- @weixin_57974242
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
上执行 Docker 命令,因为容器本身没有权限直接重启自己。只能联系宿主机那边给重启一下容器。尚未以systemd作为初始系统启动。检查方法:ps -p 1 -o comm=今天用服务器时又突然报错cuda不可用,输入nvidia-smi检查,报错如题。想重启 Docker 容器中,通常需要在。尝试 exit 退出容器再进入:无效。等字样,那么是在某种虚拟化环境中。,那么说明没有虚拟化。但是文中

这意味着系统中安装的驱动包与正在使用的内核模块版本不匹配,导致了 GPU 驱动问题。可以看到目前系统安装的 NVIDIA 驱动包版本是。,但是内核模块显示的版本是。

原来的一些比较好的方法,不论是FlowNet2还是PWCNet,网络所消耗的算力都不小。FlowNet2需要级联encoder-decoder结构以达到SOTA;而PWCNet使用了feature pyramid使得网络轻量,但在不同分辨率解码光流时都需要使用不同的Denset block,参数量也不少。而这篇文章提出IRR方法,使得模型参数量大大减少,主要原因在于IRR这种训练方法使得每一个mo

通过调整风格编码或其他控制参数,可以对生成的姿势序列进行精确的控制,以满足特定的音乐风格要求。通过使用稳定扩散,可以根据音频特征来引导网络生成相应的姿势,并确保姿势序列与音频的节奏、情感或其他特征相匹配。表情动画生成:结合人脸姿势和表情建模以及表情特征,生成具有逼真和连贯表情的动画序列。姿势合成和转换:根据生成的姿势序列,可以进行后处理和优化,确保流畅和连贯性。可控性参数:提供一些可调整的参数,如

翻墙下载实在太慢了,还不稳定,就把常用的一些checkpoint传网盘了,需要自取~
① 基于梯度的方法(微分法)利用时变图像灰度的时空微分(时空梯度函数)来计算像素的速度矢量。② 基于匹配的方法有基于特征和基于区域两种。基于特征的方法是对目标特征进行定位和跟踪,目标大的运动和亮度具有更好的鲁棒性。基于区域的方法是对类似的区域进行定位,通过相似区域的位移计算光流。③ 基于能量的方法(频率)要获得均匀光流场的准确的速度估计,必须对输入图像进行时空滤波处理,即对时间和空间进行整合。④
这意味着系统中安装的驱动包与正在使用的内核模块版本不匹配,导致了 GPU 驱动问题。可以看到目前系统安装的 NVIDIA 驱动包版本是。,但是内核模块显示的版本是。
上执行 Docker 命令,因为容器本身没有权限直接重启自己。只能联系宿主机那边给重启一下容器。尚未以systemd作为初始系统启动。检查方法:ps -p 1 -o comm=今天用服务器时又突然报错cuda不可用,输入nvidia-smi检查,报错如题。想重启 Docker 容器中,通常需要在。尝试 exit 退出容器再进入:无效。等字样,那么是在某种虚拟化环境中。,那么说明没有虚拟化。但是文中
关注如何让LLM直接理解视觉信号(如图像),不依赖于多模态数据集的微调。将图像看作语言实体,将图像编码为LLM词表中的离散token(单词)。设计了Vision-to-Language Tokenizer(V2L Tokenizer):通过encoder-decoder架构、LLM词表和CLIP模型将图像翻译成LLM可解释token。转换后,冻结的LLM不仅能做图像理解类任务,还能做图像去噪和修复
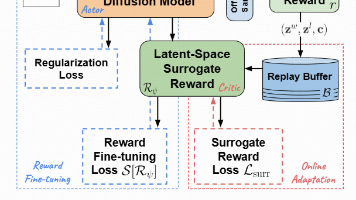
这篇论文提出了一种新的框架LaSRO,用于在潜在空间中学习可微分的替代奖励,从而有效解决了两步扩散模型的微调问题。:通过广泛的消融研究和实验,验证了LaSRO在不同奖励目标下的有效性和稳定性,优于流行的强化学习方法(如DDPO和Diffusion-DPO)。:未来的研究可以进一步探索LaSRO在其他类型的两步扩散模型中的应用,并优化其设计以提高在不同任务和奖励信号下的性能。:LaSRO的TD