- @weixin_51756038
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
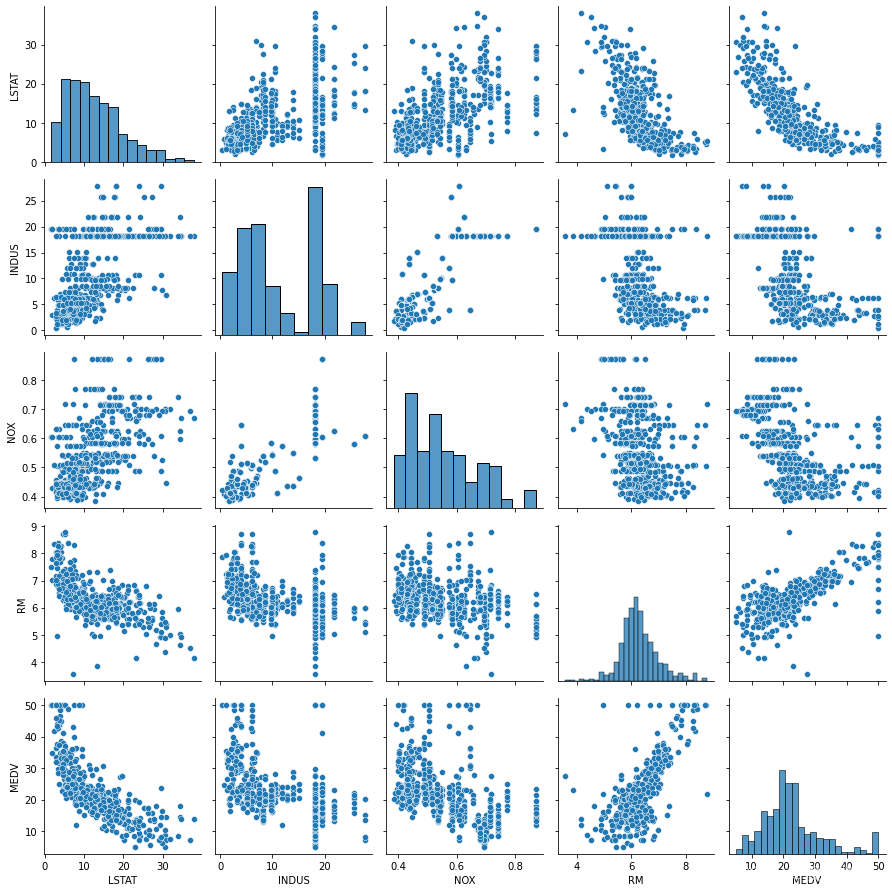
随机森林是多个回归决策树的集合。相对于回归决策树,随机森林有以下几个优点:(1)由于建立了多个决策树,因此随机森林可以降低单个决策树异常值带来的影响,预测结果更准确。(2)回归决策树采用了训练集的所有特征和样本,而随机森林采用训练集的部分特征构建多个决策树,相对于决策树回归降低了过拟合的可能性。相对于回归决策树,随机森林存在以下缺点:(1)随机森林的计算量相对于决策树更大。(2)由于采用训练集的部
