




- @weixin_74825138
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原本的训练集训练出来的结果,直接拿测试集去测试未免太浪费资源,而且可能精度不高,所以就有了交叉验证,这种方法是将原本的训练集在划分为训练集与测试集,比如:原本的训练集划分为5份,前四份作为训练集,最后一份作为测试集,验证第一次,然后再用1,2,3,5作为训练集,4作为测试集,再验证一次,重复交叉验证,最后求得一个均值则为训练结果,此时再用测试集进行测试,效果会好很多。sklearn能做到很多传统意

我们把背景称为负类,包含了物体的矩形框称为正类,不难理解图像中大部分的矩形框只包含了负类,若用全部的负类和正类来计算损失函数,那么训练出来的模型偏向于给出负类的结果。预测矩形框:每个特征映射图的位置包含了不同大小的先验框,然后用预测卷积层对特征映射进行转换,输出每个位置的预测矩形框,预测矩形框包含了框的位置和物体的检测分数。由第一节的损失函数介绍可知,大部分的预测矩形框包含了负类(背景类),容易知

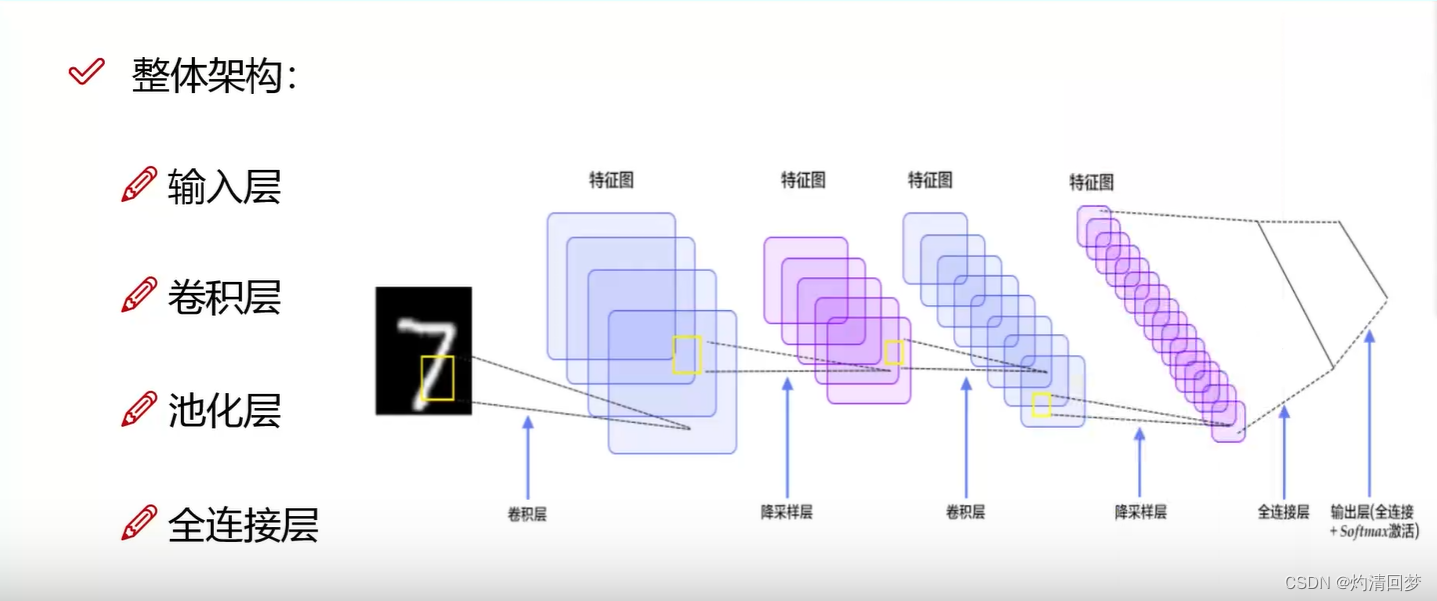
卷积层:提取特征池化层:压缩特征这个只演示了一层每个通道各自提取(R,G,B三个通道),整合(三层结果相加)padding是为了让边界点利用次数更多,padding = 1是边界填充一圈0(为什么添加0呢,因为0不会对原结果造成影响)卷积核个数决定得多少个特征图,10个卷积核就是10个特征图maxpool最大池化是选择最大的权重,因为其是最好的特征,就没必要平均池化了(为什么要将最好的特征给平均了
目标检测中的fine-tuning是指在已经训练好的模型基础上,通过在新的数据集上进行微调,以提高模型在新数据集上的性能。通常情况下,fine-tuning是在一个预训练模型的基础上进行的,这个预训练模型通常是在大规模数据集上进行训练的,如ImageNet。目标检测中,ground truth指的是真实的目标位置和类别信息,通常由人工标注或者其他可靠的方法得到。mAP越高,说明算法在检测目标方面的

此外,Adagrad算法还可以有效地处理稀疏数据,因为它可以对每个参数的历史梯度进行累加,从而更好地控制梯度的大小。这样可以使得梯度较大的参数的学习率较小,梯度较小的参数的学习率较大,从而更好地优化模型。在每次迭代中,Adam算法计算每个参数的梯度和历史梯度信息,并使用这些信息来更新每个参数的值。动量项可以帮助算法跳出局部最优解的原因是,它可以在梯度下降过程中增加模型参数更新的惯性,使得模型参数在
ONNX格式可以将深度学习模型从一个框架转换到另一个框架,从而使得不同的框架可以共享模型,加速模型的开发和部署。通过验证结果报告,可以评估模型的性能,优化模型的参数和超参数,提高模型的准确率和泛化能力。export.py是YOLOv5中的一个Python脚本,用于将训练好的模型导出为ONNX格式或TorchScript格式,以便在其他平台上进行推理。在使用YOLOv5进行目标检测时,可以加载这个预

ONNX格式可以将深度学习模型从一个框架转换到另一个框架,从而使得不同的框架可以共享模型,加速模型的开发和部署。通过验证结果报告,可以评估模型的性能,优化模型的参数和超参数,提高模型的准确率和泛化能力。export.py是YOLOv5中的一个Python脚本,用于将训练好的模型导出为ONNX格式或TorchScript格式,以便在其他平台上进行推理。在使用YOLOv5进行目标检测时,可以加载这个预
