer中的层归一化通常会产生类似tanh
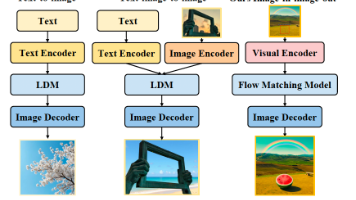
本文提出SAMA框架,通过分解式语义锚定与运动对齐解决指令引导视频编辑中的语义-运动冲突问题。SAMA采用两阶段训练策略:首先通过语义锚定建立可靠的视觉锚点,并结合运动对齐预训练学习时序动态;随后在配对编辑数据上进行监督微调。该方法在开源模型中达到最先进性能,并与商业系统竞争力相当,验证了分解式学习范式的有效性。
本文提出SpatialEdit框架,旨在解决图像细粒度空间编辑中的几何保真度问题。研究团队构建了SpatialEdit-500k合成数据集,通过Blender管线生成包含精确几何变换标注的50万张图像,涵盖物体平移/旋转/缩放和相机视角变化。基于此开发的SpatialEdit-16B模型在保持通用编辑能力的同时,显著提升了空间操控精度。新提出的SpatialEdit-Bench基准通过视点重建和构

本文提出视觉到视觉(V2V)生成范式,通过视觉规格页面而非文本提示来指导生成模型。作者开发了V2V-Zero框架,利用冻结的视觉语言模型(VLM)将视觉页面映射到生成器已有的条件空间,无需额外训练。在GenEval基准测试中,V2V-Zero达到0.85分,接近骨干网络的文本到图像性能。作者还提出了Simple-V2V Bench基准,评估七种视觉条件任务,结果显示属性绑定能力较强,但结构控制仍具
摘要 本文提出InstructX,一个基于多模态大语言模型(MLLM)引导的统一视觉编辑框架,能够同时处理图像和视频编辑任务。通过系统研究MLLM与扩散模型的整合方式,作者发现:(1)在图像数据上训练可以自然涌现视频编辑能力,缓解视频数据稀缺问题;(2)结合模态特定MLLM特征,可在单一模型中有效统一图像和视频编辑。实验表明,该方法在多种编辑任务上达到最先进性能,且无需显式视频监督即可实现零样本视
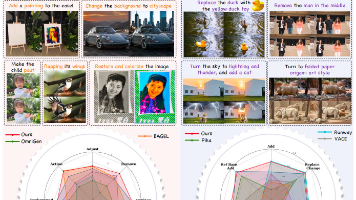
本文提出ReCo,一种面向指令式视频编辑的区域约束上下文生成方法。针对视频编辑中编辑区域定位不准和token干扰问题,ReCo创新性地引入潜在空间正则化和注意力正则化:前者通过增大编辑区域潜在差异、减小非编辑区域差异来精准定位修改;后者抑制编辑区域对源视频的注意力,减少内容干扰。方法采用视频扩散Transformer架构,将源视频与目标视频拼接进行联合去噪训练。为支持模型训练,作者构建了包含50万

