- @weixin_71288092
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
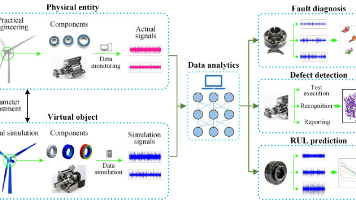
健康度(HI)是故障诊断与寿命预测领域的核心指标,通过量化设备退化状态(0-1或百分比)支持剩余使用寿命(RUL)预测。其构建方法包括数据驱动(深度学习、特征工程)、模型驱动(Wiener过程)及混合方法。应用场景涵盖工业设备预测性维护,通过健康度曲线划分设备健康阶段并外推RUL。当前面临小数据、复杂工况、不确定性量化等挑战,未来将结合数字孪生和可解释AI提升预测精度。该领域发展对优化设备维护策略
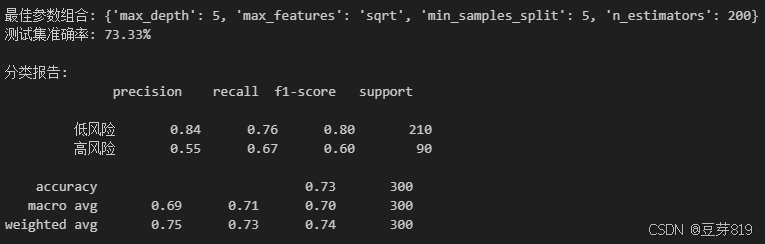
这是一个基于随机森林算法的德国信用风险评估项目,主要目的是构建一个机器学习模型来评估德国客户的信用风险,帮助金融机构判断客户是否为高风险客户。
Vision Transformer(ViT)是一种将Transformer模型应用于计算机视觉任务的创新方法,由Google Research团队在2020年提出。它打破了传统卷积神经网络(CNN)在图像处理中的主导地位,通过全局注意力机制直接建模图像块(patches)之间的关系,尤其在大规模数据集上表现出色。

上采样(Upsampling)是深度学习中的一种操作,用于将低分辨率的特征图(或数据)恢复到更高的分辨率,目的是恢复细节信息或匹配目标尺寸。它的核心是“逆向放大”,但并非简单的像素复制,而是通过算法生成新数据。
PyTorch 是一个基于 Python 的开源机器学习框架,由 Facebook 的 AI 研究团队(现 Meta AI)于 2016 年推出。它专为深度学习设计,但也可用于传统的机器学习任务。PyTorch 的核心优势在于灵活性、动态计算图和易用性,使其成为学术界和工业界广泛使用的工具。
本项目实现了一个完整的机器学习项目,包含数据加载 → 数据分析 → 模型训练 → 结果评估 → 可视化展示的完整流程。最终目标是预测混凝土的抗压强度。

data_dir是一个变量,用于存储数据集的根目录路径。表示当前工作目录下的文件夹。./是相对路径的表示方式,代表当前目录。train_dir是一个变量,用于存储训练集数据的目录路径。通过字符串拼接的方式,将数据集根目录data_dir和'/train'连接起来,得到训练集所在的完整路径。通常在深度学习项目里,训练集数据会存放在根目录下的train文件夹中。valid_dir是一个变量,用于存储验
算法设计+工程实现+业务洞察

神经元通过加权求和(权重决定特征重要性)、偏置(调整激活阈值)和激活函数(引入非线性)处理输入信号。多层感知机通过堆叠隐藏层实现复杂函数拟合,但参数量爆炸问题限制了其在图像等高维数据的应用。Xavier/He初始化根据激活函数特性调整权重范围,避免梯度爆炸或消失。模型压缩(如知识蒸馏、量化)和架构搜索(NAS)推动端侧部署。对每层输入分布标准化,加速训练收敛,同时具备轻微正则化效果。CLIP、DA
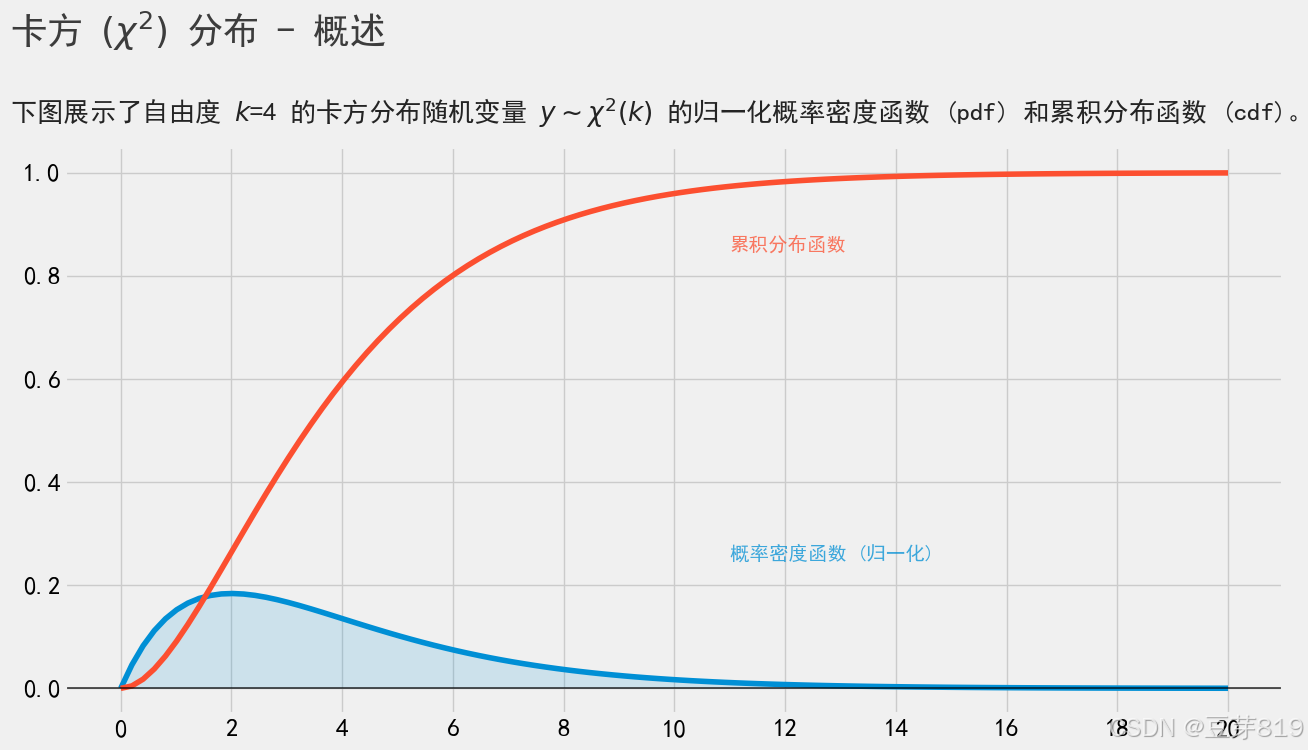
本文将介绍人工智能必备数学基础之统计分析,通过详细的Python代码,在学习相关概率分布的同时,为Python语言夯实基础,内容持续更新中