




- @weixin_50569789
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这个优化问题可以通过多种方法求解,包括但不限于梯度下降法、交替最小二乘法(ALS)、凸优化算法等。选择哪种方法取决于具体的问题设置和对计算效率的要求。自我表达子空间图构建方法是一种用于数据分析和机器学习的技术,它通过将数据点。得到的图可用于进一步的数据分析任务,如聚类、降维、半监督学习等。得到的图可用于进一步的数据分析任务,如聚类、降维、半监督学习等。来揭示数据内部的结构。,就可以基于这些系数来构
深度子空间聚类网络(DSC-Nets)是一种创新的深度学习框架,它结合了深度学习的强大学习能力和子空间聚类的结构优势,能够在高维复杂数据中自动发现潜在的子空间结构,并在此基础上进行有效的聚类。DSC-Nets通过在神经网络的学习过程中直接优化自表达矩阵,实现了端到端的聚类学习,无需预聚类或额外的特征工程,这使得它在图像识别、生物信息学、信号处理等众多领域中具有广泛的应用前景。DSC-Nets结合了

矩阵范数正则化是一种在机器学习、统计学和优化问题中常用的技术,,并控制模型的复杂度。这种技术通过限制权重矩阵的大小,促进模型学习到更简单、更平滑的解决方案,从而提高模型的泛化能力。:首先,选择一个合适的矩阵范数来度量权重矩阵的“大小”。:在损失函数中加入与矩阵范数相关的项。例如,如果使用2-范数正则化,正则项可能是权重矩阵W的范数的λ倍(λ为正则化强度或惩罚系数),即 λ * ||W||_2。:将

鲁棒损失函数(Robust Loss Function)是在机器学习和统计模型中用于评估预测与实际观测之间差异的函数,它们的设计目的是。传统损失函数,如均方误差(MSE)或平方损失,在存在异常值时容易使模型性能下降,而鲁棒损失函数通过降低异常值的影响力来提高模型的稳定性和泛化能力。
奇异值分解(Singular Value Decomposition, SVD)是任何实数或复数矩阵的一种标准分解形式,它揭示了矩阵在某种意义下的基本结构和属性。在实际应用中,奇异值分解有着广泛的应用,比如数据压缩、降噪、推荐系统、主成分分析(PCA)、特征值近似、以及在机器学习和信号处理中的多种任务。通过保留较大的奇异值而忽略较小的奇异值,可以在减少数据维度的同时尽量保持数据的主要结构,达到数据

