




- @weixin_54607024
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
连通鲁棒性作为网络理解、优化与修复的关键指标,传统上依赖于耗时且往往难以实施的仿真评估。所幸机器学习为此提供了创新解决方案,但以下挑战仍未解决:在更普适的边移除场景中的性能表现、通过攻击曲线而非直接训练来捕捉鲁棒性特征、预测任务的可扩展性以及预测能力的迁移性。本研究通过以下途径应对这些挑战:设计融合空间金字塔池化网络(SPP-net)的卷积神经网络(CNN)模型、改进现有评估指标、重构攻击模式、引
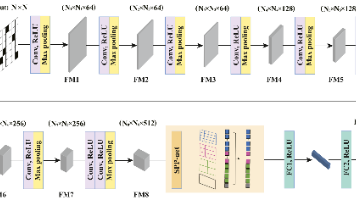
这种三阶段的划分方法是机器学习中的最佳实践,能够帮助我们建立既能在训练数据上表现良好,又能很好地泛化到新数据的模型。- 这种划分方法有助于评估模型的真实性能,避免过拟合。- 通常使用最大的数据集比例(60-80%的数据)- 这个阶段可能会多次重复,直到找到最优的模型配置。- 这个阶段只进行一次,用来评估最终模型的实际性能。- 使用测试集对最终选定的模型进行评估。- 使用验证集来评估模型的泛化能力。

这是最关键的一步。在原始神经网络中,两层神经元之间有一个权重矩阵 W,其中的元素 wab 可以是正数或负数。问题:传统的图分析工具(如最短路径算法)通常处理非负的边权重。负权重的存在会使得“距离”的概念失去意义。解决方案:将原始的连接权重 wab 转换为一个非负的距离值ωab。参数解释∣wab∣:取绝对值,因为相互作用的强度不应为负。一个很大的负权重和一个很大的正权重,都表示两个神经元之间有
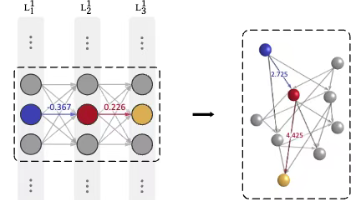
过训练指的是在训练语言模型时,使用的训练数据量(Token数量)超过了在给定计算预算下为实现最低验证损失所推荐的“计算最优”数据量。为了理解这一点,我们首先需要了解“计算最优”训练(Chinchilla 最优)核心思想:由DeepMind的Chinchilla论文提出。对于固定的计算预算(以FLOPs衡量),存在一个模型参数规模(N)和训练数据量(D)的最佳配比,使得模型的验证损失最低。结论:Ch
编码器用于对多层网络进行表示学习,捕捉层内和层间的结构信息。包含:① 节点级层间注意力机制:动态计算不同层之间节点的影响力权重。(box1)② 层内图卷积网络:聚合每层内邻居节点的信息。解码器基于编码器输出的节点嵌入和状态嵌入,计算每个节点的 Q 值(预期回报),指导节点拆除策略。包含:① 层级注意力机制:融合不同层的 Q 值,得到全局节点重要性评分。② MLP:用于计算每层内节点的 Q 值。bo
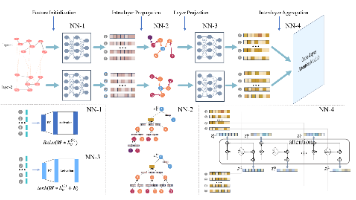
这种三阶段的划分方法是机器学习中的最佳实践,能够帮助我们建立既能在训练数据上表现良好,又能很好地泛化到新数据的模型。- 这种划分方法有助于评估模型的真实性能,避免过拟合。- 通常使用最大的数据集比例(60-80%的数据)- 这个阶段可能会多次重复,直到找到最优的模型配置。- 这个阶段只进行一次,用来评估最终模型的实际性能。- 使用测试集对最终选定的模型进行评估。- 使用验证集来评估模型的泛化能力。
Transformer 与 RNN 不同,可以比较好地并行训练。Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。Transformer 的重点是 Self-Attention 结构,其中用到的Q, K, V矩阵通过输出进行线性变换得到。
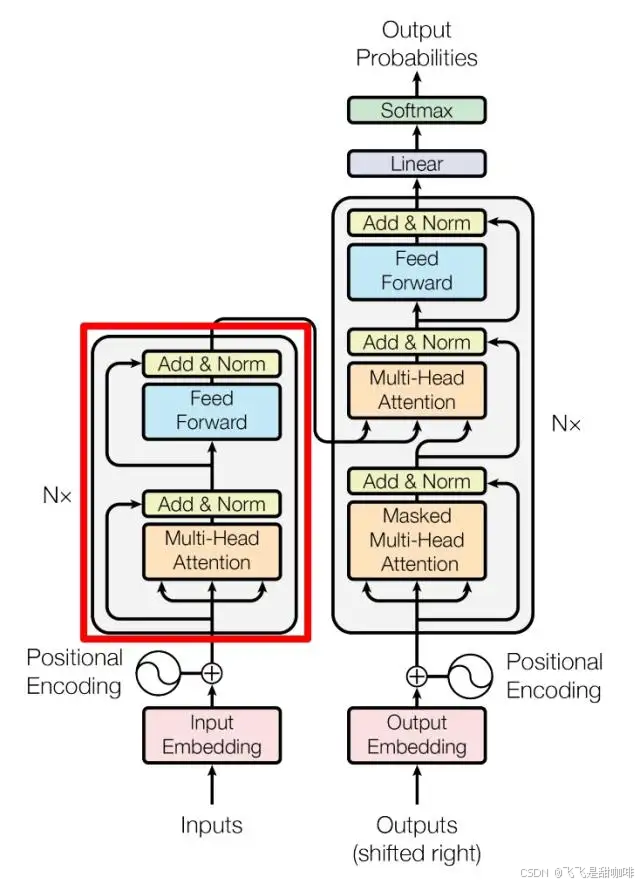
这种三阶段的划分方法是机器学习中的最佳实践,能够帮助我们建立既能在训练数据上表现良好,又能很好地泛化到新数据的模型。- 这种划分方法有助于评估模型的真实性能,避免过拟合。- 通常使用最大的数据集比例(60-80%的数据)- 这个阶段可能会多次重复,直到找到最优的模型配置。- 这个阶段只进行一次,用来评估最终模型的实际性能。- 使用测试集对最终选定的模型进行评估。- 使用验证集来评估模型的泛化能力。