




- @weixin_54605452
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生物学启发的长文本和动态任务网络架构
【摘要】Web4.0时代下,AI技术正在颠覆传统创业模式,推动"一人公司"成为新趋势。以ClaudeCode和OpenClaw为代表的AI工具,通过零门槛操作、本地化部署和智能辅助功能,使普通人无需专业技术即可完成产品开发、运营交付全流程。这些工具具备自然语言交互、长效记忆和隐私保护等特点,大幅降低创业门槛,实现个体生产力的解放。当前时代红利正转向具备认知升级能力的个体,通过轻

Liquid AI 正在通往一个更性感的商业故事:用更低的成本,做移动端和 AI PC 上的“小 GPT-4”。而走向了硬科技的另一个极端:它不在乎能不能陪用户聊天,它要在极其严苛、不许有 1% 幻觉或 NaN 崩溃的边缘物理世界里,成为那颗绝对精准、内存恒定、位精确对齐的“硬核钢铁大脑”。对于精密制造、具身智能世界模型而言,这才是真正具有颠覆性的类脑工程方法学。
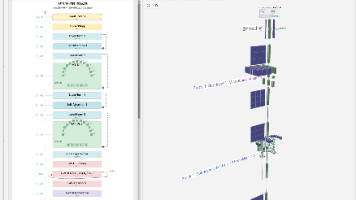
OpenClaw 凭借 “本地执行、自主干活” 引爆 AI Agent 圈,成为开源智能体代名词。但在复杂任务、长时记忆、多会话协同场景下,其原生架构瓶颈日益凸显。AwarenessClaw 基于 TypeScript 重构核心链路,在感知机制、记忆系统、执行效率上实现代际升级,本文从实战维度深度对比,告诉你为什么它更适合生产环境。
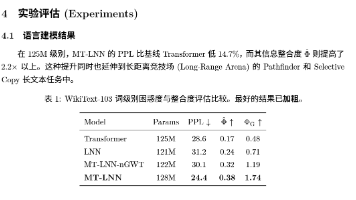
《类脑智能架构M1:边缘AI的常数内存革命》摘要 针对Transformer在边缘计算中的内存爆炸问题,本文提出基于生物微管动力学的类脑模型M1(AwareLiquid)。该架构通过13根微管通道实现恒定内存开销,采用反对称矩阵参数化确保数值稳定性,并创新性引入事件驱动机制提升能效比。M1通过时滞微分方程处理多模态异步信号,在125M参数量级下实现1.466ms/token的零抖动推理。相比传统方
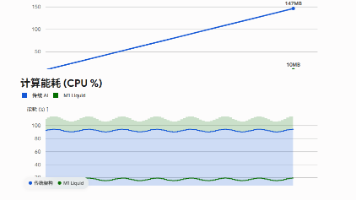
《类脑智能架构M1:边缘AI的常数内存革命》摘要 针对Transformer在边缘计算中的内存爆炸问题,本文提出基于生物微管动力学的类脑模型M1(AwareLiquid)。该架构通过13根微管通道实现恒定内存开销,采用反对称矩阵参数化确保数值稳定性,并创新性引入事件驱动机制提升能效比。M1通过时滞微分方程处理多模态异步信号,在125M参数量级下实现1.466ms/token的零抖动推理。相比传统方
M1(AwareLiquid)是一款专为物理推演、具身智能和工业控制设计的创新模型,突破传统Transformer架构限制,实现常数内存消耗(O(1))和微秒级延迟。其核心创新包括:微管启发的液态架构、全局工作空间竞争路由、李雅普诺夫稳态防爆系统,以及事件驱动的动态唤醒机制。M1在工业场景中表现卓越,支持高精度伺服控制、无人机决策和低功耗边缘计算,并实现实验室与端侧设备的位精确对齐,延迟低至1.4
M1(AwareLiquid)是一款专为物理推演、具身智能和工业控制设计的创新模型,突破传统Transformer架构限制,实现常数内存消耗(O(1))和微秒级延迟。其核心创新包括:微管启发的液态架构、全局工作空间竞争路由、李雅普诺夫稳态防爆系统,以及事件驱动的动态唤醒机制。M1在工业场景中表现卓越,支持高精度伺服控制、无人机决策和低功耗边缘计算,并实现实验室与端侧设备的位精确对齐,延迟低至1.4
在通用人工智能(AGI)的道路上,或许靠着暴力堆叠显存能暂时领先,但遵循人类神经科学规律、拥有极致算力性价比的类脑架构,才是走向最终智能的必经之路。

在通用大语言模型(LLM)的语境里,“幻觉”指的是模型在一本正经地胡说八道(比如编造历史事件);“准确度”指的是做多项选择题(MMLU)的得分。在这条赛道上,125M 的模型是不可能打赢千亿参数模型的。但既然 M1 (AwareLiquid) 的定位是“工业级高精准物理世界模型”,我们就必须重新定义跑分标准。指的是模型在推演连续时间动作时,(比如预测一个正在自由落体的苹果突然拐弯飞上天,或者在计算