




- @weixin_44120025
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
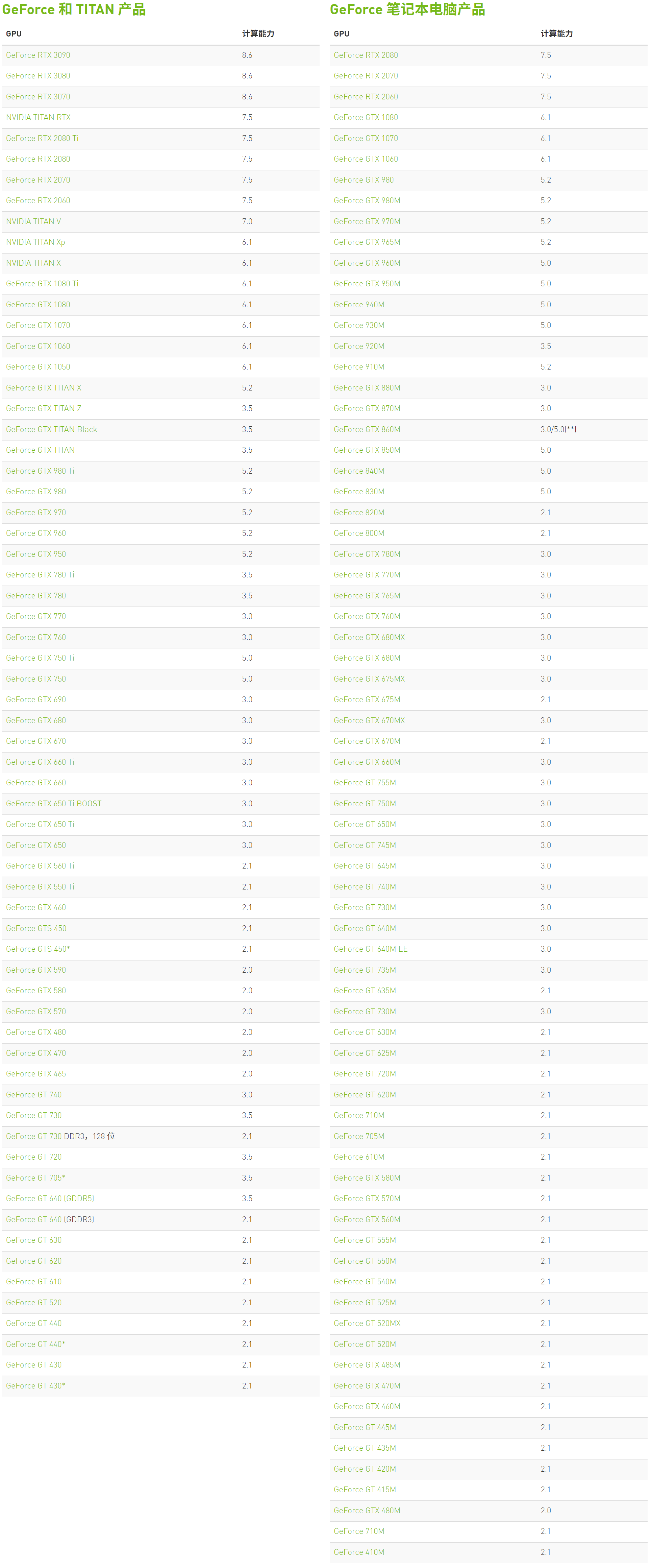
要查看显卡算力,可以直接去nvidia查看,查询链接在这里。进去后,里头会有几个可选项,如下图所示:点进去自己显卡对应的系列即可。比如大家最常用的GeForce系列显卡算力表:
在进行高运算量的网络优化之前,可以先考虑进行以下几个检验:1. Look for correct loss at chance performance 当使用少量参数进行初始化时,请确保得到了预期的损失。最好先单独检查数据损失(将正则化强度设置为零)。例如,对于具有Softmax分类器的CIFAR-10,我们期望初始损失为2.302,因为我们期望每个类的扩散概率为0.1(因为有10个类),并
在实践中,将神经网络的性能提高几个百分点的一个可靠方法是训练多个独立的模型,并在测试时平均它们的预测。随着集成中模型数量的增加,性能通常会单调地提高(尽管回报率会逐渐减少)。此外,随着集合中模型的变化越大,改进就越显著。组建一个集成模型有几种方法:1. Same model, different initializations 利用交叉验证法确定最优超参数,然后训练多个具有最优超参数集但随机
反向传播就是求梯度值,然后通过梯度下降的方式对损失函数进行迭代优化的过程。在通常情况下,直接对一个复杂的函数一步到位写出其解析导数(关于数值导数和解析导数的求法可以查看这篇博客)是不太现实的,因此,一般需要再结合链式法则(chain rule)来进行计算。下面主要讲解链式法则的应用。1. A simple example 现在,假设你已经具备了求解偏导数的基本知识。首先,先看一个简单的示例:
设输入数据的维度为N×D,其中,N是数据量,D是它们的维数。对数据矩阵X进行数据预处理有三种常见形式:1. Mean subtraction Mean subtraction是最常见的预处理形式。它通过减去数据中每个维度的平均值,将数据的每个维度都以原点为中心进行居中。其python numpy的代码为X -= np.mean(X, axis = 0)。2. Normalization N
激活函数都是非线性的,它将非线性特性引入到神经网络中,对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。 1. Sigmoid Sigmoid激活函数的数学形式为σ(x)=1/(1+e−x) ,如上图左所示。如前一节所述,它接受实数并将其“压缩”到0到1之间的范围。特别是,大负数变为0,大正数变为1。sigmoid函数在历史上被频繁使用,因为它有一个很好的解释,
神经网络被建模为在一个非循环图中连接的神经元的集合。换句话说,一些神经元的输出可以变成其他神经元的输入。循环是不允许的,因为这意味着在网络的正向传播过程中会出现无限循环。神经网络模型通常被组织成不同的神经元层,而不是由连接的神经元组成的无定形点。对于规则神经网络,最常见的层类型是全连接层(fully-connected layer),其中两个相邻层之间的神经元完全成对连接,但单层内的神经元不共
在实践中,将神经网络的性能提高几个百分点的一个可靠方法是训练多个独立的模型,并在测试时平均它们的预测。随着集成中模型数量的增加,性能通常会单调地提高(尽管回报率会逐渐减少)。此外,随着集合中模型的变化越大,改进就越显著。组建一个集成模型有几种方法:1. Same model, different initializations 利用交叉验证法确定最优超参数,然后训练多个具有最优超参数集但随机
下面介绍几种可以控制神经网络的容量以防止过拟合(overfitting)的方法:1. L2 regularization L2正则化可能是最常见的正则化形式。它可以通过直接惩罚(penalize)目标中所有参数的平方大小来实现。也就是说,对于网络中的每个权重w,我们将1/2λw2项添加到目标中,其中λ是正则化强度。使用系数1/2是为了使该项相对于参数w的梯度为λw而不是2λw。L2正则化具有
1 SGD and bells and whistles1.1 Vanilla update 最简单的更新形式是沿负梯度方向更新参数(因为梯度指示增加的方向,但我们通常希望最小化损失函数)。设参数x和梯度dx,最简单的更新形式如下:# Vanilla updatex += - learning_rate * dx 其中learning_rate是一个超参数(一个固定常数)。1.2 Moment