




- @weixin_53036073
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
用pycharm自带的opencv库安装又快又好,试过在terminal中安装opencv,下载慢不说还用不了,在设置里面下载opencv-python 和opencv-contrib-python,不到两分钟你的opencv就配置好啦,目前使用来看没有问题。下载opencv-contrib-python。下载opencv-python。

在Python中编写一个脚本,在Visual Studio中运行,并处理文件夹中不同格式的照片(如。我所需要的数据集网上没有,只能自己搜寻,搜集了1000张左右,格式和名字、大小并不统一。(Python Imaging Library)库,结合。库来批量处理这些图像文件。以下是示例代码,可以将所有。每隔一秒截取视频并保存为图片,可以使用。, 等),按顺序将它们重命名为从。使用 Python 的。

首先,上一篇讲述了python3.9.0的安装。所需的python3.9已经安装好了,还需要安装pytorch2.0.1和CUDA11.8.(注意torch版本要和CUDA对应)简直了!这篇文章和我所要搭建的环境一模一样。但是第一步就发现了问题:安装版本高于系统运行版本电脑上还有其他人的数据集,系统的CUDA版本是11.3,但现在环境yolov10需要配置的版本为11.8。chatgpt给出的解决
在训练数据集时遇到了驱动程序和cuda-11.8版本不匹配导致训练失败,检查驱动程序显示没有,重新下载驱动程序发现电脑上的驱动程序自动下载安装的话只能到384,所以这篇文章主要是教大家如何手动安装和配置NVIDIA-550版本。手动安装高版本的 NVIDIA 驱动程序(如 550版本)到电脑上通常可以正常使用,但需要确保安装过程正确且与现有系统和 CUDA 版本兼容。以下是官网查询到的版本兼容性列
我使用的是YOLO格式的数据集,没有使用过DEIM环境的小伙伴们可以往下看。环境要求:CUDA 12.4GPU 推荐 >= 32G所以在选择GPU的时候要注意cuda版本。我选择的是vGPU-32GB(32GB),现在GPU的cuda版本一般都挺高的。
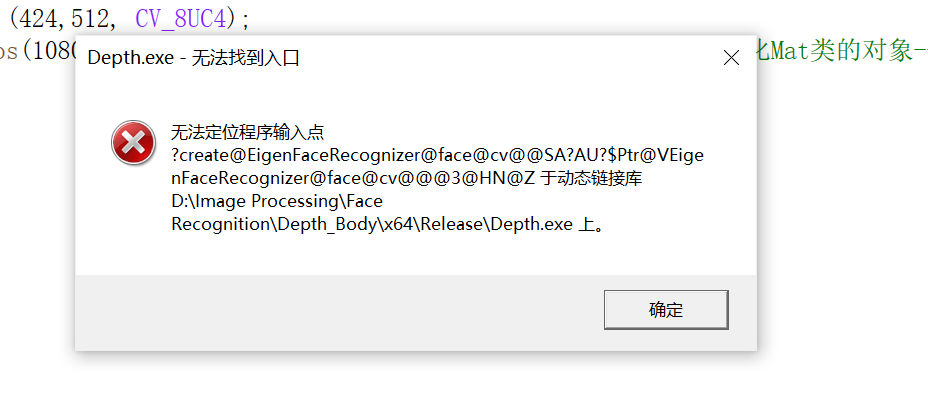
有没有大神能够给个解决方案,急!
在Python中编写一个脚本,在Visual Studio中运行,并处理文件夹中不同格式的照片(如。我所需要的数据集网上没有,只能自己搜寻,搜集了1000张左右,格式和名字、大小并不统一。(Python Imaging Library)库,结合。库来批量处理这些图像文件。以下是示例代码,可以将所有。每隔一秒截取视频并保存为图片,可以使用。, 等),按顺序将它们重命名为从。使用 Python 的。
有些大学或研究机构也会提供食物相关的公开数据集。可以通过学校网站或Google Scholar进行搜索。: 许多开发者会在GitHub上分享他们的工作和数据集。你可以搜索与xx相关的项目,查看其中是否包含数据集。提供了大量用户上传的各种类型数据集。你可以在其中搜索与xx相关的关键词。是一个专门用来搜索公开数据集的工具。你可以在其中搜索你需要的xx数据集。你可以在这些平台上搜索具体的xx相关数据集,
yolov10在训练数据集之前所需要的环境配置请看前三篇文章:我使用的是现有的数据集,没有数据集的伙伴们根据上面这篇博文去建立自己的数据集哈。YOLOv10 默认使用的是 YOLO 格式的标签文件(.txt文件)。如果你的标签文件是 XML 格式(如 Pascal VOC 格式),你需要先将它们转换为 YOLO 格式。1. 转换 XML 文件为 YOLO 格式首先,创建一个 Python 脚本,将
很有可能是更改了ultralytics文件夹中的某一个文件导致的,我以为是因为我更新了几个模块导致的出错,尝试了很多方法比如关掉详细输出修改模块以及将环境恢复至原始状态,但是都没有解决。其实以前运行也遇到过类似问题,换了我师姐给的ultralytics文件夹后就解决了,也不知道啥原理。所以这次还是把现在的ultralytics文件夹给删除,换成最初的ultralytics文件夹,再运行就正常了!所