




- @weixin_65694308
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可第二步: 将Python函数注册到Spark SQL中注册方式一: udf对象 = sparkSession.udf.register(参数1,参数2,参数3)参数1: 【UDF函数名称】,此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范参数2: 【自定义的Python函数】,表示将哪
网络编程三要素:ip地址端口号协议ip地址作用: 每台网络设备在网络中的唯一标识(大白话就是根据ip能够找到对应网络设备)注意: 127.0.0.1和localhost一般都代表本地主机www.baidu.com就是百度服务ip地址的别名端口号:网络设备上每个程序的对应端口的编号(大白话就是根据端口号找到对应程序)端口号范围: 0-65535。

远程连接方案, 允许所有的程序员都去连接远端的测试环境, 确保大家的环境都是统一的, 避免各种环境问题的发生,而且由于是连接的远程环境, 所有在pycharm编写代码 都会自动上传到远端服务器中, 在执行代码的时候, 相当于是直接在远端环境上进行执行操作。可以配置为Base环境,也可以配置为其他的虚拟环境, 但是目前建议配置为Base环境,因为Base环境自带python包更全面一些。Standa

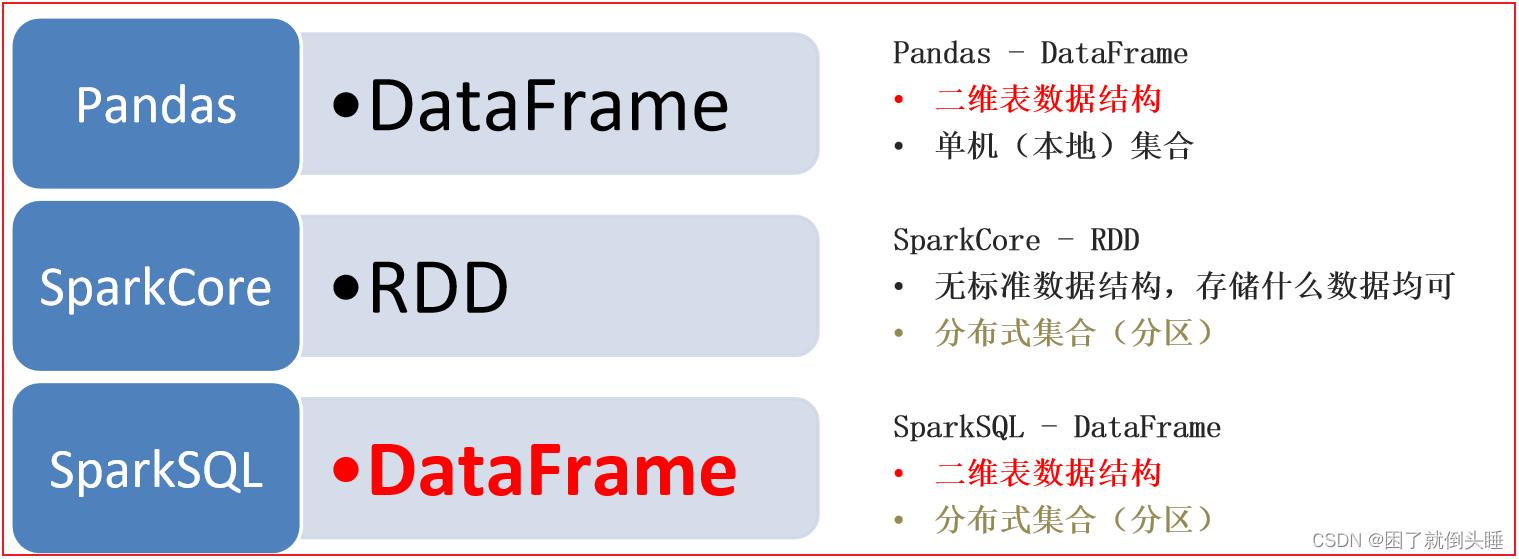
Spark SQL是Spark多种组件中其中一个,主要是用于处理大规模的【结构化数据】什么是结构化数据: 一份数据, 每一行都有固定的列, 每一列的类型都是一致的 我们将这样的数据称为结构化的数据例如: mysql的表数据1 张三 202 李四 153 王五 184 赵六 12为什么要学习Spark SQL呢?1- 会 SQL的人, 一定比会大数据的人多2- Spark SQL 既可以编写SQL语
该错误需要查看Hadoop的源代码(131行):https://gitee.com/highmoutain/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapred/FileOutputF

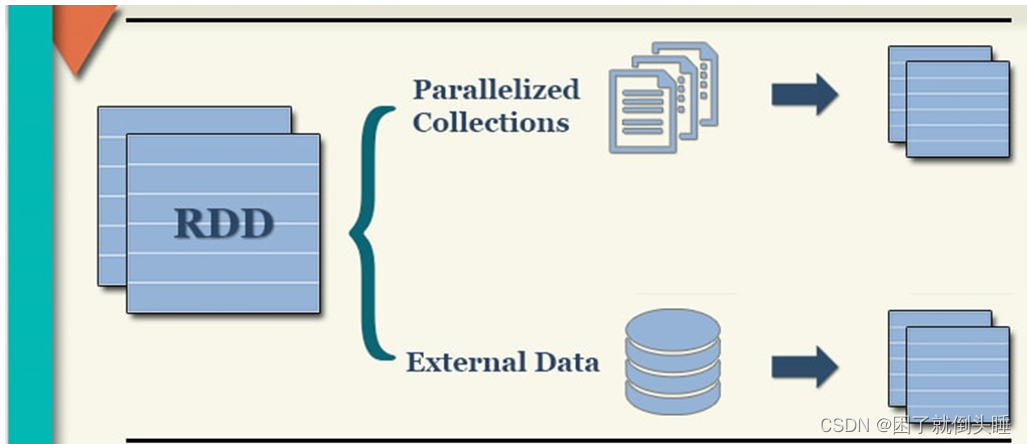
RDD:英文全称Resilient Distributed Dataset,叫做弹性分布式数据集,代表一个不可变、可分区、里面的元素可并行计算的分布式的抽象的数据集合。Resilient弹性:RDD的数据可以存储在内存或者磁盘当中,RDD的数据可以分区Distributed分布式:RDD的数据可以分布式存储,可以进行并行计算Dataset数据集:一个用于存放数据的集合。
bashrc 也是看名字就知道, 是专门用来给 bash 做初始化的比如用来初始化 bash 的设置, bash 的代码补全, bash 的别名, bash 的颜色. 以此类推也就还会有 shrc, zshrc 这样的文件存在了, 只是 bash 太常用了而已.其实看名字就能了解大概了, profile 是某个用户唯一的用来设置环境变量的地方, 因为用户可以有多个 shell 比如 bash, s
Spark天然支持集成Kafka, 基于Spark读取Kafka中的数据, 同时可以实施精准一次(仅且只会处理一次)的语义, 作为程序员, 仅需要关心如何处理消息数据即可, 结构化流会将数据读取过来, 转换为一个DataFrame的对象, DataFrame就是一个无界的DataFrame, 是一个无限增大的表。1- 放置位置一: 当spark-submit提交的运行环境为Spark集群环境的时候
标签: 是某一种用户特征的符号表示标签体系: 把用户分到多少类别里面去, 这些类是什么, 彼此之间有什么关系, 就构成了标签体系标签解决的问题: 解决描述(或命名)问题以及解决数据之间的关联。
