




- @weixin_62712120
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
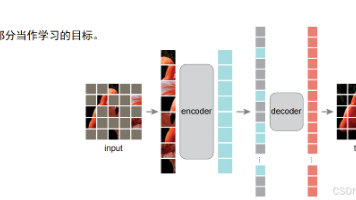
深度学习的核心,是把原始数据编码、压缩、提炼成高维特征向量,再用这些特征完成分类、生成、检测等任务。本文从有监督、无监督、自监督三大范式出发,讲解模型如何自动学习有效特征,并详细介绍 GAN、扩散模型、CycleGAN、对比学习、自编码器等经典特征学习方法,以及它们在食物分类、图像转换、风格迁移等场景的实际应用,最终带你理解:什么是好特征,以及如何让模型学到好特征。
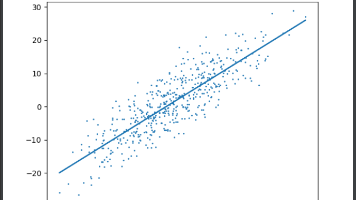
本文实现了一个简单的线性回归模型,通过PyTorch框架完成数据生成、模型训练和结果可视化。首先使用create_data函数生成500个带噪声的线性数据样本,其中权重true_w=[8.1,2,2,4],偏置true_b=1.1。然后定义data_provider函数实现批量数据加载,采用随机打乱索引的方式避免过拟合。模型训练过程包含预测函数fun、MAE损失函数maeLoss和随机梯度下降优化
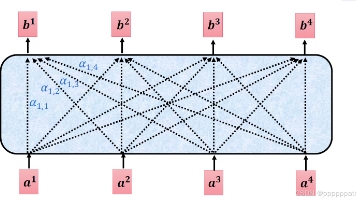
本文系统梳理了从传统文本表示到预训练模型的完整演进路线,依次讲解词嵌入、RNN、LSTM、自注意力机制、Transformer 与 BERT 模型。内容由浅入深,用通俗语言拆解核心原理与结构,包含直观图解与关键公式,清晰说明各模型的优缺点、适用场景与进化逻辑。文章兼顾基础入门与实战理解,帮助读者快速掌握现代 NLP 发展脉络,适合深度学习初学者学习与复习使用。
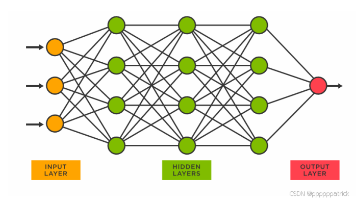
本文作为深度学习基础篇的开篇第 0 章,从 “定义模型→定义损失→优化参数” 的核心三步法出发,系统拆解了深度学习的本质逻辑。文章从神经网络的输入输出形式入手,逐步过渡到从单神经元标量运算到复杂网络张量运算的升级过程,重点讲解了张量维度定义、核心匹配规则与运算法则,帮助读者建立从 “黑盒子” 到可理解的深度学习认知框架,为后续激活函数、卷积神经网络等进阶内容打下坚实基础。
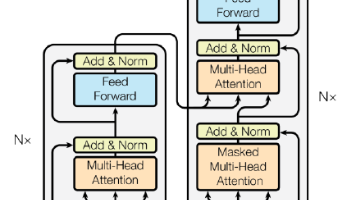
本文从 Transformer 演进切入,讲解生成式大语言模型核心原理。大模型本质是自回归文字接龙,依托 Decoder-Only 架构与缩放定律,GPT 路线成为主流。模型训练需经过预训练、SFT 监督微调、RLHF 强化学习三步。以 DeepSeek 为代表的新一代模型,通过MoE 混合专家实现稀疏激活,在提升参数量的同时大幅降低计算量;用MLA压缩 KV Cache 缓解显存压力。此外,Ro
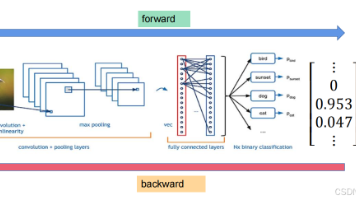
本文从深度学习中回归任务与分类任务的核心区别入手,详细讲解了如何从全连接网络过渡到处理图像的卷积神经网络。文章先介绍图像在神经网络中的表示形式(通道、高度、宽度),再深入解释卷积、卷积核、感受野、步长、填充、池化等关键概念,并给出卷积输出尺寸与参数量的计算公式与实战例题。同时针对初学者常见疑问,清晰区分卷积与池化的不同作用,最后手把手带大家搭建一个简易 CNN 结构,完整展示从3×224×224图
本文从 Transformer 演进切入,讲解生成式大语言模型核心原理。大模型本质是自回归文字接龙,依托 Decoder-Only 架构与缩放定律,GPT 路线成为主流。模型训练需经过预训练、SFT 监督微调、RLHF 强化学习三步。以 DeepSeek 为代表的新一代模型,通过MoE 混合专家实现稀疏激活,在提升参数量的同时大幅降低计算量;用MLA压缩 KV Cache 缓解显存压力。此外,Ro
本文介绍了一个基于BART模型的医学影像报告自动生成系统。该系统通过深度学习技术,将CT影像的结构化编码序列转换为自然语言的医学诊断报告,旨在解决传统医学报告撰写效率低、标准化不足等问题。文章详细解析了项目的数据格式、预处理流程和核心技术选型,重点阐述了如何利用序列到序列模型实现从医学编码到专业报告的智能生成。系统采用预训练的中文BART模型进行微调,通过编码器-解码器架构理解医学影像特征并生成符
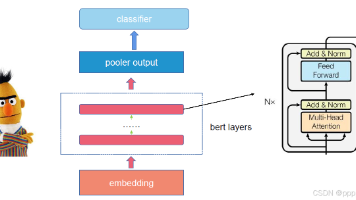
本文针对酒店评价文本开展情感分类实战,采用 bert-base-chinese 预训练模型构建分类网络,通过 PyTorch 实现数据预处理、模型微调、训练验证与模型保存全流程。文章详细解释各模块作用与关键代码细节,包括 BERT 表征、分类头输出、损失计算与准确率评估,形成一套可直接运行、易于扩展的中文情感分析工程范式。
本文从深度学习中回归任务与分类任务的核心区别入手,详细讲解了如何从全连接网络过渡到处理图像的卷积神经网络。文章先介绍图像在神经网络中的表示形式(通道、高度、宽度),再深入解释卷积、卷积核、感受野、步长、填充、池化等关键概念,并给出卷积输出尺寸与参数量的计算公式与实战例题。同时针对初学者常见疑问,清晰区分卷积与池化的不同作用,最后手把手带大家搭建一个简易 CNN 结构,完整展示从3×224×224图