




- @weixin_45044014
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
废话不多,方法简单:module 'numpy' has no attribute 'bool'

对一个非标量值进行反向传播(backward pass),但没有提供梯度(grad)的参数。在自动微分中,我们通常对标量(单个数值)进行反向传播,计算该标量对某些输入张量的梯度。如果反向传播的输出不是标量,就需要显式地指定一个与输出同形状的张量来表示梯度。2. 通过提供梯度参数,就相当于告诉PyTorch如何对非标量输出进行反向传播。同形状的张量,并且包含了损失函数对每个元素的梯度。,因为可能不同

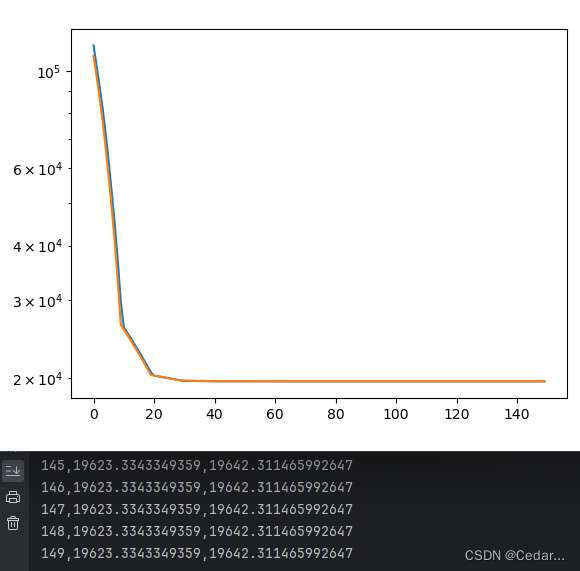
综上,图中损失曲线均收敛至20000左右,没有出现回荡现象,因此学习率不优先修改。收敛值过高,怀疑可能是局部最优了,所以优先调节batch size。但是后续发现,我这边的代码真的不太好,效果很差,所以要考虑一下是不是损失函数太简单了,方法论不太好!:学习率太大,一步前进的路程太长,会出现来回震荡的情况,但是学习率太小,收敛速度会比较慢。终端第1列:epochs,第2列:训练损失(蓝色曲线),第3
雅可比矩阵是对多元函数的导数进行梯度扩展的一种矩阵表示。对于一个具有m个输入和n个输出的函数,雅可比矩阵的大小为n×m。雅可比矩阵中的每个元素表示了输出分量相对于输入分量的偏导数。自动求导是PyTorch的一项重要功能。在计算过程中,PyTorch会为每个参与计算的张量建立一个计算图,用于记录计算过程中涉及的操作和张量之间的依赖关系,基于这个计算图,PyTorch可以根据链式法则自动计算函数的导数

废话不多,方法简单:RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x16 and 20x64)
废话不多,方法简单:AttributeError: 'numpy.ndarray' object has no attribute 'iloc'
