




- @weixin_56462041
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
引入语法制导定义的目的:为了将语义属性关联到文法符号:为了将语义规则关联到产生式:有效地将语法和语义关联起来。为相应的语法成分设置表示语义的属性,属性的值是可以计算的。根据属性值计算的关联关系,将其分成综合属性和继承属性;根据属性文法中所含的属性将属性文法分成:S-属性文法和L-属性文法;

本文系统梳理了语言模型强化学习的几类主流优化方法,并聚焦于其核心目标、算法思路与优缺点。PPO 通过 clipping 新旧策略概率比,稳定在线策略梯度更新,但需训练价值网络,计算开销大。DPO 利用偏好对直接优化策略,无需奖励模型,但严重依赖离线数据质量,且分布偏移敏感。GRPO 在 PPO 基础上省去价值网络,通过组内相对奖励构造优势,大幅降低了计算需求,但依赖成组采样,推理成本增加。G

简单的说,该赛题的求解目标是利用数据分析将人工的鼠标轨迹和代码生成的鼠标轨迹区分开来。当决策树完全生成后,每个结点分裂所使用的特征组成的集合就是最后筛选出的特征子集。如何从数据中能够自主的学习特征,在这里我们主要介绍在深度学习中常用的三种网络结构。,将样本集划分为纯度更高的子集,而每次选择出的都是使划分效果最佳的特征,所以。不同的特征选择算法不仅对特征子集评价标准不同,有的还需要结合后续的学。是一

本文详细介绍了如何在本地服务器上部署大模型(如DeepSeek、Llama3、Qwen等),并通过接口实现外部调用。首先,从HuggingFace或魔搭网站下载模型,使用git lfs和screen确保大文件完整下载;接着,使用FastAPI封装模型推理过程,支持多GPU运行并通过CUDA_VISIBLE_DEVICES指定显卡,提供完整的app.py代码实现模型加载和接口响应;然后,通过cond