解密信息是隐藏信息的逆过程,其过程比较简单,即提取载体文件中蓝色像素值为奇数的像素点,将空白图像中的这些像素点对应的位置赋予统一着色。信息隐藏是不让预期接收者之外的任何人知晓信息的传递事件或着信息的内容,文件相对隐秘文件的大小越大,隐藏后者就越加容易,因此,数字图像在互联网和其他传媒上被广泛用于隐藏信息。# 文本的位置在坐标(100,300),使用字体cv2.FONT_HERSHEY_PLAIN,
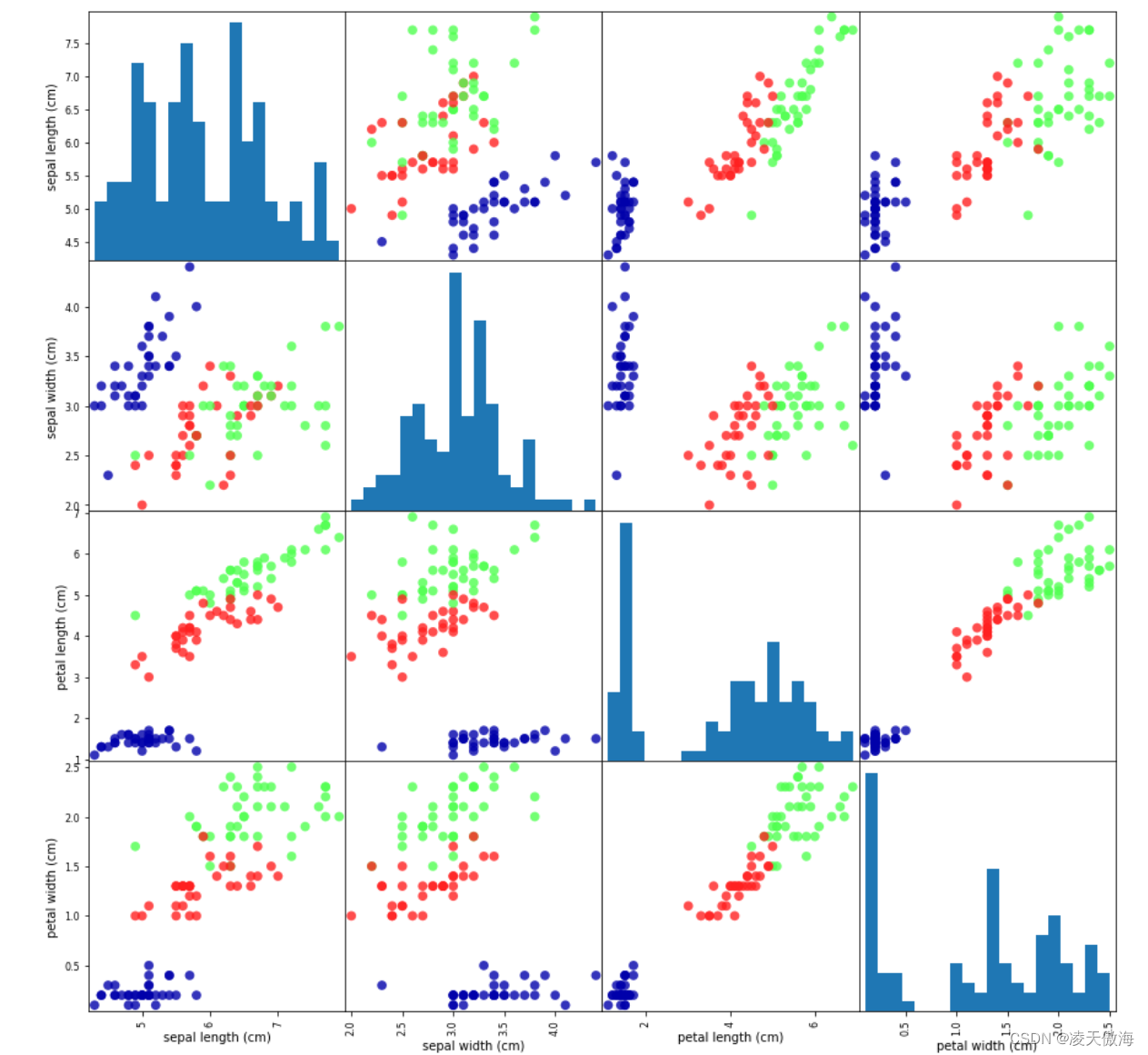
为了判断未知样本的类别,已所有已知类别的样本作为参照,计算未知样本与已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(Majority-Voting),将未知样本与K个最近邻样本中所属类别占比较多的归为一类。其中,K表示要选取的最近邻样本的实例的个数,可以根据实际情况进行选择。