




- @weixin_61623830
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
时选择的路径)4.查看系统变量中的Path是否有v12.2\bin,若没有则添加正确路径;若错误则修改成正确路径(路径为。

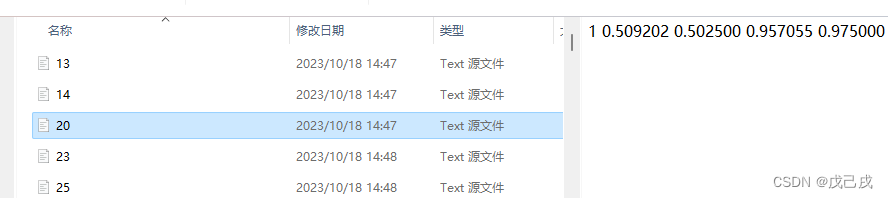
问题:深度学习时,当需要整体修改类型编号时,例如两数据1是car,和1是truck,现想合并数据,那就要挨个打开txt文件修改第一列的类型数字,(这样才能类型不冲突)手动修改是不可能的,唯有脚本释人心。不只强势替换,可以筛查替换。
前言论文地址: https://arxiv.org/abs/1911.09070.PyTorch实现: https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch.贡献:提出一种全新的特征融合方法:重复加权双向特征金字塔网络 BiFPN;提出一种复合的缩放方法(EfficientNet方法):统一缩放 分辨率、深度、宽度、特征融合网络、b

【代码】语义分割:标注json文件转mask。

于是又卸载了该插件和相关引用的插件如(扩展“Auto-Using for C#”和“Microsoft.AspNetCore.Razor.VSCode.BlazorWasmDebuggingExtension”依赖于它),安装的时候发现,控制台会输出。排除其他问题后重启电脑(排除了.netcore,sdk,runtime相关之后,只有可能是C#环境有问题),对应vscode的C#扩展文件。卸载vs

yolov5 中不是只使用默认锚定框,在开始训练之前会对数据集中标注信息进行核查,计算此数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于或等于0.98,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。其中 thr 是指 数据集中标注框宽高比最大阈值,默认是使用 超参文件 hyp.scratch.yaml 中的 “anchor_t” 参数值。