- @weixin_54623031
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
朴素贝叶斯是一种分类算法,其核心思想是基于概率进行分类。特征之间相互独立。1.1 什么是朴素贝叶斯贝叶斯:指基于贝叶斯定理,利用概率统计进行分类的方法。它是机器学习中唯一纯粹依赖概率值进行分类的算法。朴素:指“特征条件独立假设”,即假设数据集中每个特征(列)之间是没有关联的,相互独立的。朴素的作用:在这个假设下,计算联合概率或条件概率时,复杂的计算过程可以简化为直接进行概率相乘,从而大大简化了模型
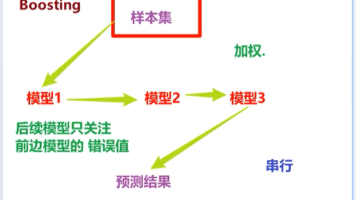
特性Bagging(如随机森林)Boosting(如AdaBoost/GBDT/XGBoost)训练方式并行串行样本采样有放回抽样(子集)全量数据关注点降低方差(防过拟合)降低偏差(提准确率)后续模型任务独立训练修正前序模型的错误典型风险欠拟合可能过拟合可能(如果太关注异常值)算法一句话概括Bagging有放回采样 + 并行训练 + 平权投票Boosting全量数据 + 串行训练 + 加权关注错误
基于资讯,以deepseek帮助解读分析,千问纠错后梳理。
基于资讯,以deepseek帮助解读分析,千问纠错后梳理。
文本挖掘已广泛应用于历史、娱乐、安全、执法等领域。随着非结构化文本数据持续增长,AI驱动的文本挖掘将更加关键。伦理问题隐私保护知识产权安全与个人自由的平衡维度数据挖掘文本挖掘输入数据结构化数据(关系数据库、数据仓库)非结构化或半结构化文本(邮件、社交媒体、网页等)数据形式行与列代表明确变量缺乏内在结构,包含自然语言目标发现模式、趋势、关系提取含义、主题、情感核心挑战多义词(词义歧义)上下文依赖句法
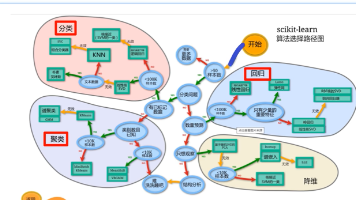
KNN算法思想:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别2.k近邻算法样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。利用k近邻算法预测电影类型。欧氏距离:对应维度差值平方和,开平方根3.K值选择k值小了,过拟合–数据量少,容易学到脏数据用较小领域中的训练实例进行预测容易受异常点影响k值减小就意味着整体模型变得复杂,容易发生过拟合k

相关概述:AI ML DL机器学习算法分类:监督学习无监督学习半监督学强化学习机器学习三要素:数据 算力 算法建模流程:KNN算法(K近邻算法):近墨者黑,近朱者赤1.人工智能三大概念AI ML DL人工智能之父:约翰麦卡锡机器学习之父:亚瑟塞缪尔2.机器学习的应用领域和发展史3.机器学习常用术语样本、特征、标签、