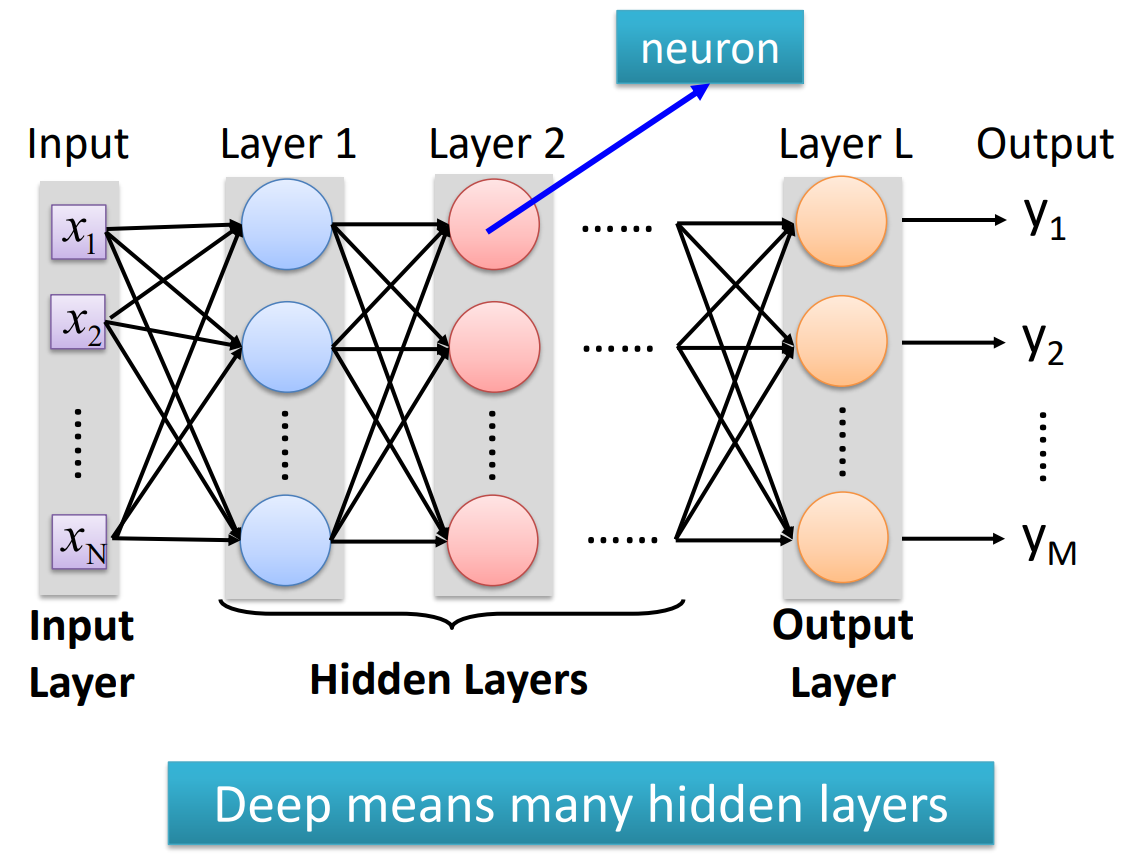
都是神经网络训练中常用的重要算法。是指将输入数据从输入层开始经过一系列的权重矩阵和激活函数的计算后,最终得到输出结果的过程。在前向传播中,神经网络会将每一层的输出作为下一层的输入,直到输出层得到最终的结果。是指在神经网络训练过程中,通过计算损失函数的梯度,将梯度从输出层开始逆向传播到输入层,以更新每一层的权重参数。在反向传播中,通过计算梯度,可以得到每个神经元的误差,进而调整其权重和偏置,以最小化
但由于启发式搜索需要抽取与问题本身有关的特征信息,而这种特征信息的抽取有时会比较困难,因此盲目搜索仍不失为一种有用的搜索策略。局部搜索算法——通往目标的路径是不相关的;目标状态本身就是解决方案,保持单一的“当前”状态,并尝试改进它。对于解决方案空间表面不太“颠簸”(即不太多局部最大值)的许多应用来说,效果很好。可以证明:如果T下降得足够慢,那么模拟退火搜索将找到概率接近1的全局最优。在某些规模太大

最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种常用的参数估计方法,用于根据已知的样本数据来估计模型的参数。它的核心思想是选择能够使观测到的数据出现的概率最大的参数作为估计值。具体来说,在最大似然估计中,我们假设样本数据来自于某个概率分布,但是该分布的参数是未知的。贝叶斯定理是根据先验概率和条件概率来计算后验概率的一种方法,可以用于分类、预测等任务。,表

成本函数(Cost)的定义可以是网络输出与目标之间的欧氏距离或交叉熵。在神经网络训练中,成本函数用于衡量神经网络的预测结果与真实标签之间的差异。成本函数的选择取决于具体的任务和网络结构。
合取范式(CNF)是一个逻辑学术语,它表示为文字的析取式的合取式,其中每个文字都是一个变量或者它的否定形式,而每个合取项都是由一个或多个文字的析取组成的,这些合取项被称为clauses。逻辑中的关键概念之一是蕴涵,它指的是两个命题之间的关系,其中一个命题逻辑上可以推导出另一个命题。蕴涵表示一个语句逻辑上跟随另一个语句而出现,即如果一个语句A蕴涵另一个语句B,那么当A为真时,B也必须为真。这种蕴涵关

本文系统梳理了语言模型强化学习的几类主流优化方法,并聚焦于其核心目标、算法思路与优缺点。PPO 通过 clipping 新旧策略概率比,稳定在线策略梯度更新,但需训练价值网络,计算开销大。DPO 利用偏好对直接优化策略,无需奖励模型,但严重依赖离线数据质量,且分布偏移敏感。GRPO 在 PPO 基础上省去价值网络,通过组内相对奖励构造优势,大幅降低了计算需求,但依赖成组采样,推理成本增加。G