




- @weixin_67868534
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
谷歌DeepMind于2025年8月推出AI图像生成模型Gemini2.5FlashImage(代号NanoBanana),突破性地解决了图像一致性、精准编辑等核心痛点。该模型具备角色特征稳定保持、自然语言指令精确修改、多图智能融合等功能,以每张图约0.039美元的低成本提供服务。其技术突破已应用于品牌营销、创意设计等领域,并引发行业应用集成热潮。谷歌同时设置了安全防护机制应对潜在风险,推动AI图

LangGraph是LangChain团队开源的图结构工作流编排框架,通过"节点+边+全局状态"的三元组合,解决复杂场景下的流程控制问题。它将执行逻辑封装为节点,用边定义流转规则(顺序/条件/循环),以全局状态实现数据共享,支持动态决策、多角色协同等需求。相比传统线性工作流,LangGraph具有四大优势:可视化编排替代硬编码、全局状态管理消除数据孤岛、支持循环迭代优化、规范多
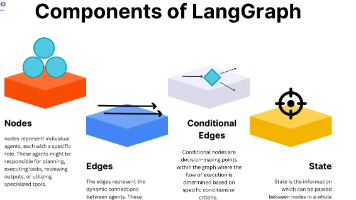
CrewAI与LangGraph是两种多智能体系统架构,定位与设计差异显著。CrewAI以角色驱动为核心,模拟人类团队协作,通过自然语言对话实现智能体间的自主沟通与任务分配,适合快速原型开发及高响应场景(如客服)。LangGraph则基于图结构,强调流程控制与状态管理,支持复杂分支与循环逻辑,适用于需精确规则和持久化状态的场景(如审批流程)。两者互补性强,可结合使用:LangGraph管理全局流程

OpenClaw 命令速查摘要

OpenClaw 命令速查摘要
NSFW(Not Safe For Work)是起源于2000年代初的网络警示标签,用于标记含性、暴力等不适宜公开浏览的内容。它被Reddit、X等平台用于用户警示与内容隔离,各国监管政策各异。生成式AI大幅降低NSFW内容创作门槛,带来“越狱攻击”等审核挑战,学界正探索VALOR等框架在保留创造力的同时过滤风险。NSFW的界定还涉及艺术与色情的模糊边界,以及非自愿图像传播等法律伦理问题,已成为互
NSFW(Not Safe For Work)是起源于2000年代初的网络警示标签,用于标记含性、暴力等不适宜公开浏览的内容。它被Reddit、X等平台用于用户警示与内容隔离,各国监管政策各异。生成式AI大幅降低NSFW内容创作门槛,带来“越狱攻击”等审核挑战,学界正探索VALOR等框架在保留创造力的同时过滤风险。NSFW的界定还涉及艺术与色情的模糊边界,以及非自愿图像传播等法律伦理问题,已成为互
n8n是一款开源可视化工作流自动化工具,采用节点连接方式实现应用集成。核心特点包括:完全开源自托管、支持2000+服务连接、内置AI功能、可视化与代码扩展结合。提供Docker/NPM/云服务多种部署方案,适合从简单监控到企业级AI处理的各类自动化场景。通过表达式引擎和逻辑控制可构建复杂流程,典型应用包括数据同步、定时报告、智能通知等。其公平代码分发模式与强大扩展性,使其成为连接传统系统与现代AI
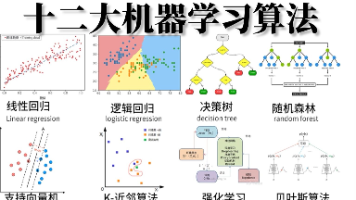
机器学习是人工智能的核心分支,通过算法让计算机从数据中自动学习规律并做出预测或决策,无需显式编程。其核心在于数据驱动,利用统计学、优化理论等跨学科方法构建数学模型,实现分类、回归、聚类等任务。根据学习范式,机器学习分为:监督学习(如线性回归、决策树),依赖标注数据训练模型;无监督学习(如K-means、PCA),挖掘无标签数据的内在结构;强化学习(如Q-learni
本文介绍一款对标专业彭博终端的开源金融工具FinceptTerminal,该项目免费开源且自带图形化界面,打破了机构级金融分析工具的高门槛壁垒。工具覆盖全球股票、外汇、加密货币、大宗商品等多类资产,提供实时行情、财经新闻聚合等功能,并集成 AI 市场情绪分析、智能选股、投顾建议等能力,同时支持技术分析、组合管理、策略回测等专业投研模块,还可扩展经济指标、实时数据推送等高级功能。安装部署简便,通过
