




- @weixin_45671036
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文来自西湖大学赵世钰老师的B站视频。本节课主要介绍强化学习的基本概念。下节介绍贝尔曼公式。
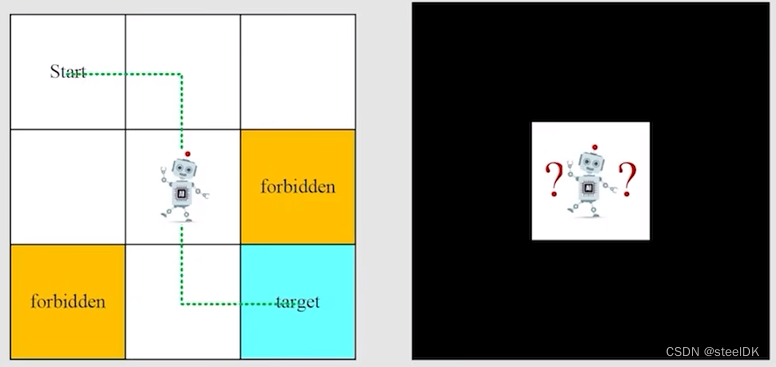
本文来自西湖大学赵世钰老师的B站视频。本文首先对要学习的内容做一个总结,没有基础的看不懂也很正常,可以先了解一下,后期学完各个章节之后再回头来看。基本概念:状态、动作、奖励、回报、episode、策略…。通过一个网格世界的例子,一个机器人找到目标区域的例子。之后会将这些概念放在Markov decision process(MDP)的框架下去介绍。
模块化:每个关注点独立模块,通过注册表解耦自动发现:工具自注册、MCP 动态发现、插件系统多层优化:PTC 减少 API 往返、并行执行、prompt 缓存、上下文压缩安全第一:路径保护、注入检测、凭证脱敏、危险命令识别可扩展:plugin 系统、MCP 集成、memory provider、context engine 插件生产就绪:~3000 测试、WAL 并发、随机抖动重试、SafeWrit
本文来自西湖大学赵世钰老师的B站视频。本文首先对要学习的内容做一个总结,没有基础的看不懂也很正常,可以先了解一下,后期学完各个章节之后再回头来看。基本概念:状态、动作、奖励、回报、episode、策略…。通过一个网格世界的例子,一个机器人找到目标区域的例子。之后会将这些概念放在Markov decision process(MDP)的框架下去介绍。
机器学习中的调参前言1、随机搜索和网格搜索2、 遗传算法前言超参数调优是机器学习中的重要一环,拿随机森林算法而言,树的个数,数的深度,剪枝参数等等需要找到最优的参数组合,超参数较少时,我们可以采用for循环遍历所有参数的可能组合,但参数很多时,最优参数的搜寻将会变得困难,本文介绍了几种常用的调参方法,后续如果学到还会更新其他调参算法。其中网格搜索法和随机搜索法采用的是sklearn中的GridSe
本文来自西湖大学赵世钰老师的B站视频。本文首先对要学习的内容做一个总结,没有基础的看不懂也很正常,可以先了解一下,后期学完各个章节之后再回头来看。基本概念:状态、动作、奖励、回报、episode、策略…。通过一个网格世界的例子,一个机器人找到目标区域的例子。之后会将这些概念放在Markov decision process(MDP)的框架下去介绍。
transformer在各个领域的应用越来越广,本文从实用的角度出发,对transformer各个模块进行讲解与实现。主要参考如下:1、论文参考:Atttion is all you need。2、NLP理论参考:预训练模型的前世今生。3、代码参考:hyunwoongko。4、代码参考:Pytorch官方文档。① 词向量就是用一个向量来表示一个单词,词向量是一个矩阵,矩阵的行数代表单词个数,列数代
机器学习中的调参前言1、随机搜索和网格搜索2、 遗传算法前言超参数调优是机器学习中的重要一环,拿随机森林算法而言,树的个数,数的深度,剪枝参数等等需要找到最优的参数组合,超参数较少时,我们可以采用for循环遍历所有参数的可能组合,但参数很多时,最优参数的搜寻将会变得困难,本文介绍了几种常用的调参方法,后续如果学到还会更新其他调参算法。其中网格搜索法和随机搜索法采用的是sklearn中的GridSe
Faster RCNN1、简介2、RCNN3、Fast-RCNN4、Faster-RCNN(1) 特征提取模块(2) RPN模块(3) RoI Pooling模块(4) RCNN模块5、总结1、简介在2014年RCNN算法问世之后,经历了众多版本的改进,但具有里程碑式意义的当属Fast RCNN与Faster RCNN算法,下面就这三个算法,按照时间顺序进行介绍。2、RCNN在RCNN出现之前,常
机器学习中的调参前言1、随机搜索和网格搜索2、 遗传算法前言超参数调优是机器学习中的重要一环,拿随机森林算法而言,树的个数,数的深度,剪枝参数等等需要找到最优的参数组合,超参数较少时,我们可以采用for循环遍历所有参数的可能组合,但参数很多时,最优参数的搜寻将会变得困难,本文介绍了几种常用的调参方法,后续如果学到还会更新其他调参算法。其中网格搜索法和随机搜索法采用的是sklearn中的GridSe