




- @weixin_44153630
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SpatialLM 以“低成本视频输入+高精度空间理解+开源赋能”为核心亮点,是连接现实空间与数字世界的关键技术桥梁。其轻量架构与多场景适配能力,使其成为空间智能领域的重要基础设施,推动具身智能、建筑数字化、AR/VR 等领域的技术落地与创新应用。

CAD-GPT的核心逻辑,是用多模态大模型打通“图像/文本→CAD”的链路——它没发明新模块,而是把成熟的视觉-语言模型,高效适配到了工业设计场景。后续如果用上更大的模型、更多的行业数据,说不定能实现更复杂的装配体、参数化建模。
IFC标准历经多次迭代,不同版本的schema结构、实体定义与属性规则差异较大,是BIM数据互通的主要障碍。schema动态解析:内置IFC2x3至IFC4x3的标准schema定义,支持运行时加载自定义schema(如实验性扩展版本),无需重新编译核心库,适配行业定制化需求;分层解析机制:将IFC文件解析分为语法层、实体层、关系层三步:语法层完成文件格式校验与词法分析;实体层解析IFC实体(如I

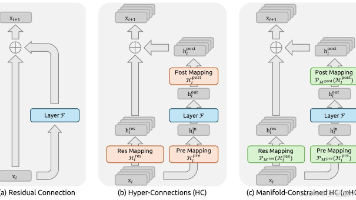
从ResNet到如今的千层大模型,残差连接始终是深度学习的"灵魂组件"。深度不再是障碍,而是力量的源泉。随着AI进入多模态、大模型时代,残差思想仍在焕发新的生命力。这场始于2015年的深度革命,至今仍在书写属于它的传奇。

这不是定论,也没有人可以准确预研。个人判断,这一次的人工智能热潮预计将持续相当长的一段时间,但具体持续时间难以预测,因为它受到技术发展、市场动态、政策环境和社会接受度等多种因素的影响。所以,如果要投身AI,需要设定目标,做好计划。

Manus 的技术壁垒并非单一技术的突破,而是“架构设计、算法研发、工程打磨、数据沉淀、成本控制”五大维度的深度融合,形成了“经验库+工程沉淀+规模效应”的三重核心壁垒,具体可概括为:架构壁垒:“规划-执行-验证”多智能体协同架构+LLM 操作系统的创新设计,实现了从“指令解析”到“结果交付”的全链路闭环,这需要长期的架构迭代与场景验证,新玩家难以快速复制。
你有没有想过,为什么大语言模型训练时总容易“掉链子”?比如训到一半损失突然飙升,或者GPU内存不够直接卡住?最近DeepSeek-AI团队提出的技术,刚好解决了这些头疼问题,今天就用3分钟带你看懂它的厉害之处。
Cybenko的论文为神经网络的理论研究开辟了道路,其核心结论——单隐层sigmoid网络是万能逼近器——至今仍是机器学习的基石之一。尽管定理存在一定局限性,但其证明思想和后续扩展(如深层网络理论)为现代深度学习的爆发提供了坚实支撑。理解该定理的核心价值,不仅在于其数学严谨性,更在于它揭示了神经网络作为“函数逼近器”的本质,以及如何通过架构设计和工程实践释放其潜力。
如果你听说过“生成式设计”“智能优化”,大概率绕不开一个关键技术——。它的灵感源自达尔文的自然选择学说,把“种群进化”的逻辑搬进计算机,用“优胜劣汰”的规则找到复杂问题的最优解。小到产品结构轻量化,大到建筑日照优化,都能看到它的身影。而一个典型的遗传算法,就像一场“人工进化”实验,核心通过5个阶段循环推进,最终让“优质基因”(最优解)脱颖而出。今天我们就用最通俗的语言,拆解这5个关键阶段。
强化学习算法种类丰富,可按学习目标(基于价值 / 基于策略 / 演员 - 评论家)、数据使用方式(在线 / 离线)、是否依赖环境模型(无模型 / 有模型)等维度分类。以下按核心逻辑梳理常见算法,并补充各算法的权重更新公式:目标是学习 “状态 - 动作价值函数”(Q 函数),通过 Q 值指导动作选择(如选 Q 值最大的动作)。Q-Learning(表格型,1989):经典无模型离线(Off-poli