




- @weixin_44626085
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenAI发布GPT-5.1,突破性聚焦"人性化"而非性能指标。新版本通过两大模型升级:Instant模型实现自适应推理与精准回应,Thinking模型提升效率与表达清晰度。最引人注目的是新增8种人格预设和精细化性格调节功能,支持拖拽调整语气、简洁度等参数,AI还能主动学习用户偏好。尽管在安全性和情感依赖应对上存在挑战,但OpenAI选择坦诚公开。该更新标志着AI发展从&qu
AI编程神器实测:IDE三连挑战+SOLO模式实现零代码Web开发 Trae.ai的IDE模式可一键生成复杂网页应用,实测10秒完成万花筒相机网页,支持12段动态分镜调节。免费版提供每月10次快速模型请求,Pro版则解锁无限代码补全和GPT-5优先访问。 在IDE三连挑战中: 视觉特效:自动生成3D太阳系、粒子烟火等交互式动画 游戏开发:30分钟构建60fps弹幕游戏,含完整碰撞检测 Bug修复:
当DeepSeek V3.1以开源之姿横扫AI编程战场,Claude坚守代码圣殿,GPT-5拓展多模态边疆——这场三足鼎立的时代,没有输家,只有拿起新武器的赢家。
当谷歌Gemini 3.0 Pro还在秀多模态,DeepSeek已从模型层杀向系统层。V3.2处理复杂工作流比人类快8倍本地部署成本降至奶茶价中文长文本理解吊打国际模型兄弟们,这次国产AI真的站起来了!现在就去下载体验,感受什么叫“免费顶配”的快乐!
谷歌Chrome浏览器迎来重大更新,集成Gemini AI助手实现智能化升级。用户可通过侧边栏获得实时摘要生成、跨页操作、自动浏览网页等AI服务,还能在浏览器内直接编辑图像。不过高阶功能如Auto-browse需订阅付费服务,目前仅限美国区英文版使用。此次升级标志着浏览器从工具向AI代理平台转变,凭借Chrome全球68.35%的市场份额,或将加速AI技术普及,同时也引发对AI深度介入数字生活的思
还在为天价API费用发愁?受够了网络波动导致AI服务中断?今天,零度带你解锁真正100%本地运行的AI助手解决方案!只需跟着以下步骤操作,你的电脑将变身全能AI工作站,!
摘要 本文提出JERP框架,解决大语言模型智能体在多步交互任务中的经验复用难题。传统方法将经验使用割裂为两种独立方式:外置为提示词规则(可解释但易过时)或通过微调优化策略(全局优化但难以修正局部错误)。JERP创新性地通过同一批交互轨迹同步更新规则库和模型策略:决策时检索相关规则辅助推理,交互后轨迹同时用于组相对策略优化和基于对比的规则库迭代。实验表明,在AlfWorld和WebShop两个复杂交
摘要 本研究提出RepoRescue框架,针对开源软件仓库因生态版本漂移导致的兼容性问题,首次系统评估大语言模型智能体的全仓库兼容修复能力。通过构建包含193个Python和122个Java仓库的标准评测集,设计四层评估指标(完整补丁/仅源码修复/运行时约束/真实业务验证),发现: 商用LLM智能体展现显著修复潜力,最优系统GPT-5.2(Codex)可达51.8%仓库修复率,但存在38%-53%
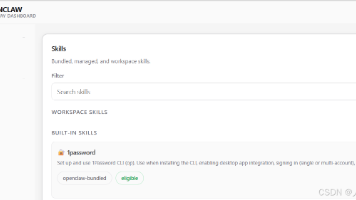
本文记录了在Linux系统上安装Homebrew包管理器的详细过程。首先创建必要的目录结构并设置权限,然后解压brew-main.zip到指定位置,移动文件并清理空目录。接着创建brew命令的软链接并配置环境变量。安装1password-cli时遇到下载锁问题,通过终止相关进程、清理缓存锁文件解决。最终成功安装并验证了Homebrew和1password-cli的功能。整个过程展示了Linux系统
本手册提供的流程是您构建企业级私有 AI Agent 的蓝图。