图正则化(Graph Regularization)是一种在机器学习和数据分析中使用的正则化技术,它。在非负矩阵分解(NMF)和其他子空间学习方法中,图正则化,从而提高学习结果的质量。下面详细介绍图正则化的基本概念、涉及的数学公式,并给出一个具体的例子。
非线性典型相关性分析(Nonlinear Canonical Correlation Analysis, NLCCA)是典型相关分析(CCA)的扩展,旨在处理数据中的非线性关系。与传统CCA仅能识别线性相关性不同,NLCCA利用神经网络等非线性模型来捕获数据间的复杂非线性结构。这种方法由Hsieh等人提出,将前馈神经网络应用于CCA中,从而能够探索更广泛的关联模式。
深度广义典型相关性分析(Deep Generalized Canonical Correlation Analysis, DGCCA)是由Adrian Benton等人提出的,它是深度典型相关分析(DCCA)的进一步拓展,旨在处理多于两个视图(数据集)的典型相关性分析问题。DGCCA结合了深度学习的强大表示能力和广义典型相关分析(GCCA)的多视图数据融合能力,允许从多个数据源中学习共享的深层表示
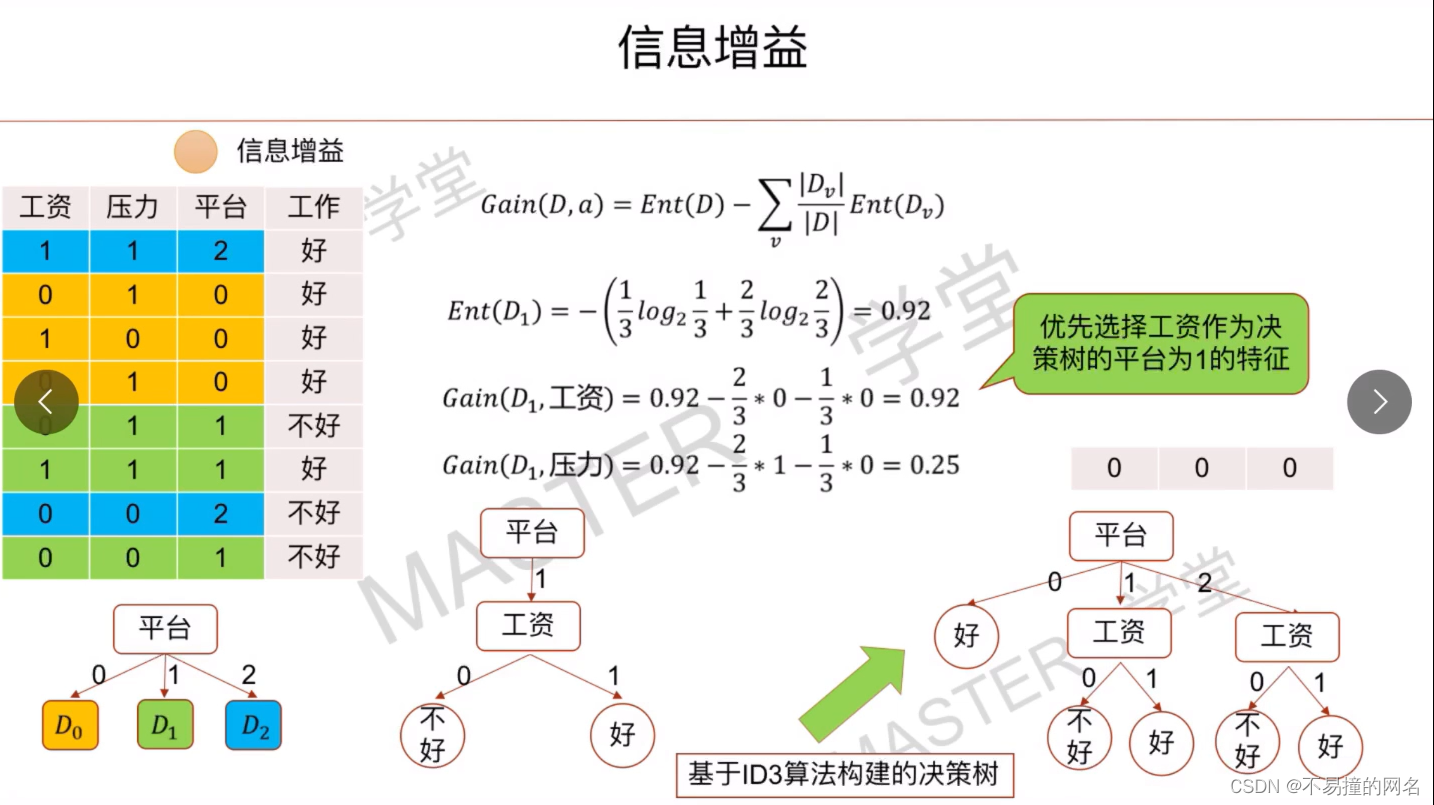
其中,log是以2为底的对数,这个选择使得信息熵的单位是比特(bit)。如果使用其他底数的对数,信息熵的单位会相应改变,但其量值的相对大小不变,因为对数函数的换底公式保证了这一点。在信息论中,熵描述了一条消息或一个信号所携带的信息量的期望值,即接收到该消息后所能消除的不确定性量。熵反映了数据集的纯度或不确定性,熵越高表示数据集中类别的分布越混杂,不确定性越大。的特征,因为这类特征能够产生更多的子集
K-medoids算法是一种分区聚类方法,用于将数据集划分为 k 个簇,其中 k 是由用户指定的簇的数量。与K-means算法不同,K-medoids算法选择实际的数据点作为。这样,K-medoids算法对异常值更加鲁棒,因为它不会受到极端值的影响。