本文提出FlowInOne框架,将多模态生成统一为纯视觉流的图像输入-输出范式。通过将文本、布局等输入转换为视觉提示,并使用单一流匹配模型处理,该方法消除了跨模态对齐瓶颈和任务特定架构。作者构建了VisPrompt-5M数据集(500万视觉提示对)和VP-Bench评估基准,涵盖文本生成、图像编辑和物理感知任务。实验表明,FlowInOne在指令忠实度、空间精度等方面达到SOTA性能,为全视觉中心
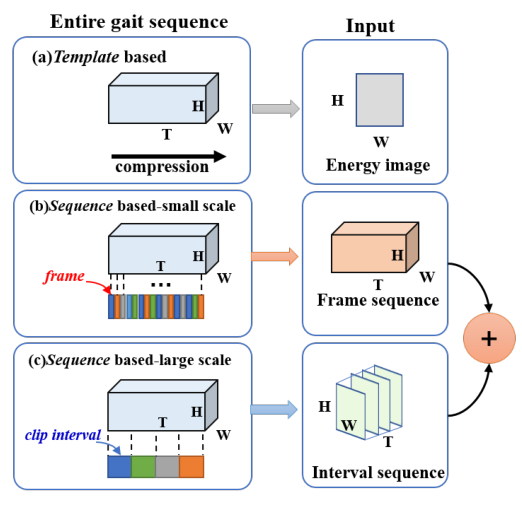
多时间尺度 3D 卷积神经网络的步态识别论文题目:Gait Recognition with Multiple-Temporal-Scale 3D Convolutional Neural Networkpaper是北京交通大学发表在MM上的工作论文链接:链接ABSTRACT步态识别是最重要和最有效的生物识别技术之一,在长距离识别系统中具有显著优势。对于现有的步态识别方法,基于模板的方法可能会丢失
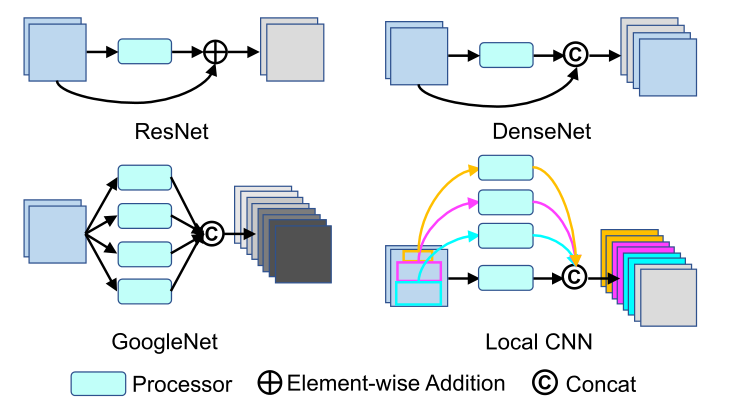
用于行人重识别的局部卷积神经网络paper题目:Local Convolutional Neural Networks for Person Re-Identificationpaper是中国科学技术大学发表在MM 2018的工作paper地址:链接ABSTRACT最近的工作表明,通过引入注意力机制可以显著改善行人重识别,该机制允许学习全局和局部表示。然而,所有这些工作都在不同的分支中学习全局和局
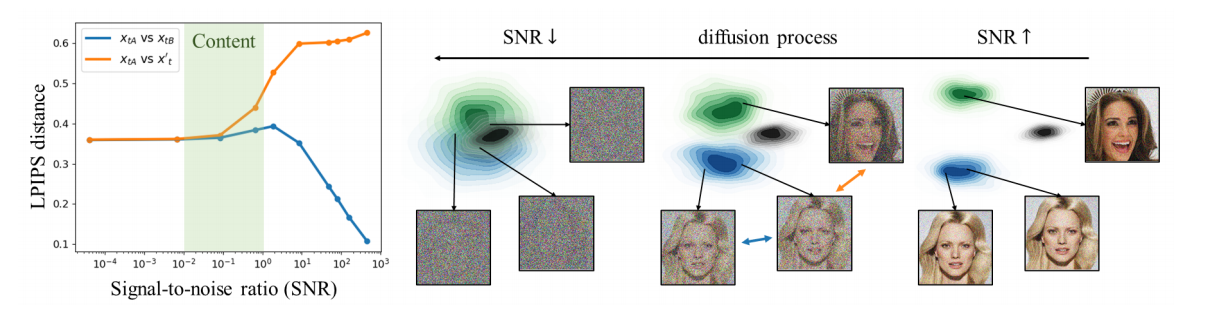
扩散模型通过优化相应损失项的加权和(即去噪得分匹配损失)来学习恢复被不同程度的噪声破坏的噪声数据。在本文中,我们表明,恢复被某些噪声水平破坏的数据为模型学习丰富的视觉概念提供了适当的代理任务。我们建议通过重新设计目标函数的加权方案,在训练期间优先考虑此类噪声水平。我们表明,无论数据集、架构和采样策略如何,我们对加权方案的简单重新设计都可以显著提高扩散模型的性能。P2通过加权强调提升粗略和内容阶段的