当样本不平衡时,即一个类的样本数量很大,而其它类样本数量很小时,有可能导致当输入一个新
随机森林是多个回归决策树的集合。相对于回归决策树,随机森林有以下几个优点:(1)由于建立了多个决策树,因此随机森林可以降低单个决策树异常值带来的影响,预测结果更准确。(2)回归决策树采用了训练集的所有特征和样本,而随机森林采用训练集的部分特征构建多个决策树,相对于决策树回归降低了过拟合的可能性。相对于回归决策树,随机森林存在以下缺点:(1)随机森林的计算量相对于决策树更大。(2)由于采用训练集的部
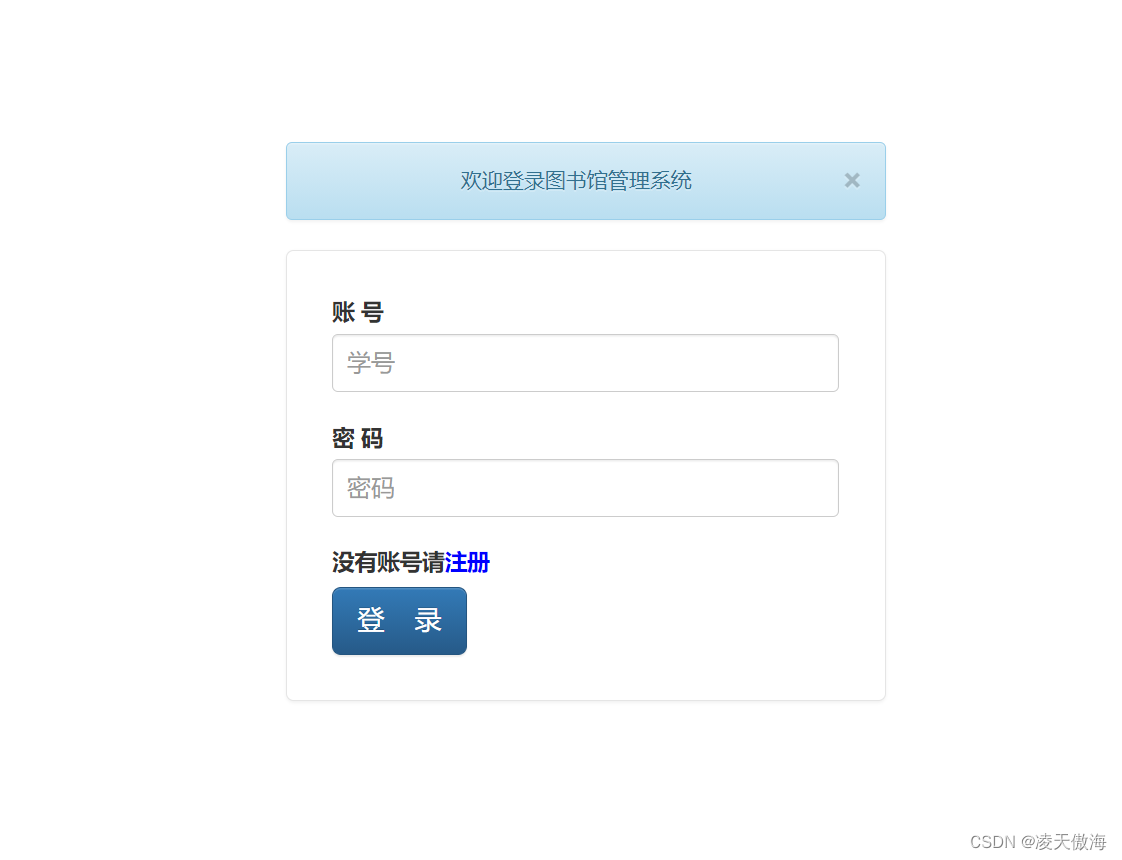
这是一个适合学生的JavaWeb大作业,包含管理员登陆、用户登陆、图书增删改查、读者增删改查、图书借阅及归还等。